MySQL学习记录
SQL语句
通用语法
在学习具体的SQL语句之前,先来了解一下SQL语言的同于语法。
1). SQL语句可以单行或多行书写,以分号结尾。
2). SQL语句可以使用空格/缩进来增强语句的可读性。
3). MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。
4). 注释:
- 单行注释:-- 注释内容 或 # 注释内容
- 多行注释:/* 注释内容 */
DCL
User
DCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库的访问权限。
查询所有用户和他们的访问权限
select * from mysql.user;
创建用户
CREATE USER ‘用户名’@‘主机名’ IDENTIFIED BY ‘密码’;
创建用户itcast, 只能够在当前主机localhost访问, 密码123456;
create user ‘itcast’@‘localhost’ identified by ‘123456’;
创建用户heima, 可以在任意主机访问该数据库, 密码123456;
create user ‘heima’@‘%’ identified by ‘123456’;
修改用户密码
ALTER USER ‘用户名’@‘主机名’ IDENTIFIED WITH mysql_native_password BY ‘新密码’;
删除用户
DROP USER ‘用户名’@‘主机名’ ;
查询权限
SHOW GRANTS FOR ‘用户名’@‘主机名’ ;
授予权限
GRANT 权限列表 ON 数据库名.表名 TO ‘用户名’@‘主机名’;
撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM ‘用户名’@‘主机名’;
注意事项
- 在MySQL中需要通过用户名@主机名的方式,来唯一标识一个用户。
- 主机名可以使用 % 通配。

DDL
User->schema and table
Data Definition Language,数据定义语言,用来定义数据库对象(数据库,表,字段) 。
类似于查看数据库,查看表,修改数据库名字,修改表属性等操作都是DDL操作。
但是由于非常不方便,而且现在的图形化MySQL操作界面非常发达,所以通常我们都选择使用图形化界面来操作数据库,感兴趣的可以了解一下DDL。
Schema操作
show databases ;
查看所有数据库
select database() ;选择数据库
create database [ if not exists ] 数据库名 [ default charset 字符集 ] [ collate 排序
规则 ] ;
创建数据库
drop database [ if exists ] 数据库名 ;
删除数据库
use 数据库名 ;
我们要操作某一个数据库下的表时,就需要通过该指令,切换到对应的数据库下,
table操作
show tables; 查看schema中所有table
desc 表名 ; 显示表结构
show create table 表名 ;查看建表语句
CREATE TABLE 表名( 字段1 字段1类型 [ COMMENT 字段1注释 ],
字段2 字段2类型 [COMMENT 字段2注释],
字段3 字段3类型 [COMMENT 字段3注释 ],
…
字段n 字段n类型 [COMMENT 字段n注释 ] )
[COMMENT 表注释 ] ;
[…] 内为可选参数,最后一个字段后面没有逗号
例如:
create table tb_user(
id int comment ‘编号’,
name varchar(50) comment ‘姓名’,
age int comment ‘年龄’,
gender varchar(1) comment ‘性别’
) comment ‘用户表’;
添加字段
ALTER TABLE 表名 ADD 字段名 类型 (长度) [ COMMENT 注释 ] [ 约束 ];
为emp表增加一个新的字段”昵称”为nickname,类型为varchar(20)
例如
ALTER TABLE emp ADD nickname varchar(20) COMMENT ‘昵称’;
修改数据类型
ALTER TABLE 表名 MODIFY 字段名 新数据类型 (长度)
修改字段名
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型 (长度) [ COMMENT 注释 ] [ 约束 ];
删除字段
ALTER TABLE 表名 DROP 字段名;
修改表名
ALTER TABLE 表名 RENAME TO 新表名;
删除表
DROP TABLE [ IF EXISTS ] 表名;
删除指定表, 并重新创建表
TRUNCATE TABLE 表名;
部分数据类型:

