Spark Shuffle模块详解
Shuffle,具有某种共同特征的一类数据需要最终汇聚(aggregate)到一个计算节点上进行计算。这些数据分布在各个存储节点上并且由不同节点的计算单元处理。以最简单的Word Count为例,其中数据保存在Node1、Node2和Node3;经过处理后,这些数据最终会汇聚到Nodea、Nodeb处理。
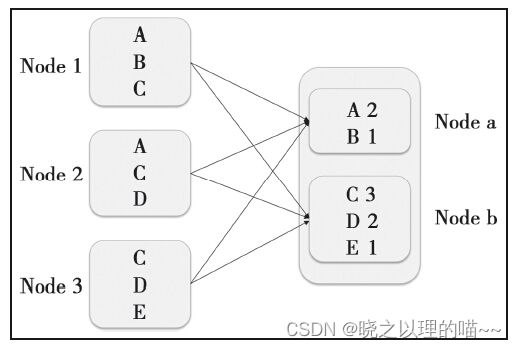
这个数据重新打乱然后汇聚到不同节点的过程就是Shuffle。但是实际上,Shuffle过程可能会非常复杂:
(1)数据量会很大,比如单位为TB或PB的数据分散到几百甚至数千、数万台机器上。
(2)为了将这个数据汇聚到正确的节点,需要将这些数据放入正确的Partition,因为数据大小已经大于节点的内存,因此这个过程中可能会发生多次硬盘续写。
(3)为了节省带宽,这个数据可能需要压缩,如何在压缩率和压缩解压时间中间做一个比较好的选择?
(4)数据需要通过网络传输,因此数据的序列化和发序列化也变得相对复杂。
一般来说,每个Task处理的数据可以完全载入内存(如果不能,可以减小每个Partition的大小),因此Task可以做到在内存中计算。除非非常复杂的计算逻辑,否则为了容错而持久化中间的数据是没有太大收益的,毕竟中间某个过程出错了可以从头开始计算。但是对于Shuffle来说,如果不持久化这个中间结果,一旦数据丢失,就需要重新计算依赖的全部RDD,因此有必要持久化这个中间结果。
一、Hash Based Shuffle Write
在很多运算场景中并不需要排序,多余的排序只能使性能变差,比如Hadoop的Map Reduce就是这么实现的,也就是Reducer拿到的数据都是已经排好序的。实际上Spark的实现很简单:每个Shuffle Map Task根据key的哈希值,计算出每个key需要写入的Partition然后将数据单独写入一个文件,这个Partition实际上就对应了下游的一个Shuffle Map Task或者Result Task。因此下游的Task在计算时会通过网络(如果该Task与上游的Shuffle Map Task运行在同一个节点上,那么此时就是一个本地的硬盘读写)读取这个文件并进行计算。
1,Basic Shuffle Writer实现解析
在Executor上执行Shuffle Map Task时,最终会调用org.apache.spark.scheduler.ShuffleMapTask的runTask。
主要逻辑:
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_<:Product2[Any, Any]]])return
writer.stop(success = true).get
(1)从SparkEnv中获得shuffleManager,就如前面提到的,Spark除了支持Hash和Sort Based Shuffle外,还支持external的Shuffle Service。用户可以通过实现几个类就可以使用自定义的Shuffle。
(2)从manager里取得Writer,在这里获得的是org.apache.spark.shuffle.hash.HashShuffleWriter。
(3)调用rdd开始运算,运算结果通过Writer进行持久化,逻辑在org.apache.spark.shuffle.hash.HashShuffleWriter#write。开始时通过org.apache.spark.Shuffle-Dependency是否定义了org.apache.spark.Aggregator来确定是否需要做Map端的聚合。然后将原始结果或者聚合后的结果通过org.apache.spark.shuffle.FileShuffleBlockManager#forMapTask的方法写入。写入完成后,会将元数据信息写入org.apache.spark.scheduler.MapStatus。然后下游的Task可以通过这个MapStatus取得需要处理的数据。
2,存在的问题
由于每个Shuffle Map Task需要为每个下游的Task创建一个单独的文件,因此文件的数量就是number(shuffle_map_task)*number(following_task)。如果Shuffle Map Task是1000,下游的Task是500,那么理论上会产生500000个文件(对于size为0的文件Spark有特殊的处理)。生产环境中Task的数量实际上会更多,因此这个简单的实现会带来以下问题:
(1)每个节点可能会同时打开多个文件,每次打开文件都会占用一定内存。假设每个Write Handler的默认需要100KB的内存,那么同时打开这些文件需要50GB的内存,对于一个集群来说,还是有一定的压力的。尤其是如果Shuffle Map Task和下游的Task同时增大10倍,那么整体的内存就增长到5TB。
(2)从整体的角度来看,打开多个文件对于系统来说意味着随机读,尤其是每个文件比较小但是数量非常多的情况。而现在机械硬盘在随机读方面的性能特别差,非常容易成为性能的瓶颈。如果集群依赖的是固态硬盘,也许情况会改善很多,但是随机写的性能肯定不如顺序写的。
3,Shuffle Consolidate Writer
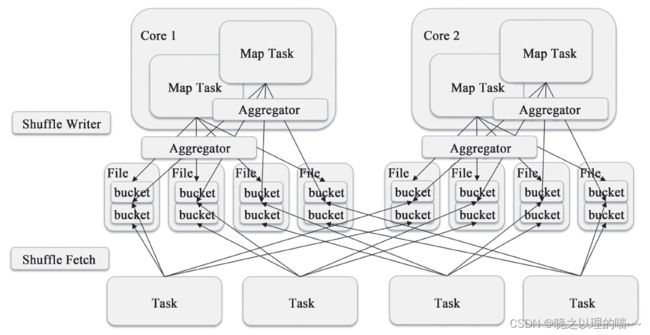
对于运行在同一个Core的Shuffle Map Task,第一个Shuffle Map Task会创建一个文件;之后的就会将数据追加到这个文件上而不是新建一个文件。因此文件数量就从number(shuffle_map_task)*number(following_task)变成了number(cores)*number(following_task)。当然,如果每个Core都只运行一个Shuffle Map Task,那么就和原来的机制一样了。但是Shuffle Map Task明显多于Core数量或者说每个Core都会运行多个Shuffle Map Task,所以这个实现能够显著减少文件的数量。
