[TOC]
1. Redis 被当做缓存使用
当Redis被当做缓存来使用,当你新增数据时,让它自动地回收旧数据是件很方便的事情。这个行为在开发者社区非常有名,因为它是流行的memcached系统的默认行为。
LRU是Redis唯一支持的回收方法。
2. LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
----百度百科
主存容量远大于CPU缓存,磁盘容量远大于主存,因此无论是哪一层次的缓存都面临一个同样的问题:当容量有限的缓存的空闲空间全部用完后,又有新的内容需要添加进缓存时,如何挑选并舍弃原有的部分内容,从而腾出空间放入这些新的内容。解决这个问题的算法有几种,如最久未使用算法(LFU)、先进先出算法(FIFO)、最近最少使用算法(LRU)、非最近使用算法(NMRU)等,这些算法在不同层次的缓存上执行时拥有不同的效率和代价,需根据具体场合选择最合适的一种。
----维基百科
通俗理解就是哪个缓存最近被使用的最少,就应该丢弃。
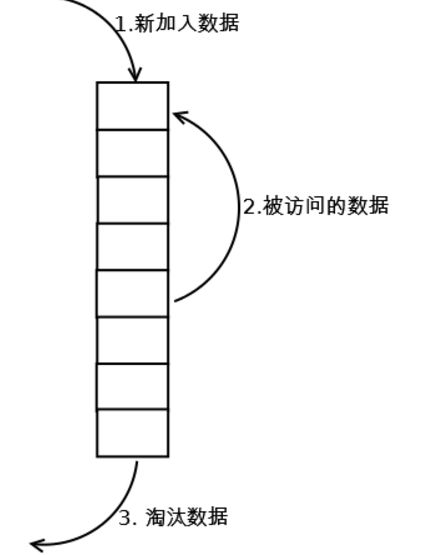
2.1 LRU算法
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
一个缓存队列。
-
原理:
- 新数据放到队列头
- 每当缓存被命中,将缓存移动到队列头
- 丢弃数据总是从队列尾部开始
-
命中率:
当存在批量的操作时,容易造成LRU命中率下降,造成存储污染。
比如一直都是访问1,2,3.如果有一个后台任务,将4,5,6扫描了一次,此时,如果需要丢弃,就会将热点缓存丢弃。造成缓存污染。
复杂度:简单
消耗:较高,命中需要遍历队列,命中需要做元素的转移。
2.2 LRU-K算法
在2.1中的LRU算法是,每当缓存被命中,就移动到头部。而LRU-K是指,当缓存被命中K次时,才会做元素的转移。
其核心思想是,命中一次可能不太可靠,需要命中指定的次数,才能被认为是热点缓存。
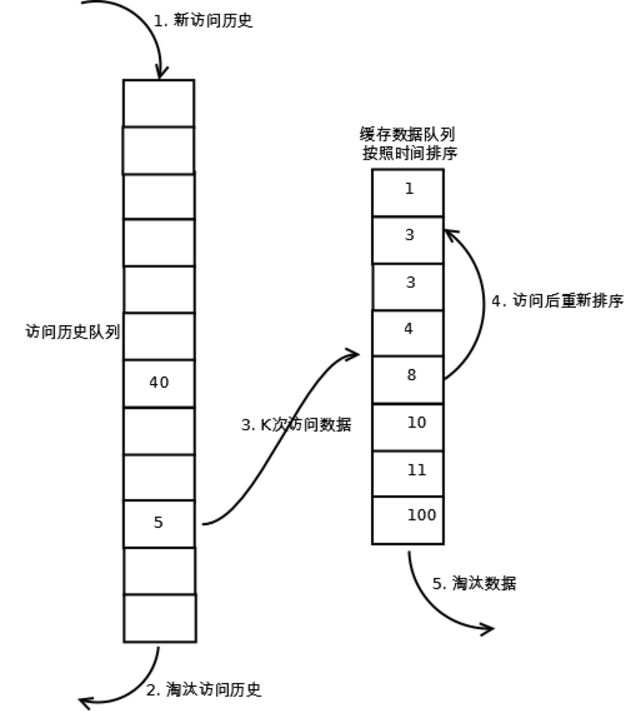
相比LRU算法,LRU-K需要额外维护一个队列==历史访问队列==。
一个缓存队列,一个缓存访问历史队列。
-
原理:
- 缓存数据第一次被命中,将命中次数++
- 当命中次数达到K,将缓存数据转移到缓存队列
- 丢弃数据总是从缓存队列的尾部开始
 img
img 命中率:因为LRU-K算法能在一定程度上去除突发或者批量操作的干扰,所以命中率比LRU算法要高。
复杂度:多维护一个队列,需要额外的成本。
消耗:LRU-K可以选择即时转移元素,或者丢弃时转移,在转移的时候,有内存消耗。
2.3 LRU-Two queues
LRU-Two queues类似LRU-2.区别在于将缓存访问历史队列(不是缓存数据队列)换成FIFO缓存队列。
