一种通过增强的面部边界实现精确面部表示的多级人脸超分辨率
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 文献阅读:一种通过增强的面部边界实现精确面部表示的多级人脸超分辨率
- 二、使用步骤
-
- 1、研究背景
- 2、方法提出
- 3、相关方法
-
- 3.1、FSR网络结构
- 3.2、多阶段FSR网络结构
- 4、实验工作
- 5、方法比较
- LSTM代码学习
-
- 2.1、什么是LSTM
- 2.2、LSTM的处理过程
- 2.3、LSTM代码分析
- 总结
摘要
本周主要阅读了2020CVPR的文章,一种通过增强的面部边界实现精确面部表示的多级人脸超分辨率,该论文提出了一种创新的MSFSR模型,旨在提高人脸超分辨率的精度和稳定性。通过多阶段处理和面部边界的增强,提高超分辨率模型对人脸的精细特征的重建能力,该模型能够更好地捕捉和处理人脸的精细特征和表情变化,从而在人脸超分辨率任务中取得更好的性能。除此之外,我还学习复习了LSTM的相关知识,并通过其实现过程来进行代码的学习。
Abstract
This week, I mainly read the articles of CVPR 2020. One of them is a multi-level face super-resolution method that achieves accurate facial representation through enhanced facial boundaries. This paper proposed an innovative MSFSR model to improve the precision and stability of face super-resolution. Through multi-stage processing and facial boundary enhancement, the model enhances the reconstruction ability of fine features of faces by super-resolution models. The model can better capture and process fine features and expressions of faces, achieving better performance in face super-resolution tasks. Besides, I also reviewed the relevant knowledge of LSTM and learned the code through its implementation process.
文献阅读:一种通过增强的面部边界实现精确面部表示的多级人脸超分辨率
Title: MSFSR: A Multi-Stage Face Super-Resolution With Accurate Facial Representation via Enhanced Facial Boundaries
Author:Bingfan Zhu , Yanchao Yang , Xulong Wang , Youyi Zheng† , Leonidas Guibas
From:2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
二、使用步骤
1、研究背景
FSRNet是基于结构先验知识的人脸超分辨率算法的经典之作。它首次提出采用双分支网络结构,通过常规图像超分辨率放大分支和人脸先验提取分支,从低分辨率图像中挖掘不同层次的特征,帮助网络进行超分辨率放大。通过显式引入外部人脸结构先验知识(人脸解析图和人脸关键点),不仅提升了输出高分辨率人脸图像的分辨率;而且也不需要对人脸图像进行复杂的预对齐工作。受益于上述优点,FSRNet在一段时间内成为基于结构先验知识的FSR算法中最出色的一种。但是FSRNet存在以下缺点:公开人脸数据集中几乎没有提供高质量的人脸解析图,而人脸解析图的标注是昂贵且复杂的,这使得这类方法的研究变得非常困难;尽管我们可以采用公开数据集中普遍提供的人脸关键点作为外部人脸结构先验知识,但是何种密度的人脸关键点能够最大化FSR网络的重建性能也是未知的。
2、方法提出