不同的org.apache.spark.shuffle.FileShuffleBlockManager#forMapTask#writers的实现:
val writers: Array[BlockObjectWriter] = if (consolidateShuffleFiles) {
fileGroup = getUnusedFileGroup() //获得没有使用的FileGroup
Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
blockManager.getDiskWriter(blockId, fileGroup(bucketId), serializer,
bufferSize,
writeMetrics)
}
} else { // Basic Shuffle Writer的实现
org.apache.spark.shuffle.FileShuffleBlockManager.ShuffleFileGroup可以理解成一个文件组,这个文件组的每个文件都对应一个Partition或者下游的Task。因此对第一个Shuffle Map Task来说,它创建了一个文件;而接下来的Shuffle Map Task都是以追加的方式写这个文件。
blockManager.getDiskWriter为每个文件创建一个org.apache.spark.storage.DiskBlock-ObjectWriter,DiskBlockObjectWriter可以直接向一个文件写入数据,如果文件已经存在那么会以追加的方式写入。
但是下游的Task如何区分文件不同的部分呢?在同一个Core上运行Shuffle Map Task相当于写了这个文件的不同的部分。答案就在org.apache.spark.shuffle.FileShuffleBlockManager.ShuffleFileGroup#getFileSegmentFor。
二、Shuffle Pluggable框架

1,org.apache.spark.shuffle.ShuffleManager
Driver和每个Executor都会持有一个ShuffleManager,这个ShuffleManager可以通过配置项spark.shuffle.manager指定,并且由SparkEnv创建。Driver中的ShuffleManager负责注册Shuffle的元数据,比如shuffleId、Map Task的数量等。Executor中的ShuffleManager则负责读和写Shuffle的数据。
需要实现的函数及其功能说明如下:
(1)由Driver注册元数据信息
def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle
一般如果没有特殊的需求,可以使用下面的实现,实际上Hash Based Shuffle和Sort Based Shuffle都是这么实现的。
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
(2)获得Shuffle Writer,根据Shuffle Map Task的ID为其创建Shuffle Writer。
def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext):
ShuffleWriter[K, V]
(3)获得Shuffle Reader,根据shuffleId和Partition的ID为其创建Shuffle Reader。
def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K, C]
(4)为数据成员shuffleBlockManager赋值,以保存实际的ShuffleBlockManager。
(5)def unregisterShuffle(shuffleId:Int):Boolean,删除本地的Shuffle的元数据。
(6)def stop():Unit,停止Shuffle Manager。
每个接口的具体实现的例子,可以参照org.apache.spark.shuffle.sort.SortShuffle-Manager和org.apache.spark.shuffle.hash.HashShuffleManager。
2,org.apache.spark.shuffle.ShuffleWriter
Shuffle Map Task通过ShuffleWriter将Shuffle数据写入本地。这个Writer主要通过ShuffleBlockManager来写入数据,因此它的功能是比较轻量级的。
(1)def write(records:Iterator[_<:Product2[K,V]]):Unit,写入所有的数据。需要注意的是如果需要在Map端做聚合,那么写入前需要将records做聚合。
(2)def stop(success:Boolean):Option[MapStatus],写入完成后提交本次写入。
对于Hash Based Shuffle,请查看org.apache.spark.shuffle.hash.HashShuffleWriter;对于Sort Based Shuffle,请查看org.apache.spark.shuffle.sort.SortShuffleWriter。
3,org.apache.spark.shuffle.ShuffleBlockManager
主要使用从本地读取Shuffle数据的功能。这些接口都是通过org.apache.spark.storage.BlockManager调用的。
(1)def getBytes(blockId:ShuffleBlockId):Option[ByteBuffer],一般通过调用下一个接口实现,只不过将ManagedBuffer转换成了ByteBuffer。
(2)def getBlockData(blockId:ShuffleBlockId):ManagedBuffer,核心读取逻辑。因为不同的实现,文件的组织方式可能是不一样的,比如Hash Based Shuffle从本地读取文件都是通过这个接口实现的,比如Sort Based Shuffle需要先通过读取Index索引文件获得每个Partition的起始位置后,才能读取真正的数据文件。
