机器学习本科课程 大作业 多元时间序列预测
1. 问题描述
1.1 阐述问题
对某电力部门的二氧化碳排放量进行回归预测,有如下要求
- 数据时间跨度从1973年1月到2021年12月,按月份记录。
- 数据集包括“煤电”,“天然气”,“馏分燃料”等共9个指标的数据(其中早期的部分指标not available)
- 要求预测从2022年1月开始的半年时间的以下各个部分的排放量
二氧化碳的排放情况具体分为九项指标:
- Coal Electric Power Sector CO2 Emissions(煤电力行业二氧化碳排放 )
- Natural Gas Electric Power Sector CO2 Emissions(天然气电力行业二氧化碳排放)
- Distillate Fuel, Including Kerosene-Type Jet Fuel, Oil Electric Power Sector CO2 Emissions(蒸馏燃料,包括喷气燃料、石油电力行业二氧化碳排放)
- Petroleum Coke Electric Power Sector CO2 Emissions(石油焦电力行业二氧化碳排放)
- Residual Fuel Oil Electric Power Sector CO2 Emissions(残余燃料油电力行业二氧化碳排放)
- Petroleum Electric Power Sector CO2 Emissions(石油电力行业二氧化碳排放)
- Geothermal Energy Electric Power Sector CO2 Emissions(地热能电力行业二氧化碳排放)
- Non-Biomass Waste Electric Power Sector CO2 Emissions(非生物质废物电力行业二氧化碳排放)
- Total Energy Electric Power Sector CO2 Emissions(总能源电力行业二氧化碳排放)
1.2 方案设计
- 由于9个指标之间存在相关性,对一个指标的未来值进行预测,除了考虑自身的历史值以外,还需要引入其他指标对该指标的影响。
- 数据量大、时间周期长,需要采用具有较强回归能力的、能够实现时间序列预测任务的机器学习模型。
1.3 方法概括
经过讨论研究,本次实验通过三种神经网络模型独立实现了多元时间序列回归预测任务,分别是:
| 模型 | 介绍 | 特点 |
|---|---|---|
| BP | 误差反向传播网络 | 通过多次学习获取非线性映射 |
| TCN | 时间卷积网络 | 因果卷积实现时间预测 |
| LSTM | 长短时记忆网络 | 门控结构保存长时记忆 |
通过从无到有建立模型、性能优化、模型比较等流程,小组成员强化了机器学习的基础知识,提升了机器学习相应技能的熟练程度,对机器学习的理论和部分模型的特性有了进一步的理解
2. BP神经网络(Backpropagation Neural Network)
2.1 模型原理
BP神经网络是一种前馈神经网络,采用反向传播算法进行训练。该网络由输入层、隐藏层和输出层组成。每个神经元与前一层的所有神经元相连接,每个连接都有一个权重,网络通过调整这些权重来学习输入与输出之间的映射关系。
BP神经网络通过反向传播(Backpropagation)计算模型输出与实际输出之间的误差,然后反向传播误差,调整网络参数以最小化误差。
在本次实验中,采取了500大小的隐藏层,以0.01学习率进行了2000轮的训练。
2.2.1数据处理
从xlsx读取数据,取前80%数据为训练集,后20%为测试集
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
# 读取xlsx文件
data = pd.read_excel("data.xlsx")
side = 192 # 有缺失部分的长度
side2 = 587 # 整个已知数据的长度
seq_len = 10
batch_size = 64
data = data.iloc[1:side2 + 1]
# 提取全部列名
col_names = data.columns.values.tolist()
col_names = [col_names[i] for i in range(1, len(col_names))]
data_list = np.array(data[col_names].values.tolist())
# 处理缺失值,用平均值填充
data_list[data_list == "Not Available"] = np.nan
data_list = data_list.astype(float)
imputer = SimpleImputer(strategy='mean', fill_value=np.nan)
data_imputed = imputer.fit_transform(data_list)
# 标准化处理
scaler = StandardScaler()
data_normalized = scaler.fit_transform(data_imputed)
# 划分训练集和测试集
data_len = len(data_normalized)
train_data = data_normalized[:int(0.75 * data_len)] # 取前75%作为训练集
test_data = data_normalized[int(0.75 * data_len):] # 取剩下25%作为测试集
2.3.2 定义画图函数
# 画出曲线
def plot_results(X_test, Y_test, W1, b1, W2, b2, scaler, col_names):
Y_pred, _ = forward(X_test, W1, b1, W2, b2)
Y_pred_original = scaler.inverse_transform(Y_pred)
Y_test_original = scaler.inverse_transform(Y_test)
f, ax = plt.subplots(nrows=3, ncols=3, figsize=(20, 10))
for i in range(3):
for j in range(3):
ax[i, j].plot(Y_pred_original[:, 3 * i + j], label='predictions')
ax[i, j].plot(Y_test_original[:, 3 * i + j], label='true')
ax[i, j].set_title(col_names[3 * i + j])