为了解决FSRNet所具有的小毛病,提出了一种采用人脸边缘线作为人脸结构表示方式,该方法能够以极低成本扩充人脸数据集规模,更能摆脱了关键点密度的约束,直接用轮廓线代替点。人脸边缘线不仅仅只是一种中间表示方式,其本身就对于人脸几何结构进行了建模,是一种良好的人脸结构表示方式。一方面,由于边缘线的连续性,无论人脸关键点定义密度如何,表示同一五官特征的关键点都会落在11条人脸边缘线上。此时我们就将一个复杂的预测各个数据集不同人脸关键点的任务转换为了一个相对简单的预测人脸边缘线的任务。另一方面,人脸边缘线本文就是对人脸结构的一种较为完备的建模。其相较于人脸关键点,包含了更完整的人脸结构信息;相较于人脸解析图,对于五官内部的结构特征(如鼻翼)有更精确的刻画。
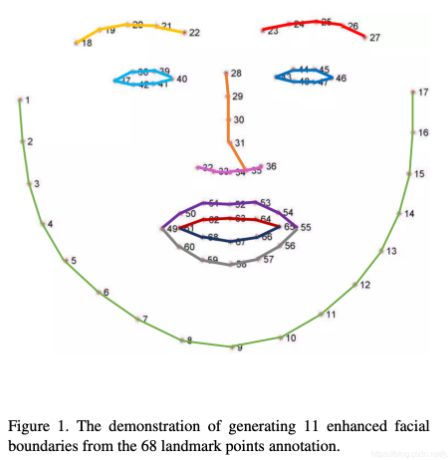
3、相关方法
3.1、FSR网络结构
现有的双分支网络设计通过额外分支显式地引入人脸结构先验信息,这种结构不仅直观且有效。但是,双分支网络内部本身耦合较紧密,很难通过对每部分单独优化实现整体的优化。因此,对现有的FSR网络结构进行了重思考,采用三大模块作为基本组件,通过灵活的连接,组成一个完整的FSR网络。三大基础模块按照功能进行划分:基础上采样模块(Basic Upscale Module,BUM),边缘预测模块(Boundary Estimation Module,BEM),边缘融合模块(Boundary Fusion Module,BFM)。
其中,基础上采样模块将输入的低分辨率图片进行了尺度放大。这里的基础上采样模块可以被替换为任意通用图像超分辨率算法,这样FSR算法就能够充分受益于通用图像超分辨率算法的进化。边缘预测模块则是采用漏斗结构,将经过了基础上采样模块后的大尺寸图像中人脸边缘线的可能位置进行预测。而边缘融合模块则是将大尺寸图像中的特征信息和边缘预测模块中的人脸边缘线信息进行加权融合,用以最终生成人脸图像。
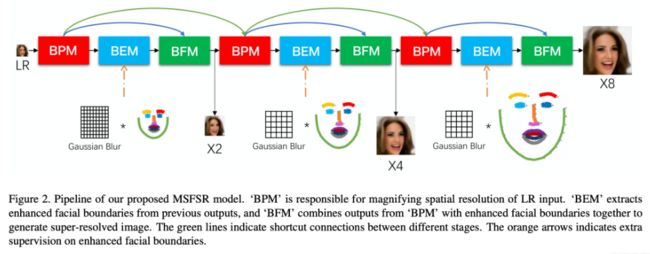
3.2、多阶段FSR网络结构
现有的单阶段直接放大的FSR网络在处理超过8倍的上采样操作时,性能会出现明显的下降。正因为在上一步,我们将整个FSR网络的组成分解为了三个模块的组合与连接,我们可以灵活的将一个单阶段直接放大的网络改进为多阶段渐进放大的网络。多阶段的FSR网络不单单是简单的将模块进行级联链接,同时还需要考虑到不同阶段网络处理的任务难度的差异。在网络的初始阶段,图像的分辨率较小,边缘预测模块预测精确的人脸边缘线的难度较大,因此直接施加细粒度的人脸边缘线会导致网络难以收敛;伴随着网络的深度增加,图像的尺寸也逐级增大,此时我们需要逐渐的约束人脸边缘线的粒度,从粗粒度的边缘线变为细粒度的人脸边缘线,进一步约束网络进行图像的”精修“。
于是提出这样的网络设计,一个从粗到细的边缘线监督机制,通过人脸边缘线粒度进行数值控制,探究了不同阶段人脸边缘线的最佳设置,充分提升了多阶段网络的性能。同时,在多阶段网络重建过程中,我们还尝试了在网络的不同阶段直接使用生成对抗网络结构来逐级优化各个阶段的输出结果。但是,试验效果不如人意。主要原因在于:网络的前期阶段,图像的分辨率尺寸较小,直接采用生成对抗网络会给重建的图像引入过大的额外噪声,不利于下一级网络的重建。因此,我们只在多阶段网络的最后一个阶段引入生成对抗网络结构,生成更加逼真的人脸图像。
4、实验工作
首先进行了人脸边缘线有效性试验,在相同的试验设置下,我们对人脸边缘线、人脸解析图和不同标注密度的人脸关键点进行了试验比较。试验结果如下图所示。从结果中体现了一些有趣的结论:横向对比5个人脸关键点的FSR算法结果和81个人脸关键点的FSR算法结果,可以看出:当人脸关键点的数目增加,FSR网络的性能逐步提升。进一步对比人脸关键点和人脸解析图作为人脸结构先验知识的FSR算法,验证了引入的外部人脸表示所携带的人脸结构语义信息越多,FSR网络的性能越好。横向对比81个人脸关键点和194个人脸关键点的FSR网络的性能表现,本文发现:更加密集的人脸关键点信息并不能有效提升FSR算法的性能。
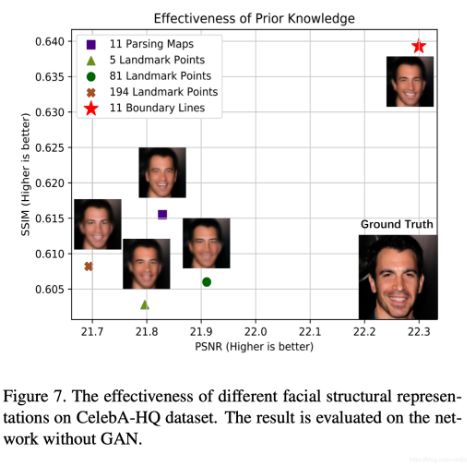
5、方法比较
将提出的方法与近两年的其他网络进行了比较。为了全面展示我们算法的性能,选取了EDSR,EnhanceNet, ESRGA,URDGN, FSRNet,PFSR作为比较。这里我简单对于几个客观指标进行一下简单介绍:几个客观评价指标中,PSNR,SSIM指标都是越高越好;PI(Perception Index)指标是越低越好。从结果中可以看出,我们的算法在客观指标上,也优于其他竞争对手。同时,这也是首次在评估人脸图像重建效果的过程中采用了公开的人脸对比API(这里用的是旷场的Face++人脸对比API)。提出的算法不仅在通用图像质量评估指标上领先,同时重建的图像与真实人脸图像的身份相似度也保持了极高的相似度,证明该算法在身份保真度上也遥遥领先。