(3)def stop():Unit,停止该Manager。
对于Hash Based Shuffle,请查看org.apache.spark.shuffle.FileShuffleBlockManager;对于Sort Based Shuffle,请查看org.apache.spark.shuffle.IndexShuffleBlockManager。
4,org.apache.spark.shuffle.ShuffleReader
ShuffleReader实现了下游Task如何读取上游ShuffleMapTask的Shuffle输出的逻辑。这个逻辑比较复杂,简单来说就是通过org.apache.spark.MapOutputTracker获得数据的位置信息,如果数据在本地则调用org.apache.spark.storage.BlockManager的getBlockData读取本地数据(实际上getBlockData最终会调用org.apache.spark.shuffle.ShuffleBlockManager的getBlockData)。
三、Sort Based Write
在Spark 1.2.0中,Spark Core的一个重要的升级就是将默认的Hash Based Shuffle换成了Sort Based Shuffle,即spark.shuffle.manager从Hash换成了Sort,对应的实现类分别是org.apache.spark.shuffle.hash.HashShuffleManager和org.apache.spark.shuffle.sort.SortShuffleManager。
在org.apache.spark.SparkEnv的实现:
// Let the user specify short names for shuffle managers
val shortShuffleMgrNames = Map(
"hash" -> "org.apache.spark.shuffle.hash.HashShuffleManager",
"sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager")
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort") //获得Shuffle //Manager的类型,默认为sort
val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName. toLowerCase, shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
Sort Based Shuffle“取代”Hash Based Shuffle作为默认选项的原因:
Hash Based Shuffle的每个Mapper都需要为每个Reducer写一个文件,供Reducer读取,即需要产生M*R个数量的文件,如果Mapper和Reducer的数量比较大,产生的文件数会非常多。Hash Based Shuffle设计的目标之一就是避免不需要的排序(Hadoop Map Reduce被人诟病的地方,很多不需要Sort的地方的Sort导致了不必要的开销)。但是它在处理超大规模数据集的时候,产生了大量的Disk IO和内存的消耗,这无疑很影响性能。Hash Based Shuffle也在不断的优化中,正如前面讲到的Spark 0.8.1引入的File Consolidation在一定程度上解决了这个问题。为了更好地解决这个问题,Spark 1.1引入了Sort Based Shuffle。首先,每个Shuffle Map Task不会为每个Reducer生成一个单独的文件;相反,它会将所有的结果写到一个文件里,同时会生成一个Index文件,Reducer可以通过这个Index文件取得它需要处理的数据。避免产生大量文件的直接收益就是节省了内存的使用和顺序Disk IO带来的低延时。节省内存的使用可以减少GC的风险和频率。而减少文件的数量可以避免同时写多个文件给系统带来的压力。
Shuffle Map Task会按照key相对应的Partition ID进行Sort,其中属于同一个Partition的key不会Sort。因为对于不需要Sort的操作来说,这个Sort是负收益的;要知道之前Spark刚开始使用Hash Based的Shuffle而不是Sort Based就是为了避免Hadoop Map Reduce对于所有计算都会Sort的性能损耗。对于那些需要Sort的运算,比如sortByKey,这个Sort在Spark 1.2.0里还是由Reducer完成的。
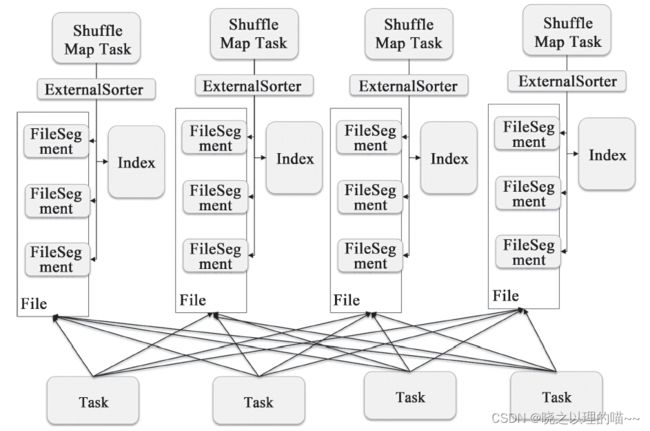
核心实现的逻辑都在类org.apache.spark.shuffle.sort.SortShuffleWriter和它依赖的类中。下面简要分析它的实现:
(1)对于每个Partition,创建一个scala.Array存储它所包含的key/value对。每个待处理的key/value对都会插入相应的scala.Array。
(2)如果scala.Array的大小超过阈值,那么需要将这个内存的数据写入到外部存储。这个文件的开始部分会记录这个Partition的ID及这个文件保存了多少个数据条目等信息。
(3)最后需要将所有写入到外部存储的文件进行归并排序。同时打开的文件不能过多,过多会消耗大量的内存,增加内存溢出(Out of Memory,OOM)或者垃圾回收的风险;也不能过少,过少就会影响性能,增大计算的延时。一般推荐每次同时打开10~100个文件。
(4)在生成最后的数据文件时,需要同时生成Index索引文件。正如前面提到的,这个索引文件将记录不同Partition的起始位置。
四、Shuffle Map Task运算结果的处理