ax[i, j].legend()
plt.tight_layout()
plt.show()
# 绘制Loss曲线
def plot_loss_curve(training_losses, testing_losses):
plt.figure(figsize=(10, 6))
plt.plot(training_losses, label='Training Loss', color='blue')
plt.plot(testing_losses, label='Testing Loss', color='orange')
plt.title('Training and Testing Loss Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
2.3.3 定义BP神经网络结构
# 参数初始化
def initialize_parameters(input_size, hidden_size, output_size):
np.random.seed(42)
W1 = np.random.randn(input_size, hidden_size) * 0.01
b1 = np.zeros((1, hidden_size))
W2 = np.random.randn(hidden_size, output_size) * 0.01
b2 = np.zeros((1, output_size))
return W1, b1, W2, b2
# 前向传播
def forward(X, W1, b1, W2, b2):
Z1 = np.dot(X, W1) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(A1, W2) + b2
return Z2, A1
# 损失函数
def compute_loss(Y, Y_pred):
m = Y.shape[0]
loss = np.sum((Y - Y_pred) ** 2) / m
return loss
# 反向传播
def backward(X, A1, Y, Y_pred, W1, W2, b1, b2):
m = X.shape[0]
dZ2 = Y_pred - Y
dW2 = np.dot(A1.T, dZ2) / m
db2 = np.sum(dZ2, axis=0, keepdims=True) / m
dA1 = np.dot(dZ2, W2.T)
dZ1 = dA1 * (1 - np.tanh(A1) ** 2)
dW1 = np.dot(X.T, dZ1) / m
db1 = np.sum(dZ1, axis=0, keepdims=True) / m
return dW1, db1, dW2, db2
# 梯度下降更新参数
def update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate):
W1 -= learning_rate * dW1
b1 -= learning_rate * db1
W2 -= learning_rate * dW2
b2 -= learning_rate * db2
return W1, b1, W2, b2
# 训练神经网络
def train_neural_network(X_train, Y_train, X_test, Y_test, input_size, hidden_size, output_size, epochs, learning_rate):
W1, b1, W2, b2 = initialize_parameters(input_size, hidden_size, output_size)
training_losses = []
testing_losses = []
start_time = time.time()
for epoch in range(epochs):
# 前向传播训练集
Y_pred_train, A1_train = forward(X_train, W1, b1, W2, b2)
# 计算训练集损失
train_loss = compute_loss(Y_train, Y_pred_train)
training_losses.append(train_loss)
# 前向传播测试集
Y_pred_test, _ = forward(X_test, W1, b1, W2, b2)
# 计算测试集损失
test_loss = compute_loss(Y_test, Y_pred_test)
testing_losses.append(test_loss)
# 反向传播和参数更新
dW1, db1, dW2, db2 = backward(X_train, A1_train, Y_train, Y_pred_train, W1, W2, b1, b2)
W1, b1, W2, b2 = update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate)
# 打印每个epoch的损失
print(f"Epoch {epoch + 1}/{epochs} - Training Loss: {train_loss:.10f} - Testing Loss: {test_loss:.10f}")
end_time = time.time()
training_duration = end_time - start_time
print(f"用时 {training_duration:.2f} s")
# 结束后,画出图像
plot_loss_curve(training_losses, testing_losses)
plot_results(X_test, Y_test, W1, b1, W2, b2, scaler, col_names)
return W1, b1, W2, b2, training_losses, testing_losses
2.3.4 模型训练流程及性能表现
# 将训练数据和测试数据准备为神经网络输入
X_train = train_data[:-seq_len]
Y_train = train_data[seq_len:]
X_test = test_data[:-seq_len]
Y_test = test_data[seq_len:]
# 参数设置
input_size = X_train.shape[1]
hidden_size = 500
output_size = Y_train.shape[1]
