ICASSP2024 | BS-PLCNet: 基于多任务学习框架和多判别器的分频带丢包隐藏网络
随着互联网和通讯技术的发展,实时音频流传输已经成为网络通信的一个非常重要的部分。但由于网络拥堵、带宽限制、硬件故障等各种因素干扰,音频数据包在传输过程中可能会丢失,对语音通信的质量产生严重影响,造成用户体验下降。语音丢包补偿(Packet Loss Concealment,PLC)又称丢包隐藏,旨在通过各种方式尽可能地恢复或掩饰丢失的数据包,从而保持语音通信的连续性和清晰度。随着硬件和算法的进步与深度学习技术的发展,基于数据驱动的神经网络方法成为研究热点,这种方法可以显著提高长丢包和高丢包率下的语音质量。基于卷积神经网络和循环神经网络构建的深度PLC方法以及可以在16k Hz采样率实现低延迟的实时丢包补偿,且能够恢复的丢包长度与生成音频的质量都超越了传统算法。然而,全带音频(48k Hz采样率)带来的高计算复杂度,针对全带音频的低延迟实时深度丢包补偿仍是一个具有挑战性的课题。
近期,西工大音频语音(ASLP@NPU)与字节跳动合作论文“BS-PLCNet: Band-split Packet Loss Concealment Network with Multi-task Learning Framework and Multi-discriminators”被语音领域顶级国际会议ICASSP 2024接收。该论文使用频带分割的丢包隐藏网络,将全带信号按照频率分为0-8k Hz的宽带和8-24k Hz的高频带部分,分别用门控卷级循环网络和简单的GRU网络处理。为了提高恢复音频连续性与质量,引入基频预测、语言感知的辅助任务,同时结合多判别器的生成对抗训练。所提出的模型在ICASSP 2024 丢包隐藏挑战赛上获得冠军(并列)。

论文题目:BS-PLCNet: Band-split Packet Loss Concealment Network with Multi-task Learning Framework and Multi-discriminators
合作单位:字节跳动
作者列表:张子晗,孙佳耀,夏咸军,黄传增,林丹峰,谢磊
论文原文:https://arxiv.org/abs/2401.03687
样例网址:https://zzhdzdz.github.io/BS-PLCNet

图1 发表论文截图
背景动机
近年来,网络电话语音(VoIP)通信已经成为我们日常生活中非常重要的一部分。随着实时通信(RTC)技术的发展,VoIP的质量得到了很大的提高。但是由于网络环境的原因,可能会出现丢包现象,导致语音信号暂时中断,从而影响语音质量和可懂度。语音丢包补偿(Packet Loss Concealment,PLC)或丢包隐藏技术是这类问题的解决方案。近年来,深度学习在丢包隐藏方面显示出巨大的潜力。然而,长间隙丢包和高质量的音频恢复仍然对模型的性能提出了挑战。作为ICASSP 2024 信号处理挑战赛的旗舰赛事,音频深度丢包隐藏挑战赛旨在带动探索这些问题,同时将挑战难度由带宽提高到全频带信号。
在此次竞赛中,我们提出了一种频带分割的丢包隐藏网络(BS-PLCNet)。具体来说,我们将全频带信号分为宽带(0-8kHz)和高频带(8-24kHz)。宽带信号由门控卷积循环网络(GCRN)处理,而高频段信号由简单的GRU网络处理。为了保证恢复高质量语音和保持对语音识别(ASR)的兼容性,我们采用了基频预测、语言感知的多任务学习(MTL)框架和多鉴别器的生成对抗训练方案。我们提出的方案在此次挑战赛中获得冠军。
本文方法
模型结构
为了更好地捕获音频中主导的频率和能量,生成更高质量的音频,我们设计了一种分频带(Bandsplit -- BS)的频域模型BS-PLCNet。傅立叶变换后的丢包音频经过缩放因子为0.5的幅度谱压缩,与丢包标志位拼接作为网络的输入。我们将全带信号分为0-8kHz的宽带和8-24kHz的高频带。考虑到谐波结构主要存在于宽带,而人类听觉系统对宽带更为敏感,我们使用基于GCRN的模块对宽带进行处理。对于高频段,我们使用轻量级的GRU网络处理。模型结构如图1所示。