Shuffle Map Task运算结果的处理分为两部分,一个是在Executor端直接处理Task结果的;另一个是Driver端在接到Task运行结束的消息时对Shuffle Write的结果进行处理,从而在调度下游的Task时,使其可以得到需要的数据。
1,Executor端的处理
2,Driver端的处理
TaskRunner将Task的执行状态汇报给Driver后,Driver会转给org.apache.spark.scheduler.TaskSchedulerImpl#statusUpdate。,不同的状态有不同的处理:
如果类型是TaskState.FINISHED,那么调用org.apache.spark.scheduler.TaskResultGetter#enqueueSuccessfulTask进行处理。
如果类型是TaskState.FAILED或者TaskState.KILLED或者TaskState.LOST,调用org.apache.spark.scheduler.TaskResultGetter#enqueueFailedTask进行处理。对于TaskState.LOST,还需要将其所在的Executor标记为failed,并且根据更新后的Executor重新调度。
enqueueSuccessfulTask的逻辑也比较简单,即如果是IndirectTaskResult,那么需要通过blockId来获取结果:sparkEnv.blockManager.getRemoteBytes(blockId);如果是DirectTaskResult,那么结果就无需远程获取了。
核心逻辑是5个调用栈:
(1)org.apache.spark.scheduler.TaskSchedulerImpl#handleSuccessfulTask
(2)org.apache.spark.scheduler.TaskSetManager#handleSuccessfulTask
(3)org.apache.spark.scheduler.DAGScheduler#taskEnded
(4)org.apache.spark.scheduler.DAGScheduler#eventProcessActor
(5)org.apache.spark.scheduler.DAGScheduler#handleTaskCompletion
对于ShuffleMapTask来说,其结果实际上是org.apache.spark.scheduler.MapStatus;其序列化后存入了DirectTaskResult或者IndirectTaskResult中。而DAGScheduler#handleTaskCompletion通过下面的方式来获取这个结果:
val status =event.result.asInstanceOf[MapStatus]
通过将这个status注册到org.apache.spark.MapOutputTrackerMaster,就完成了结果处理的过程:
mapOutputTracker.registerMapOutputs(
stage.shuffleDep.get.shuffleId,
stage.outputLocs.map(list => if (list.isEmpty) null else list.head).toArray,
changeEpoch = true)
registerMapOutputs的处理也很简单,以shuffleID为key将MapStatus的列表存入带有时间戳的HashMap:TimeStampedHashMap[Int,Array[MapStatus]]()。如果设置了cleanup的函数,那么这个HashMap会将超过一定时间(TTL,Time to Live)的数据清理掉。
五、Shuffle Read
除了需要从外部存储读取数据和RDD已经做过cache或者checkpoint的Task,一般Task都是从ShuffledRDD的Shuffle Read开始的。
1,整体流程

org.apache.spark.rdd.ShuffledRDD#compute开始,通过调用org.apache.spark.shuffle.ShuffleManager的getReader方法,获取到org.apache.spark.shuffle.ShuffleReader,然后调用其read()方法进行读取。在Spark 1.2.0中,不管是Hash Based Shuffle或者是Sort Based Shuffle,内置的Shuffle Reader都是org.apache.spark.shuffle.hash.HashShuffleReader。
override def read(): Iterator[Product2[K, C]] = {
val ser = Serializer.getSerializer(dep.serializer)
// 获取结果
val iter = BlockStoreShuffleFetcher.fetch(handle.shuffleId, start-Partition,context,ser)
// 处理结果
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
//需要聚合
if (dep.mapSideCombine) {//需要mapSide的聚合
new InterruptibleIterator(context, dep.aggregator.get.combineCombiners-
ByKey(iter, context))
} else {//只需要Reducer端的聚合
new InterruptibleIterator(context, dep.aggregator.get.combineValues-
ByKey(iter, context))
}
} else { // 无需聚合操作
iter.asInstanceOf[Iterator[Product2[K, C]]].map(pair => (pair._1, pair._2))
}
// Sort the output if there is a sort ordering defined.