epochs = 2000
learning_rate = 0.01
# 训练神经网络
W1_final, b1_final, W2_final, b2_final, training_losses, testing_losses = train_neural_network(X_train, Y_train, X_test, Y_test, input_size, hidden_size, output_size, epochs, learning_rate)
# 在训练完成后,使用训练好的模型对训练集和测试集进行预测
Y_pred_train, _ = forward(X_train, W1_final, b1_final, W2_final, b2_final)
Y_pred_test, _ = forward(X_test, W1_final, b1_final, W2_final, b2_final)
# 将预测值逆归一化
Y_pred_train_original = scaler.inverse_transform(Y_pred_train)
Y_pred_test_original = scaler.inverse_transform(Y_pred_test)
# 逆归一化训练集和测试集的真实值
Y_train_original = scaler.inverse_transform(Y_train)
Y_test_original = scaler.inverse_transform(Y_test)
# 计算 MAE 和 MSE
mse_on_train = np.mean((Y_train_original - Y_pred_train_original) ** 2)
mse_on_test = np.mean((Y_test_original - Y_pred_test_original) ** 2)
mae_on_train = np.mean(np.abs(Y_train_original - Y_pred_train_original))
mae_on_test = np.mean(np.abs(Y_test_original - Y_pred_test_original))
# 输出最终的 MAE 和 MSE
print(f"mse_on_train: {mse_on_train:.10f} mse_on_test: {mse_on_test:.10f}")
print(f"mae_on_train: {mae_on_train:.10f} mae_on_test: {mae_on_test:.10f}")
3. TCN网络(Temporal Convolutional Network)
3.1 模型原理
TCN是一种基于卷积操作的神经网络,特别适用于处理时序数据。与传统的循环神经网络(RNN)和LSTM相比,TCN使用卷积层捕捉时序数据中的模式,从而更好地捕获长期依赖关系。
从结构上来说,TCN通常由一个或多个卷积层组成,卷积层的感受野逐渐增大,从而能够捕捉不同尺度的模式。此外,TCN还可以通过残差连接来加强梯度的流动,从而更容易训练深层网络。
3.2.1 数据处理
在第一个实验方案中,BP网络直接将整段历史信息输入给了模型;为了更充分地考虑数据集中的时序信息以及加快训练速度,TCN网络和LSTM采取了时间窗口的划分方式。
滑动窗口(rolling window)将时间序列划分为多个窗口,在每个窗口内进行训练和测试,如果存在较大的波动或季节性变化,而且这些变化的周期较长,使用滑动窗口可以更好地捕捉到这些特征。
TCN中,仍然设定前80%为训练数据,时间窗口大小为16
import pandas as pd
import numpy as np
import torch
from torch import optim
from torch.utils.data import Dataset, DataLoader,TensorDataset
import torch.nn as nn
from sklearn.preprocessing import StandardScaler, Normalizer
import matplotlib.pyplot as plt
def windows_split(data, seq_len):
res = []
label = []
for i in range(len(data) - seq_len):
res.append(data[i:i + seq_len])
label.append(data[i + seq_len])
res = np.array(res).astype(np.float32)
label = np.array(label).astype(np.float32)
return res, label
data = pd.read_excel("data.xlsx")
side = 192 # 有缺失部分的长度
side2 = 587 # 整个已知数据的长度
seq_len = 16
batch_size = 64
# 提取全部列名
col_names = data.columns.values.tolist()
col_names = [col_names[i] for i in range(1, len(col_names))]
data.replace("Not Available", np.nan, inplace=True)
interpolated = data[col_names].interpolate(method='spline', order=3)
data_list = np.array(data[col_names].values.tolist())
scalar = StandardScaler()
data_list = scalar.fit_transform(data_list)
data_list[np.isnan(data_list)] = 0
data_split, label_split = windows_split(data_list[side:side2], seq_len)
data_split = np.transpose(data_split, (0, 2, 1))
length = data_split.shape[0]
data_train = torch.Tensor(data_split[0:int(0.8 * length), :])
label_train = torch.Tensor(label_split[0:int(0.8 * length)])