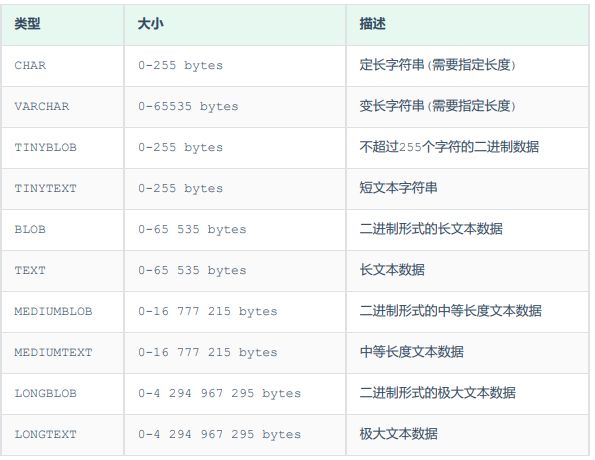

可以自己恰当的选择类型。
如:
1). 用户名 username ------> 长度不定, 最长不会超过50
username varchar(50)
2). 性别gender ---------> 存储值, 不是男,就是女
gender char(1)
3). 手机号 phone -------->固定长度为11
phone char(11)
4). 生日字段
birthday birthday date
5). 创建时间
createtime createtime datetime
DML
User->schema and table->data
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
给指定字段添加数据
INSERT INTO 表名 (字段名1, 字段名2, …) VALUES (值1, 值2, …);
例如
insert into employee(id,workno,name,gender,age,idcard,entrydate)
values(1,‘1’,‘Itcast’,‘男’,10,‘123456789012345678’,‘2000-01-01’);
查询表的前十行数据
select * from employee limit 10;
添加值
INSERT INTO 表名 VALUES (值1, 值2, …);
给employee表所有的字段添加数据
执行如下SQL,添加的年龄字段值为-1。
insert into employee(id,workno,name,gender,age,idcard,entrydate)
values(1,‘1’,‘Itcast’,‘男’,-1,‘24’,‘2000-01-01’);
批量添加
INSERT INTO 表名 (字段名1, 字段名2, …) VALUES (值1, 值2, …), (值1, 值2, …),
(值 1, 值2, …) ;
修改数据
UPDATE 表名 SET 字段名1 = 值1 , 字段名2 = 值2 , … [ WHERE 条件 ] ;
例如
update employee set name = ‘小昭’ , gender = ‘女’ where id = 1;
删除数据
DELETE FROM 表名 [ WHERE 条件 ] ;
例如
delete from employee where gender = ‘女’;
注意事项:
- INSERT指定的字段顺序需要与值的顺序是一一对应的。
- 字符串和日期型数据应该包含在引号中。
- DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数
据。 - DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即
可)。
DQL
User->schema and table->data->query command
DQL英文全称是Data Query Language(数据查询语言),数据查询语言,用来查询数据库中表的记录。
基本如下
SELECT 字段列表
FROM 表名列表
WHERE 条件列表
GROUP BY 分组字段列表
HAVING 分组后条件列表
ORDER BY 排序字段列表
LIMIT 分页参数
- 基本查询(不带任何条件)
- 条件查询(WHERE)
- 聚合函数(count、max、min、avg、sum)
- 分组查询(group by)
- 排序查询(order by)
- 分页查询(limit)
执行顺序
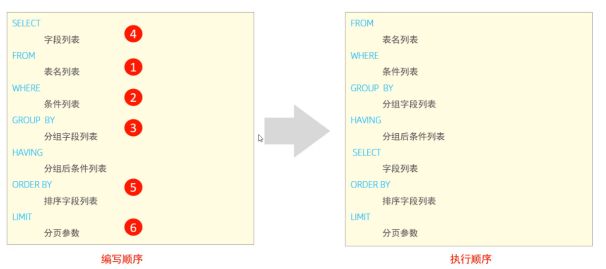
基本查询
查询结果别名化
SELECT 字段1 [ AS 别名1 ] , 字段2 [ AS 别名2 ] … FROM 表名;
查询某些字段
SELECT 字段1, 字段2, 字段3 … FROM 表名 ;
去重查询
SELECT DISTINCT 字段列表 FROM 表名
条件查询
SELECT 字段列表 FROM 表名 WHERE 条件列表 ;