dep.keyOrdering match {//判断是否需要排序
case Some(keyOrd: Ordering[K]) => //对于需要排序的情况 使用ExternalSorter进行排序,注意如果spark.shuffle.spill是false,那么数据是不会写入到硬盘的
val sorter = new ExternalSorter[K, C, C](ordering = Some(keyOrd),
serializer = Some(ser))
sorter.insertAll(aggregatedIter)
context.taskMetrics.memoryBytesSpilled += sorter.memoryBytesSpilled
context.taskMetrics.diskBytesSpilled += sorter.diskBytesSpilled
sorter.iterator
case None => //无需排序
aggregatedIter
}
}
org.apache.spark.shuffle.hash.BlockStoreShuffleFetcher#fetch会获得数据,它首先会通过org.apache.spark.MapOutputTracker#getServerStatuses来获得数据的meta信息,这个过程有可能需要向org.apache.spark.MapOutputTrackerMasterActor发送读请求,这个读请求是在org.apache.spark.MapOutputTracker#askTracker发出的。在获得了数据的meta信息后,它会将这些数据存入Seq[(BlockManagerId,Seq[(BlockId,Long)])]中,然后调用org.apache.spark.storage.ShuffleBlockFetcherIterator最终发起请求。ShuffleBlockFetcherIterator根据数据的本地性原则进行数据获取。如果数据在本地,那么会调用org.apache.spark.storage.BlockManager#getBlockData进行本地数据块的读取。而对于shuffle类型的数据,会调用ShuffleManager的ShuffleBlockManager的getBlockData。
如果数据在其他的Executor上,若用户使用的spark.shuffle.blockTransferService是netty,那么就会通过org.apache.spark.network.netty.NettyBlockTransferService#fetchBlocks获取;如果使用的是nio,那么就会通过org.apache.spark.network.nio.NioBlockTransferService#fetchBlocks获取。
2,数据读取策略的划分
org.apache.spark.storage.ShuffleBlockFetcherIterator会通过splitLocalRemoteBlocks划分数据的读取策略:如果数据在本地,那么可以直接从BlockManager中获取;如果需要从其他的节点上获取,则需要通过网络。由于Shuffle的数据量可能会很大,因此这里的网络读取分为以下几种策略:
(1)每次最多启动5个线程到最多5个节点上读取数据。
(2)每次请求的数据大小不会超过spark.reducer.maxMbInFlight(默认值为48MB)的五分之一。
3,本地读取
fetchLocalBlocks()负责本地Block的获取。在splitLocalRemoteBlocks中,已经将本地的Block列表存入了localBlocks:private[this]val localBlocks=new Array-Buffer[BlockId]()。
过程如下:
val iter = localBlocks.iterator
while (iter.hasNext) {
val blockId = iter.next()
try {
val buf = blockManager.getBlockData(blockId)
shuffleMetrics.localBlocksFetched += 1
buf.retain()
results.put(new SuccessFetchResult(blockId, 0, buf))
} catch {
}
}
blockManager.getBlockData(blockId)的实现:
override def getBlockData(blockId: BlockId): ManagedBuffer = {
if (blockId.isShuffle) {
shuffleManager.shuffleBlockManager.getBlockData(blockId.asInstance-
Of[ShuffleBlockId])
}
以Hash Based Shuffle为例,它的ShuffleBlockManager是org.apache.spark.shuffle.FileShuffleBlockManager。FileShuffleBlockManager有两种情况,一种是consolidateFile的,这种需要根据Map ID和Reduce ID首先获得FileGroup的一个文件,然后根据在文件中的offset和size来获取需要的数据;如果是没有consolidateFile,那么根据Shuffle Block ID直接读取整个文件就可以。
override def getBlockData(blockId: ShuffleBlockId): ManagedBuffer = {