LSTM代码学习
2.1、什么是LSTM
LSTM(Long Short-Term Memory)是一种长短期记忆网络,是一种特殊的RNN(循环神经网络)。与传统的RNN相比,LSTM更加适用于处理和预测时间序列中间隔较长的重要事件。LSTM通过引入记忆细胞、输入门、输出门和遗忘门的概念,能够有效地解决长序列问题。记忆细胞负责保存重要信息,输入门决定要不要将当前输入信息写入记忆细胞,遗忘门决定要不要遗忘记忆细胞中的信息,输出门决定要不要将记忆细胞的信息作为当前的输出。这些门的控制能够有效地捕捉序列中重要的长时间依赖性,并且能够解决梯度问题。
2.2、LSTM的处理过程
LSTM的处理过程包括以下步骤:
- 输入门(InputGate):这一步决定了当前时刻网络将如何接收输入信息。首先,输入门会接收当前时刻的输入数据和前一时刻的隐藏层状态。然后,通过一个sigmoid函数,输入门会决定哪些信息将被更新。
- 遗忘门(ForgetGate):这一步决定了哪些信息将被遗忘。遗忘门会接收前一时刻的隐藏层状态和当前时刻的输入数据,然后通过一个sigmoid函数,遗忘门会决定哪些信息将被丢弃。
- 记忆单元状态更新:记忆单元状态更新是在输入门和遗忘门的基础上进行的。首先,通过结合遗忘门的输出和前一时刻的记忆单元状态,可以得到一个候选记忆单元状态。然后,结合输入门的输出和当前时刻的输入数据,可以得到一个更新后的记忆单元状态。
- 输出门(OutputGate):这一步决定了当前时刻网络的输出。输出门接收当前时刻的隐藏层状态和当前时刻的输入数据,然后通过一个sigmoid函数,输出门会决定哪些信息将被作为输出。
- 输出:最后,通过将tanh函数与输出门的输出相乘,可以得到最终的隐藏层状态。
如下图所示,c类似于长期记忆,h类似于短期记忆。我们使用输入x和h来更新长期内存。在更新中,c的一些特征通过遗忘门f被清除,并且一些特征i,通过门g被添加,接着新的短期存储器是长期存储器的tanh乘以输出门o。
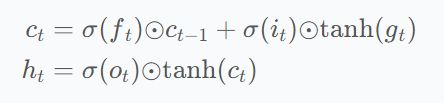
2.3、LSTM代码分析
# 创建LSTM模型
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
#定义类的构造函数,用于初始化模型的参数。参数包括输入特征数、隐藏层大小、LSTM层数和输出大小。
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
#创建一个LSTM层,输入特征数为input_size,隐藏层大小为hidden_size,LSTM层数为num_layers。
#参数batch_first=True表示输入张量的形状为(batch_size, seq_len, feature_size)。
self.fc = nn.Linear(hidden_size, output_size)
#创建一个全连接层,输入大小为隐藏层大小hidden_size,输出大小为output_size。
def forward(self, x):
# 初始化隐藏状态和细胞状态
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
#初始化隐藏状态和细胞状态,形状分别为[层数, batch_size, 隐藏层大小],并移动到与输入数据x相同的设备上
# LSTM层输出
out, _ = self.lstm(x, (h0, c0))
# 取最后一个时间步的输出
out = self.fc(out[:, -1, :])
#取LSTM层输出out的最后一个时间步的输出,并将其传递给全连接层。全连接层的输出即为模型的最终输出。
return out
总结
本周通过阅读论文,一种通过增强的面部边界实现精确面部表示的多级人脸超分辨率,了解了基于结构先验知识的人脸超分辨率算法的基础知识,并且看到了新的增强的面部边界实现的方法,能够更好地捕捉和处理人脸的精细特征和表情变化。其次本周因为配置Linux的环境导致花费了大量的时间,没能将LSTM进行训练测试,只进行了简单的代码学习,未来会继续加快进度。