例如
select * from emp where age between 15 and 20 and idcard like ‘%x’;
聚合函数
统计的是年龄15到20的idcard字段不为null的记录数
select count(idcard) from emp where age between 15 and 20;
统计该企业员工的平均年龄
select avg(age) from emp;
分组查询
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组 后过滤条件 ];
where与having区别
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
根据性别分组 , 统计男性员工 和 女性员工的平均年龄
select gender, avg(age) from emp group by gender ;
查询年龄小于45的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址
select workaddress, count(*) address_count from emp where age < 45
group by workaddress having address_count >= 3;
排序查询
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1 , 字段2 排序方式2 ;
根据年龄对公司的员工进行升序排序 , 年龄相同 , 再按照入职时间进行降序排序
select * from emp order by age asc , entrydate desc;
分页查询
这是物理硬分页,实际业务开发不考虑这种,对数据的IO次数太多了,我们通常用的是一下子查一堆,然后在缓存里实现分批次读取。
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数 ;
- 起始索引从0开始,起始索引 = (查询页码 - 1)* 每页显示记录数。
- 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT。
- 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10。
select * from emp limit 10,10;
联合查询
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
SELECT 字段列表 FROM 表A …
UNION [ ALL ]
SELECT 字段列表 FROM 表B …;
- 对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
- union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。
函数
提供了一些内置的数据操作方法,你也可以在java里实现后只用SQL
字符串函数
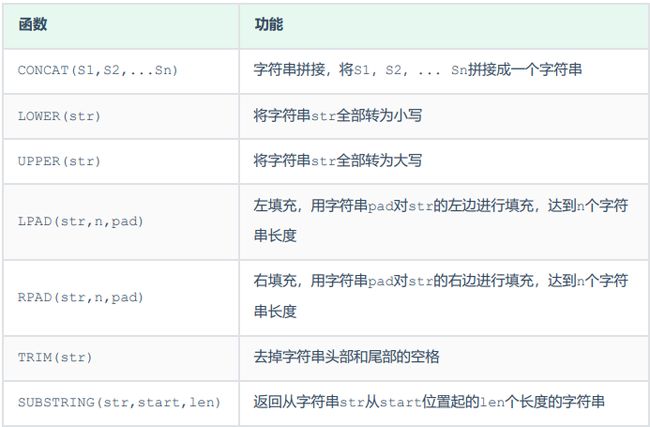

由于业务需求变更,企业员工的工号,统一为5位数,目前不足5位数的全部在前面补0。比如: 1号员工的工号应该为00001。
update emp set workno = lpad(workno, 5, ‘0’);
变更后:
数值函数
通过数据库的函数,生成一个六位数的随机验证码。
select lpad(round(rand()*1000000 , 0), 6, ‘0’);
日期函数

查询所有员工的入职天数,并根据入职天数倒序排序。
select name, datediff(curdate(), entrydate) as ‘entrydays’ from emp order by
entrydays desc;
流程函数
在SQL语句中实现条件筛选,从而提高语句的效率。我感觉这玩意儿不太常用,用DQL一样能达到效果。

查询emp表的员工姓名和工作地址 (北京/上海 ----> 一线城市 , 其他 ----> 二线城市)
select name, ( case workaddress when ‘北京’ then ‘一线城市’ when ‘上海’ then ‘一线城市’ else ‘二线城市’ end ) as ‘工作地址’ from emp;
select
id,
name,
(case when math >= 85 then '优秀' when math >=60 then '及格' else '不及格' end )
'数学',
(case when english >= 85 then '优秀' when english >=60 then '及格' else '不及格'
end ) '英语',
(case when chinese >= 85 then '优秀' when chinese >=60 then '及格' else '不及格'
end ) '语文'
from score;
约束
约束是作用于表中字段上的规则,用于限制存储在表中的数据。保证数据库中数据的正确、有效性和完整性。
字段约束
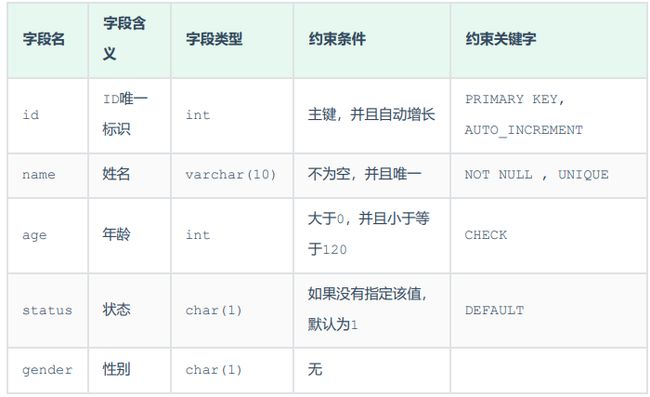
可用如下DDL语句生成。但是通常都是用图形化界面来快捷操作的。DDL语句基本已经用不到了。
CREATE TABLE tb_user(
id int AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一标识',
name varchar(10) NOT NULL UNIQUE COMMENT '姓名' ,
age int check (age > 0 && age <= 120) COMMENT '年龄' ,
status char(1) default '1' COMMENT '状态',
gender char(1) COMMENT '性别'
);
外键约束
添加主表
CREATE TABLE 表名(
字段名 数据类型,
...
[CONSTRAINT] [外键名称] FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名)
);
添加副表(推荐)
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名)
REFERENCES 主表 (主表字段名) ;
为emp表的dept_id字段添加外键约束,关联dept表的主键id。
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);
删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;