data_test = torch.Tensor(data_split[int(0.8 * length):int(length), :])
label_test = torch.Tensor(label_split[int(0.8 * length):label_split.shape[0]])
dataset_train = TensorDataset(data_train, label_train)
dataset_test = TensorDataset(data_test, label_test)
train_loader = DataLoader(dataset_train, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset_test, batch_size=batch_size, shuffle=False)
input_size = 9
output_size = 9
num_channels = [32, 64, 128, 256]
kernel_size = 3
dropout = 0
num_epochs = 200
3.2.2 模型定义
每层TCN定义为:[conv, chomp, relu, dropout]*2
学习率0.0001,训练轮数200
import torch
import torch.nn as nn
from torch.nn.utils import weight_norm
class Chomp1d(nn.Module):
def __init__(self, chomp_size):
super(Chomp1d, self).__init__()
self.chomp_size = chomp_size
def forward(self, x):
return x[:, :, :-self.chomp_size].contiguous()
class TemporalBlock(nn.Module):
def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2):
super(TemporalBlock, self).__init__()
self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
self.chomp1 = Chomp1d(padding)
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(dropout)
self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
self.chomp2 = Chomp1d(padding)
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(dropout)
self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1,
self.conv2, self.chomp2, self.relu2, self.dropout2)
self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else None
self.relu = nn.ReLU()
self.init_weights()
def init_weights(self):
self.conv1.weight.data.normal_(0, 0.01)
self.conv2.weight.data.normal_(0, 0.01)
if self.downsample is not None:
self.downsample.weight.data.normal_(0, 0.01)
def forward(self, x):
out = self.net(x)
res = x if self.downsample is None else self.downsample(x)
return self.relu(out + res)
class TemporalConvNet(nn.Module):
def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2):
super(TemporalConvNet, self).__init__()
layers = []
num_levels = len(num_channels)
for i in range(num_levels):
dilation_size = 2 ** i
in_channels = num_inputs if i == 0 else num_channels[i-1]
out_channels = num_channels[i]
layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size,
padding=(kernel_size-1) * dilation_size, dropout=dropout)]
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)
class TCN(nn.Module):
def __init__(self, input_size, output_size, num_channels, kernel_size, dropout):
super(TCN, self).__init__()
self.tcn = TemporalConvNet(input_size, num_channels, kernel_size=kernel_size, dropout=dropout)
self.linear = nn.Linear(num_channels[-1], output_size)
def forward(self, inputs):
"""Inputs have to have dimension (N, C_in, L_in)"""
y1 = self.tcn(inputs) # input should have dimension (N, C, L)
o = self.linear(y1[:, :, -1])
return o
3.2.3 模型训练流程及性能表现
model = TCN(input_size, output_size, num_channels, kernel_size, dropout)
optimizer = optim.Adam(model.parameters(), lr=1e-4)