if (consolidateShuffleFiles) {
val shuffleState = shuffleStates(blockId.shuffleId)
val iter = shuffleState.allFileGroups.iterator
while (iter.hasNext) {
// 根据Map ID和Reduce ID获取File Segment的信息
val segmentOpt = iter.next.getFileSegmentFor(blockId.mapId, blockId.reduceId)
if (segmentOpt.isDefined) {
val segment = segmentOpt.get
// 根据File Segment的信息,从FileGroup中找到相应的File和Block在文件中的offset和size
return new FileSegmentManagedBuffer(
transportConf, segment.file, segment.offset, segment.length)
}
}
throw new IllegalStateException("Failed to find shuffle block: " + blockId)
} else {
val file = blockManager.diskBlockManager.getFile(blockId) //直接获取文件句柄
new FileSegmentManagedBuffer(transportConf, file, 0, file.length)
}
}
对于Sort Based Shuffle,它需要通过索引文件来获得数据块在数据文件中的具体位置信息,从而读取这个数据。
org.apache.spark.shuffle.IndexShuffleBlockManager#getBlockData实现:
override def getBlockData(blockId: ShuffleBlockId): ManagedBuffer = {
//根据ShuffleID和MapID从org.apache.spark.storage.DiskBlockManager获取索引文件
val indexFile = getIndexFile(blockId.shuffleId, blockId.mapId)
val in = new DataInputStream(new FileInputStream(indexFile))
try {
ByteStreams.skipFully(in, blockId.reduceId * 8) //跳到本次Block的数据区
val offset = in.readLong() //数据文件中的开始位置
val nextOffset = in.readLong() //数据文件中的结束位置
new FileSegmentManagedBuffer(
transportConf,
getDataFile(blockId.shuffleId, blockId.mapId),
offset,
nextOffset - offset)
} finally {
in.close()
}
}
4,远程读取
现在支持两种远程读取的方式,一种是netty,一种是nio,可以通过spark.shuffle.blockTransferService来进行设置。
org.apache.spark.storage.ShuffleBlockFetcherIterator#sendRequest会向远程的节点发起读取Block的请求:
shuffleClient.fetchBlocks(address.host,address.port,address.executorId,
blockIds.toArray,
new BlockFetchingListener {
override def onBlockFetchSuccess(blockId: String,buf: Managed-
Buffer): Unit = {
//请求成功,省略非关键代码
buf.retain()
results.put(new SuccessFetchResult(BlockId(blockId), sizeMap
(blockId), buf))
}
override def onBlockFetchFailure(blockId: String, e: Throwable):
Unit = {
results.put(new FailureFetchResult(BlockId(blockId), e))
}
}
shuffleClient实际上在默认情况下(即spark.shuffle.service.enabled为false)就是blockTransferService:
private[spark] val shuffleClient = if (externalShuffleServiceEnabled) {
val transConf = SparkTransportConf.fromSparkConf(conf, numUsableCores)
new ExternalShuffleClient(transConf, securityManager, securityManager.isAuthenticationEnabled())
} else {
blockTransferService
}
blockTransferService是在SparkEnv里创建的:
val blockTransferService =