例如
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名
(主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;
多表
表之间存在:一对一,一对多,多对多的关系,查询时根据这些关系就可能会涉及多表查询。
比如看看某门课程都有哪些学生选了,某个部门都有哪些人员,基本信息表中的用户和特殊信息表中的用户。
多表连接查询的本质就是根据筛选后两个字段的笛卡尔积(卷积)查数据。
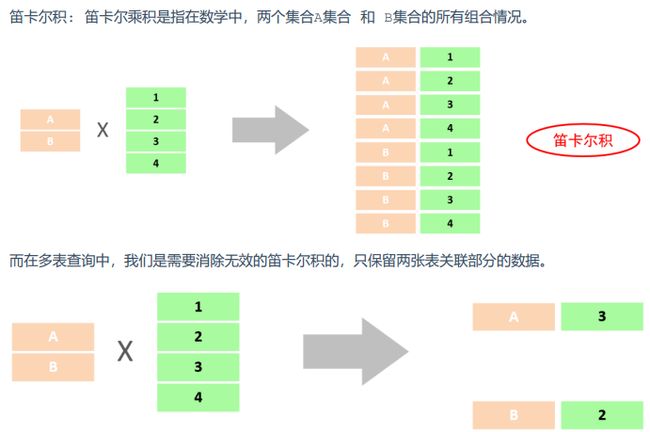
多表查询又按照不同的表连接方式,分为:内连接,外连接(左外,右外),自连接,
内连接
两表数据的交集。
隐式内连接
SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 … ;
.
select emp.name , dept.name from emp , dept where emp.dept_id = dept.id ;
显式内连接
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件 … ;
select e.name, d.name from emp e inner join dept d on e.dept_id = d.id;
外连接
左连接:右表全部数据然后关联上左表部分字段信息。
左外连接
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 … ;
查询emp表的所有数据, 和对应的部门信息
select e.*, d.name from emp e left join dept d on e.dept_id = d.id;
右外连接
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 … ;
select d., e. from emp e right outer join dept d on e.dept_id = d.id;
自内连接,自外连接
自连接只是作笛卡尔积的对象变了,变成自己和自己了
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 … ;
自内连接
查询员工 及其 所属领导的名字
select a.name , b.name from emp a , emp b where a.managerid = b.id;
自外连接
select a.name ‘员工’, b.name ‘领导’ from emp a left join emp b on a.managerid = b.id;
子查询
在结果集中查询,也就是SQL中嵌套了SELECT。