criterion = nn.MSELoss()
criterion2 = nn.L1Loss()
loss_train_list = []
loss_test_list = []
for i in range(num_epochs):
model.train()
n = 0
loss_total = 0
for data, label in train_loader:
optimizer.zero_grad()
pred = model(data)
loss = criterion(pred, label)
loss.backward()
optimizer.step()
n += 1
loss_total += loss.item()
loss_total /= n
loss_train_list.append(loss_total)
model.eval()
loss_test_total = 0
n = 0
for data,label in test_loader:
with torch.no_grad():
pred = model(data)
loss = criterion(pred, label)
loss_test_total += loss.item()
n+=1
loss_test_total /= n
loss_test_list.append(loss_test_total)
print('epoch:{0}/{1} loss_train:{2} loss_test:{3}'.format(i + 1, num_epochs, loss_total,loss_test_total))
model.eval()
prediction = model(data_test)
prediction = prediction.detach().numpy()
label_test = label_test.detach().numpy()
prediction = scalar.inverse_transform(prediction)
label_test = scalar.inverse_transform(label_test)
f,ax = plt.subplots(nrows=3,ncols=3,figsize=(10, 10))
for i in range(3):
for j in range(3):
ax[i,j].plot(prediction[:,3 * i + j],label = 'predictions')
ax[i,j].plot(label_test[:,3 * i + j],label = 'true')
ax[i,j].set_title(col_names[3 * i + j])
ax[i,j].legend()
plt.tight_layout()
plt.show()
plt.plot(loss_test_list,label = 'loss_on_test')
plt.plot(loss_train_list,label = 'loss_on_train')
plt.legend()
plt.show()
prediction_train = model(data_train)
prediction_train = prediction_train.detach().numpy()
prediction_train = scalar.inverse_transform(prediction_train)
label_train = scalar.inverse_transform(label_train)
mse_on_train = criterion(torch.Tensor(prediction_train),torch.Tensor(label_train))
rmse_on_train = torch.sqrt(mse_on_train)
mae_on_train = criterion2(torch.Tensor(prediction_train),torch.Tensor(label_train))
mse_on_test = criterion(torch.Tensor(prediction),torch.Tensor(label_test))
rmse_on_test = torch.sqrt(mse_on_test)
mae_on_test = criterion2(torch.Tensor(prediction),torch.Tensor(label_test))
print('mse_on_train:{0} mse_on_test:{1}'.format(mse_on_train,mse_on_test))
print('rmse_on_train:{0} rmse_on_test:{1}'.format(rmse_on_train,rmse_on_test))
print('mae_on_train:{0} mae_on_test:{1}'.format(mae_on_train,mae_on_test))
# data_split = torch.Tensor(data_split)
# label_split = torch.Tensor(label_split)
# prediction_rest = []
# windows = torch.cat((data_split[-1,:,1:],label_split[-1].unsqueeze(1)),dim = 1).unsqueeze(0)
# for i in range(6):
# pred = model(windows)
# prediction_rest.append(pred.detach().numpy().squeeze())
# windows = torch.cat((windows[-1,:,1:],torch.transpose(pred, 0, 1)),dim = 1).unsqueeze(0)
# # print(prediction_rest)
# prediction_rest = np.array(prediction_rest)
# prediction_rest = scalar.inverse_transform(prediction_rest)
# prediction_total = model(data_split)
# prediction_total = prediction_total.detach().numpy()
# label_split = label_split.detach().numpy()