图3 BS-PLCNet总体结构(a),时频卷积模块(b)和基频预测模块(c)
宽带模块的主干基于我们以前的工作[1],由4个编码器层、F-T-LSTM瓶颈层和4个解码器层组成。编解码器部分每层由门控卷积和时频空洞卷积模块组成。时频卷积模块通过时间维度和频率维度的膨胀卷积提供较长的时频感受野,来学习时频相关信息。我们还增加了基频预测模块来提高丢包位置信号的连续性与相关性。该模块仅在训练期间启用,用于计算损失函数指导模型参数更新,不会引入额外的推理消耗。高频段模块包括二维卷积(Conv2d)层、ELU层、batchnorm层和GRU层。
多任务框架
我们使用了多任务学习框架,其中基频预测和语言感知被作为丢包隐藏的辅助任务。基频预测模块的结构如图1(c)所示。与[2]一样,我们使用频率特征线性调制(F-FiLM)作为基频预测模块。为保证因果性,整个结构在频率和通道维度循环,仅使用当前一帧的信息估计基频。输入特征为F-T-GRU后的瓶颈层特征,经过频率轴的池化,LSTM专注处理通道维信息,使用线性调制的方式,输出一个帧级的基频预测值。
语言感知(Linguistic Aware)任务借助Whisper[3]的编码层,模型输出的丢包补偿后音频与未丢包音频同时经过Whisper,希望利用大型预训练模型的语言提取能力,获得对ASR任务友好的模型。丢包补偿的主任务使用幅谱压缩相位感知(PLCPA)损失函数,基频预测与语言感知的辅助任务都采用基于L1 loss的深度特征损失。
多判别器
为了提高生成音频质量,我们联合应用了频域多分辨率判别器[4]、时域多周期判别器[5]和MetricGAN判别器[6]。频域多分辨率判别器使用不同窗长、窗移的stft对时域波形进行变换,可以从不同的分辨率对生成音频进行判别。多周期判别器的重点是将一维样本点序列以一定周期折叠为二维平面,然后应用二维卷积进行处理。MetricGAN判别器使用网络估计PESQ,再与PESQ最大值计算MSE损失。
实验
数据与设置
实验数据来自第五届DNS挑战赛的48k数据,仅使用英文部分,原数据约300小时。训练期间动态生成丢包训练数据。采用如图2所示的Gilbert-Elliott Channel Model[7],控制期望丢包率在40%以下。窗长和帧移分别为20 ms和10 ms,采用960点STFT。宽带模块的详细信息请参见[1]。对于高频段模块,第一个Conv2D的输出通道为128, GRU层的隐藏状态为128。最后,如果丢失的包帧数超过7,则对频谱进行增益衰减操作。

图4 丢包仿真模型:Gilbert-Elliott Channel Model
实验结果
为了验证模型的性能,我们分别在2024年和2022年PLC竞赛盲测集上计算语音MOS和WER,其中WER采用Wenet工具包测试。我们得出以下实验结论。
-
基频预测的应用有利于提高语音质量和降低WER。
-
虽然使用Whisper loss并没有显著提高PLC MOS与DNS MOS,但它有效地降低了WER。
-
MetricGAN的使用也有效提高了语音质量。
我们提交的模型在挑战排名中获得第一(并列)。模型参数量为3.81M,RTF为0.26,在英特尔Xeon E5-2678 v3 @2.50GHz上使用单线程(由ONNX加速)测得。
表1.盲测集上的客观指标
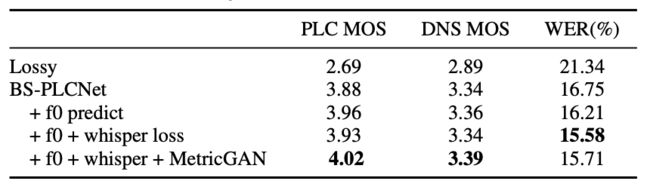
表2.竞赛主观测听得分与词正确率

参考文献
[1] J. Sun, D. Luo, Z. Li, J. Li, Y. Ju, and Y. Li, “Multi-task sub-band network for deep residual echo suppression,” in ICASSP, 2023.
[2] S. Zhang, Z. Wang, J. Sun, Y. Fu, B. Tian, Q. Fu, and L. Xie, “Multi-task deep residual echo suppression with echo-aware loss,” in ICASSP, 2022.
[3] Radford, Alec, et al. "Robust speech recognition via large-scale weak supervision." International Conference on Machine Learning. PMLR, 2023.
[4] Q. Tian, Y. Chen, Z. Zhang, H. Lu, L. Chen, L. Xie, and S. Liu, “Tfgan: Time and frequency domain based generative adversarial network for high-fidelity speech synthesis,” arXiv preprint arXiv:2011.12206, 2020.
[5] J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,” NIPS, 2020.
[6] S. Fu, C. Yu, T. Hsieh, P. Plantinga, M. Ravanelli, X. Lu, and Y. Tsao, “Metricgan+: An improved version of metricgan for speech enhancement,” Interspeech, 2021.
[7] M. Mushkin and I. Bar-David, “Capacity and coding for the gilbert-elliott channels,” IEEE Transactions on Information Theory, 1989.