.根据嵌套的select返回的信息又可分为:标量子查询(返回一个值),列子查询(返回一列),行子查询(返回一行),表子查询
列子查询
根据部门ID, 查询员工信息
select * from emp where dept_id in (select id from dept where name = ‘销售部’ or name = ‘市场部’);
查询比 财务部 所有人工资都高的员工信息
select * from emp where salary > all ( select salary from emp where dept_id = (select id from dept where name = ‘财务部’) );
查询比研发部其中任意一人工资高的员工信息
select * from emp where salary > any ( select salary from emp where dept_id = (select id from dept where name = ‘研发部’) );
行子查询
查询与 “张无忌” 的薪资及直属领导相同的员工信息
select * from emp where (salary,managerid) = (select salary, managerid from emp where name = ‘张无忌’);
表子查询
select * from emp where (job,salary) in ( select job, salary from emp where name = ‘鹿杖客’ or name = ‘宋远桥’ );
事物
事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系
统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事物的四大特性:
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
-- 开启事务
start transaction;
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三的余额减少1000
update account set money = money - 1000 where name = '张三';
-- 3. 李四的余额增加1000
update account set money = money + 1000 where name = '李四';
-- 如果正常执行完毕, 则提交事务
commit;
-- 如果执行过程中报错, 则回滚事务
-- rollback;
事物并发问题
脏读
这里是指读的是其他事物还没提交的数据。
比如B要读,A要改。
A先把2000改成1000
B这时读,读到了1000.
但是A还没提交,没法保证一定修改成功,有可能出错回滚。
总之但凡读的是别的事物修改的数据,但是进行修改的事物还没提交,就是脏读。

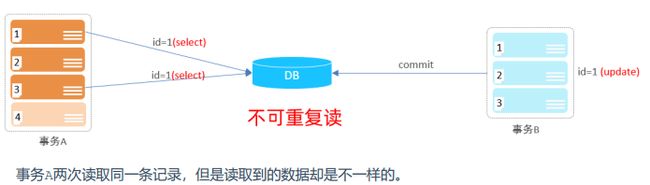
不可重复读
一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
读改读。
幻读
幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了 “幻影”。
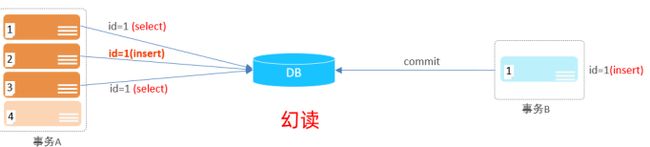
事物隔离
事物隔离用于解决事物并发问题,有不同的级别,级别越高隔离程度越强。
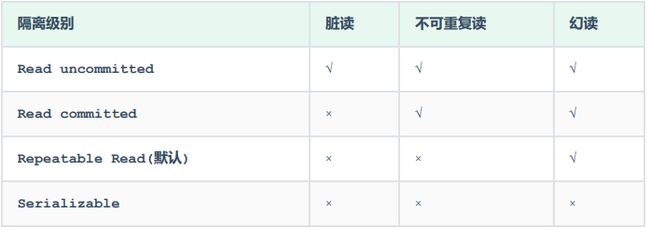
查看事物隔离级别
SELECT @@TRANSACTION_ISOLATION
设置事务隔离级别
SET [ SESSION | GLOBAL ] TRANSACTION ISOLATION LEVEL { READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE }
例如
set transaction isolation level serializable;
start transaction;
select * from tb_blog where id = 4;
commit;
视图
视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
视图只保存了查询的SQL逻辑,不保存查询结果。所以我们在创建视图的时候,主要的工作
就落在创建这条SQL查询语句上。
基本语法
创建
CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ]
例如
create or replace view stu_v_1 as select id,name from student where id <= 10;
查询
查看创建视图语句:SHOW CREATE VIEW 视图名称;
查看视图数据:SELECT * FROM 视图名称 … ;
例如
show create view stu_v_1;
例如
select * from stu_v_1;
select * from stu_v_1 where id < 3;
修改
方式一:CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [
CASCADED | LOCAL ] CHECK OPTION ]
例如
create or replace view stu_v_1 as select id,name,no from student where id <= 10;
方式二:ALTER VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ]CHECK OPTION ]
例如
alter view stu_v_1 as select id,name from student where id <= 10;
删除
DROP VIEW [IF EXISTS] 视图名称 [,视图名称] …
例如
drop view if exists stu_v_1;
检查选项
create or replace view stu_v_1 as select id,name from student where id <= 10 ;
select * from stu_v_1;
insert into stu_v_1 values(6,'Tom');
insert into stu_v_1 values(17,'Tom22');
执行上述的SQL,我们会发现,id为6和17的数据都是可以成功插入的。 但是我们执行查询,查询出来的数据,却没有id为17的记录。因为我们在创建视图的时候,指定的条件为 id<=10, id为17的数据,是不符合条件的,所以没有查询出来,但是这条数据确实是已经成功的插入到了基表中。
当使用WITH CHECK OPTION子句创建视图时,MySQL会通过视图检查正在更改的每个行,例如 插入,更新,删除,以使其符合视图的定义。
MySQL允许基于另一个视图创建视图,它还会检查依赖视图中的规则以保持一致性。为了确定检查的范围,mysql提供了两个选项: CASCADED 和 LOCAL,默认值为 CASCADED。
cascaded
比如,v2视图基于v1,设定v2是级联,那么检查v2时就不会检查是否符合v1的规则。
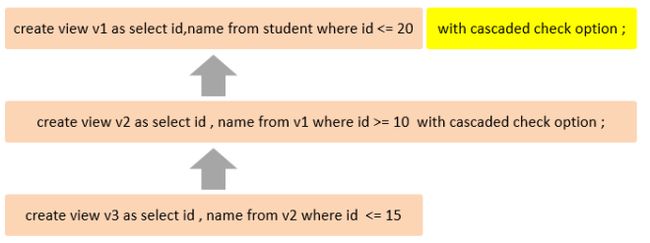
local
显然是不用去检查v1了。