# prediction_total = scalar.inverse_transform(prediction_total)
# label_split = scalar.inverse_transform(label_split)
# f,ax = plt.subplots(nrows=3,ncols=3,figsize=(10, 10))
# length = prediction_total.shape[0]
# for i in range(3):
# for j in range(3):
# ax[i,j].plot(range(length),prediction_total[:,3 * i + j],label = 'predictions')
# ax[i,j].plot(range(length),label_split[:,3 * i + j],label = 'true')
# ax[i,j].plot(range(length,length+6),prediction_rest[:,3 * i + j],label = 'rest')
# ax[i,j].set_title(col_names[3 * i + j])
# ax[i,j].legend()
# plt.tight_layout()
# plt.show()
4. LSTM网络
4.1 模型原理
LSTM是一种循环神经网络(RNN)的变体,专门设计用来解决长期依赖问题。LSTM引入了门控机制,包括输入门、遗忘门和输出门,以有效地控制信息的流动。
LSTM中的记忆单元可以保留和读取信息,使其能够更好地处理时序数据中的长期依赖关系。遗忘门可以选择性地遗忘先前的信息,输入门可以添加新的信息,输出门控制输出的信息。
4.2.1 数据处理
此部分与TCN相同,采取前80%为训练数据,后20%为测试集,时间窗口大小为16
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
data = pd.read_excel("data.xlsx")
empty = 192 # 有缺失部分的长度
side = 587 # 整个已知数据的长度
seq_len = 10
batch_size = 64
# 提取全部列名
col_names = data.columns.values.tolist()
col_names = [col_names[i] for i in range(1, len(col_names))]
for col in col_names:
data[col] = pd.to_numeric(data[col], errors='coerce').astype(float)
# print(data)
data_list = np.array(data[col_names].values.tolist())
# print(data_list)
data_list = data_list[:data_list.shape[0]-6,:]
# print(data_list)
# print(type(data_list[1][1]))
scaler = StandardScaler()
data_list_scaled = scaler.fit_transform(data_list)
data_scaled = pd.DataFrame(data_list_scaled, columns=col_names)
def get_data():
return data_list
def get_data_scaled():
data_list_scaled[np.isnan(data_list_scaled)] = 0
# print(data_list_scaled)
return data_list_scaled[192:588], data_list_scaled
def plot(prediction, label_test):
plt.figure()
f,ax = plt.subplots(nrows=3,ncols=3,figsize=(10, 10))
for i in range(3):
for j in range(3):
ax[i,j].plot(label_test[:,3 * i + j],'b-', label = 'true')
ax[i,j].plot(prediction[:,3 * i + j],'r-', label = 'predictions')
ax[i,j].set_title(col_names[3 * i + j])
ax[i,j].legend()
plt.tight_layout()
plt.show()
def plot_loss(train_loss):
plt.figure()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('Loss-Rate')
temp_list = []
for i in range(len(train_loss)):
temp_list.append(train_loss[i].to('cpu').detach().numpy())
plt.plot([i for i in range(len(train_loss))], temp_list, 'b-', label=u'train_loss')
plt.legend()
plt.show()
def create_sliding_window(data, seq_len, test=False):
"""
## 创建滑动窗口,生成输入序列和对应的目标值。
参数:
- data: 输入的时序数据,形状为 (num_samples, num_features)
- seq_len: 滑动窗口的大小
返回:
- X: 输入序列,形状为 (num_samples - seq_len, seq_len, num_features)
- y: 目标值,形状为 (num_samples - seq_len, num_features)
"""
X, y = [], []
num_samples, num_features = data.shape
for i in range(num_samples - seq_len):
window = data[i : i + seq_len, :]
target = data[i + seq_len, :]
X.append(window)
y.append(target)
if test:
X.append(X[len(X)-1])