conf.get("spark.shuffle.blockTransferService", "netty").toLowerCase match {
case "netty" =>
new NettyBlockTransferService(conf, securityManager, numUsableCores)
case "nio" =>
new NioBlockTransferService(conf, securityManager)
}
org.apache.spark.network.netty.NettyBlockTransferService的fetchBlocks的实现:它会调用org.apache.spark.network.shuffle.OneForOneBlockFetcher,OneForOneBlockFetcher持有org.apache.spark.network.client.TransportClient,它就是最终发送请求的Handler。TransportClient的请求会被org.apache.spark.network.netty.NettyBlockRpcServer接收并处理,通过上述的网络调用,请求最终会传到远程节点的BlockManager:由org.apache.spark.storage.BlockManager#getBlockData处理这个读取Block的请求。
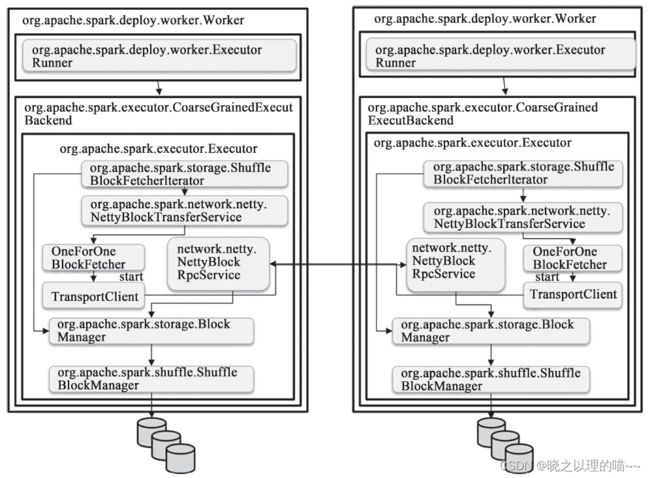
六、性能调优
1,spark.shuffle.manager
Spark 1.2.0官方版本支持两种方式的Shuffle,即Hash Based Shuffle和Sort Based Shuffle。其中在Spark 1.0之前仅支持Hash Based Shuffle。Spark 1.1引入了Sort Based Shuffle。Spark1.2的默认Shuffle机制从Hash变成了Sort。如果需要Hash Based Shuffle,只需将spark.shuffle.manager设置成“hash”即可。
如果对性能有比较苛刻的要求,那么就要理解这两种不同的Shuffle机制的原理,结合具体的应用场景进行选择。
Hash Based Shuffle,就是根据Hash的结果,将各个Reducer Partition的数据写到单独的文件中去,写数据时不会有排序的操作。如果Reducer的Partition比较多,会产生大量的磁盘文件。这会带来两个问题:
(1)同时打开的文件比较多,那么大量的文件句柄和写操作分配的临时内存会非常大,会对内存的使用和GC带来很多压力。尤其是在Spark的YARN模式下Executor分配的内存普遍比较小的时候,这个问题会更严重。
(2)从整体来看,这些文件带来大量的随机读,读性能可能会遇到瓶颈。
Sort Based Shuffle会根据实际情况对数据采用不同的方式进行Sort。这个排序可能仅仅是按照Reducer的Partition进行排序,保证同一个Shuffle Map Task对应的不同的Reducer Partition的数据都可以写到同一个数据文件,通过一个offset来标记不同Reducer Partition的分界。因此一个Shuffle Map Task仅仅会生成一个数据文件(还有一个Index索引文件),从而避免了HashBased Shuffle文件数量过多的问题。
选择Hash还是Sort,取决于内存、排序和文件操作等因素的综合影响。
对于不需要进行排序且Shuffle产生的文件数量不是特别多时,Hash Based Shuffle可能是更好的选择;因为Sort Based Shuffle会按照Reducer的Partition进行排序。
而Sort Based Shuffle的优势就在于可扩展性,它的出现实际上很大程度上是解决Hash Based Shuffle的可扩展性的问题。由于Sort Based Shuffle还在不断地演进中,因此它的性能会得到不断改善。
对于选择哪种Shuffle,如果性能要求苛刻,最好还是通过实际测试后再做决定。不过选择默认的Sort,可以满足大部分的场景需要。
2,spark.shuffle.spill
这个参数的默认值是true,用于指定Shuffle过程中如果内存中的数据超过阈值(参考spark.shuffle.memoryFraction的设置)时是否需要将部分数据临时写入外部存储。如果设置为false,那么这个过程就会一直使用内存,会有内存溢出的风险。因此只有在确定内存足够使用时,才可以将这个选项设置为false。
Hash Based Shuffle的Shuffle Write过程中使用的org.apache.spark.util.collection.AppendOnlyMap就是全内存的方式,而org.apache.spark.util.collection.ExternalAppend-OnlyMap对org.apache.spark.util.collection.AppendOnlyMap有了进一步的封装,在内存使用超过阈值时会将它写入到外部存储,在最后的时候会对这些临时文件进行合并。
而Sort Based Shuffle Write使用到的org.apache.spark.util.collection.ExternalSorter也会有类似的写入。
对于Shuffle Read,如果需要做聚合,也可能在聚合的过程中将数据写入的外部存储。
3,spark.shuffle.memoryFraction和spark.shuffle.safetyFraction