视图的更新
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系。如果视图包含以下任何一项,则该视图不可更新:
- A. 聚合函数或窗口函数(SUM()、 MIN()、 MAX()、 COUNT()等)
- B. DISTINCT
- C. GROUP BY
- D. HAVING
- E. UNION 或者 UNION ALL
视图的作用
-
视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
-
数据库可以授权,但不能授权到数据库特定行和特定的列上。通过视图用户只能查询和修改他们所能见到的数据
-
视图可帮助用户屏蔽真实表结构变化带来的影响。
触发器
在insert/update/delete之前(BEFORE)或之后(AFTER),触
发并执行触发器中定义的SQL语句集合。
可以协助应用在数据库端确保数据的完整性, 日志记录 , 数据校验等操作 。
-
行级触发器(有一条数据被影响就触发一次),
-
表级触发器(一条SQL执行完才出发,多行数据被影响也只触发一次)。
-
使用old和new来引用触发器中变化的记录内容。
基本语法
创建
CREATE TRIGGER trigger_name
BEFORE/AFTER INSERT/UPDATE/DELETE ON tbl_name FOR EACH ROW -- 行级触发器
BEGIN
trigger_stmt ;
END;
查看
SHOW TRIGGERS ;
删除
DROP TRIGGER [schema_name.]trigger_name ;
例如
定义插入触发器
create trigger tb_user_insert_trigger
after insert on tb_user for each row
begin
insert into user_logs(id, operation, operate_time, operate_id, operate_params)
VALUES
(null, 'insert', now(), new.id, concat('插入的数据内容为: id=',new.id,',name=',new.name, ', phone=', NEW.phone, ', email=', NEW.email, ', profession=', NEW.profession));
end;
插入操作
-- 查看
show triggers ;
-- 插入数据到tb_user
insert into tb_user(id, name, phone, email, profession, age, gender, status, createtime) VALUES (26,'三子','18809091212','[email protected]','软件工程',23,'1','1',now());
定义修改触发器
create trigger tb_user_update_trigger
after update on tb_user for each row
begin
insert into user_logs(id, operation, operate_time, operate_id, operate_params)
VALUES
(null, 'update', now(), new.id,
concat('更新之前的数据: id=',old.id,',name=',old.name, ', phone=',old.phone, ', email=', old.email, ', profession=', old.profession,' | 更新之后的数据: id=',new.id,',name=',new.name, ', phone=',NEW.phone, ', email=', NEW.email, ', profession=', NEW.profession));
end;
修改操作
-- 查看
show triggers ;
-- 更新
update tb_user set profession = '会计' where id = 23;
update tb_user set profession = '会计' where id <= 5;
这里concat函数就是把多个变量拼接为一个字符串