return np.array(X), np.array(y)
def inverse_scale(data):
return scaler.inverse_transform(data)
4.2.2 模型定义
import torch
import torch.nn as nn
import torch.optim as optim
import time
# 定义多层LSTM模型
class myLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers=2, output_size=9):
super(myLSTM, self).__init__()
# self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.lstm_layers = nn.ModuleList([
nn.LSTM(input_size=input_size if i == 0 else hidden_size,
hidden_size=hidden_size,
batch_first=True)
for i in range(num_layers)
])
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
for lstm_layer in self.lstm_layers:
x, _ = lstm_layer(x)
if len(x.shape) == 3:
output = self.fc(x[:, -1, :]) # 取最后一个时间步的输出
return output
else:
return x
def train_epoch(model, X_train, y_train, epochs=10, lr=0.001,
criterion=nn.MSELoss(), optimizer=None):
if optimizer == None:
optimizer = optim.Adam(model.parameters(), lr=lr)
print(model)
# 训练模型
train_loss = []
t1 = time.time()
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
train_loss.append(loss)
if (epoch + 1) % 5 == 0:
print(f'Epoch {epoch + 1}/{epochs}, Loss: {loss.item()}')
if (epoch + 1) % 20 == 0:
t2 = time.time()
print('当前耗时:{:.2f}s'.format(t2-t1))
return train_loss
# X_train 的形状为 (samples, time_steps, features)
# y_train 的形状为 (samples, num_targets)
4.2.3 模型训练及性能表现
相关参数:LSTM层数:3,隐藏层大小:2048,学习率:0.0005,训练轮数:400轮
import torch
import numpy as np
import matplotlib.pyplot as plt
ign_data, _ = get_data_scaled()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = 'cpu'
# ign_data.shape=(396, 9)
# 超参数
input_size = 9 # 每个时间步的特征数:9
hidden_size = 2048 # 隐藏层大小
output_size = 9 # 输出特征数
epochs = 400 # 轮数
lr = 0.0005 # learing rate
num_layers = 3
model = myLSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, output_size=output_size).to(device)
seq_len = 16 # 暂定窗口为16
X_, y_ = create_sliding_window(ign_data, seq_len=seq_len)
split_rate = 0.8
split_idx = X_.shape[0]*split_rate
split_idx = round(split_idx)
# X_train = torch.tensor(X_, dtype=torch.float32)
# y_train = torch.tensor(y_, dtype=torch.float32)
X_train = torch.tensor(X_[:split_idx,:,:], dtype=torch.float32)
y_train = torch.tensor(y_[:split_idx,:], dtype=torch.float32)
X_test = torch.tensor(X_[split_idx:,:,:], dtype=torch.float32)
y_test = torch.tensor(y_[split_idx:,:], dtype=torch.float32)
# X_test = torch.tensor(ign_data[split_idx:,:,:], dtype=torch.float32)
# y_test = torch.tensor(ign_data[split_idx:,:], dtype=torch.float32)
# 训练模型
train_loss = train_epoch(model, X_train.to(device), y_train.to(device), epochs=epochs, lr=lr)
# 保存模型
torch.save(model.state_dict(),'LSTM-hidden2048-3-copy')
plot_loss(train_loss)
model.eval()
with torch.no_grad():
predictions = model(X_test.to(device))
predictions = predictions.to('cpu').numpy()
# print(predictions)
plot(prediction=predictions, label_test=y_test.numpy())
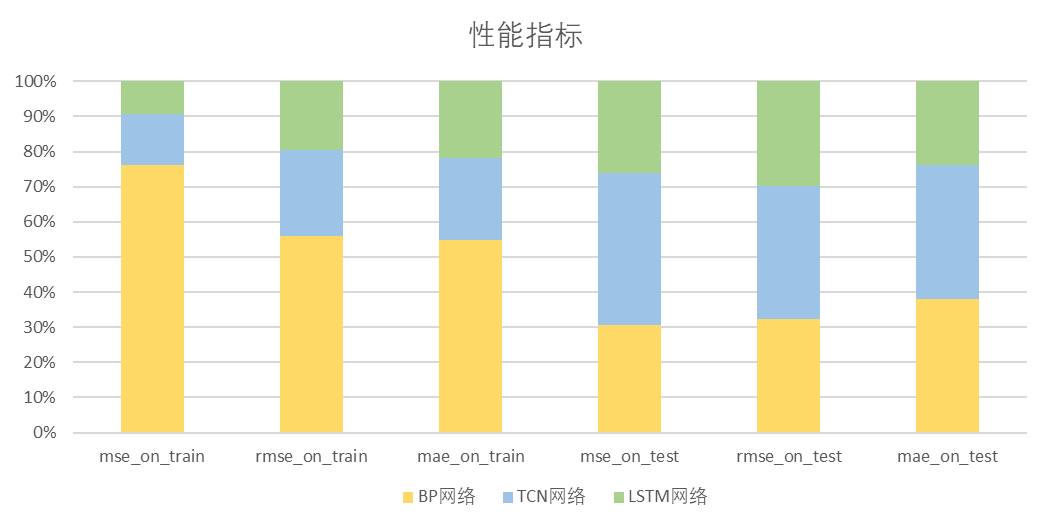
5. 实验结果