在启用spark.shuffle.spill的情况下,spark.shuffle.memoryFraction决定了当Shuffle过程中使用的内存达到总内存多少比例的时候开始spill。在Spark 1.2.0里,这个值是0.2。通过这个参数可以设置Shuffle过程占用内存的大小,它直接影响了写入到外部存储的频率和垃圾回收的频率。
如果写入到外部存储的频率太高,那么可以适当地增加spark.shuffle.memoryFraction来增加Shuffle过程的可用内存数,进而减少写入到外部存储的频率。当然为了避免内存溢出,可能就需要减少RDD cache所用的内存,即需要减少spark.storage.memoryFraction的值;但是减少RDD cache所用的内存有可能会带来其他影响,因此需要综合考量。
在Shuffle过程中,Shuffle占用的内存数是估计出来的,并不是每次新增的数据项都会计算一次占用的内存大小,这样做是为了降低时间开销。但是估计也会有误差,因此存在实际使用的内存数比估算值要大的情况,因此参数spark.shuffle.safetyFraction作为一个保险系数降低实际Shuffle过程所需要的内存值,可以降低实际内存超出用户配置值的风险。
4,spark.shuffle.sort.bypassMergeThreshold
这个配置的默认值是200,用于设置在Reducer的Partition数目少于多少的时候,Sort Based Shuffle内部不使用归并排序的方式处理数据,而是直接将每个Partition写入单独的文件。这个方式和Hash Based的方式类似,区别就是在最后这些文件还是会合并成一个单独的文件,并通过一个Index索引文件来标记不同Partition的位置信息。从Reducer来看,数据文件和索引文件的格式和内部是否做过归并排序是完全相同的。
这个可以看作Sort Based Shuffle在Shuffle量比较小的时候对于Hash Based Shuffle的一种折中。当然了它和Hash Based Shuffle一样,也存在同时打开文件过多导致内存占用增加的问题。因此如果GC比较严重或者内存比较紧张,可以适当降低这个值。
5,spark.shuffle.blockTransferService
在Spark 1.2.0中这个配置的默认值是netty,而在之前的版本中是nio。它主要是用于在各个Executor之间传输Shuffle数据。netty的实现更加简洁,但实际上用户不用太关心这个选项。除非有特殊需求,否则采用默认配置即可。
6,spark.shuffle.consolidateFiles
这个配置的默认值是false。主要是为了解决在Hash Based Shuffle过程中产生过多文件的问题。如果配置选项为true,那么对于同一个Core上运行的Shuffle Map Task不会产生一个新的Shuffle文件而是重用原来的。但是每个Shuffle Map Task还是需要产生下游Task数量的文件,因此它并没有减少同时打开文件的数量。如果需要了解更多细节,可以阅读7.1节。
但是consolidateFiles的机制在Spark 0.8.1就引入了,到Spark 1.2.0还是没有稳定下来。从源码实现的角度看,实现源码是非常简单的,但是由于涉及本地文件系统等限制,这个策略可能会带来各种各样的问题。由于它并没有减少同时打开文件的数量,因此不能减少由文件句柄带来的内存消耗。如果Shuffle的文件数量非常大,那么是否打开这个选项最好还是通过实际测试后再决定。
7,spark.shuffle.compress和spark.shuffle.spill.compress
这两个参数的默认配置都是true。spark.shuffle.compress和spark.shuffle.spill.compress都是用来设置Shuffle过程中是否对Shuffle数据进行压缩。其中,前者针对最终写入本地文件系统的输出文件;后者针对在处理过程需要写入到外部存储的中间数据,即针对最终的shuffle输出文件。
(1)设置spark.shuffle.compress
如果下游的Task通过网络获取上游Shuffle Map Task的结果的网络IO成为瓶颈,那么就需要考虑将它设置为true:通过压缩数据来减少网络IO。由于上游Shuffle Map Task和下游的Task现阶段是不会并行处理的,即上游Shuffle Map Task处理完成后,下游的Task才会开始执行。那么需要压缩的时间消耗就是Shuffle Map Task压缩数据的时间+网络传输的时间+下游Task解压的时间;而不需要压缩的时间消耗仅仅是网络传输的时间。因此需要评估压缩解压时间带来的时间消耗和因为数据压缩带来的时间节省。如果网络成为瓶颈,比如集群普遍使用的是千兆网络,那么将这个选项设置为true可能更合理;如果计算是CPU密集型的,那么将这个选项设置为false可能更好。
(2)设置spark.shuffle.spill.compress
如果设置为true,代表处理的中间结果在spill到本地硬盘时都会进行压缩,在将中间结果取回进行merge的时候,要进行解压。因此要综合考虑CPU由于引入压缩、解压的消耗时间和Disk IO因为压缩带来的节省时间的比较。在Disk IO成为瓶颈的场景下,设置为true可能比较合适;如果本地硬盘是SSD,那么设置为false可能比较合适。
8,spark.reducer.maxMbInFlight
这个参数用于限制一个Reducer Task向其他的Executor请求Shuffle数据时所占用的最大内存数,尤其是如果网卡是千兆和千兆以下的网卡时。默认值是48MB。设置这个值需要综合考虑网卡带宽和内存。
文章来源:《Spark技术内幕:深入解析Spark内核架构设计与实现原理》 作者:张安站
文章内容仅供学习交流,如有侵犯,联系删除哦!