所以LRU-T算法中,有两个缓存队列:FIFO缓存队列和LRU缓存队列。
缓存数据第一次被命中时,放入FIFO缓存队列;如果缓存数据第二次被命中,放入LRU缓存队列。
这两个缓存队列各自按照自己的缓存数据淘汰策略进行替换缓存。
- 原理:
- 新访问数据放入FIFO缓存队列
- FIFO中的缓存数据被再次命中,那么转移到LRU缓存队列中
- 如果LRU缓存队列中的缓存数据被命中,那么就将缓存数据转移到LRU队列头部
- 丢弃数据从LRU或者FIFO队列的尾部开始
- 命中率:LRU-T算法的命中率高于LRU算法,在一定程度上也高于LRU-K算法。
- 复杂度:两个队列,不过每个单个队列都比较简单
- 消耗:FIFO和LRU消耗总和

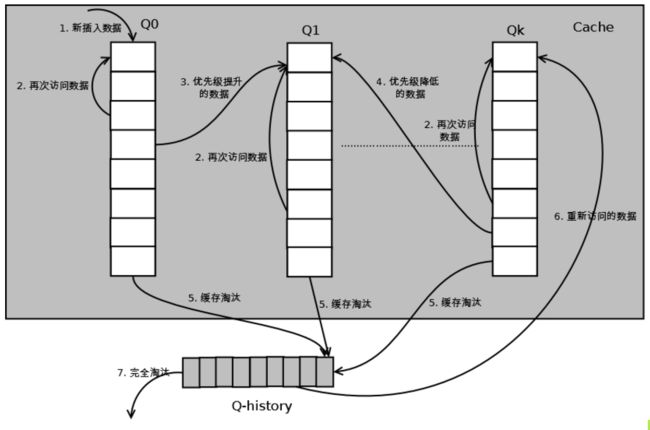
2.4 Multi Queue
Multi Queue算法根据访问频率将数据划分为多个队列,不同的队列具有不同的访问优先级,其核心思想是:优先缓存访问次数多的数据。
Multi Queue算法将缓存划分为多个LRU队列,每个队列对应不同的访问优先级。访问优先级是根据访问次数计算出来的。
- 原理:
- 新缓存数据在最低优先级的队列,每个队列按照LRU队列管理
- 缓存命中次数达到一定的阈值,提升优先级,进行队列转移
- 防止高优先级累积效应,在一定时间内,高优先级的缓存数据没有被命中,需要做降级
- 缓存数据丢弃存在丢弃临时队列
- 丢弃数据从丢弃临时队列开始
- 命中率:Multi Queue降低了“缓存污染”带来的问题,命中率比LRU要高。
- 复杂度:Multi Queue需要维护多个队列,且需要维护每个数据的访问时间,复杂度比LRU高。
- 消耗:Multi Queue需要记录每个数据的访问时间,需要定时扫描所有队列,时间消耗比LRU要高。空间上因为每个优先级队列的长度都很小,所以,空间消耗差不多。
3. Maxmemory配置
maxmemory size用于配置Redis存储数据时,指定限制的内存大小。==此配置放在redis.conf中即可。==
也可以使用CONFIG SET来运行时配置。
CONFIG SET命令用于在服务器运行期间重写某些配置,而不用重启Redis。你可以使用此命令更改不重要的参数或从一个参数切换到另一个持久性选项。
可以通过CONFIG GET *获得CONFIG SET命令支持的配置参数列表,该命令是用于获取有关正在运行的Redis实例的配置信息的对称命令。
所有使用CONFIG SET设置的配置参数将会立即被Redis加载,并从下一个执行的命令开始生效。
设置maxmemory 0表示无内存大小限制,可以使用所有的内存容量。
对于32位操作系统,默认内存限制3GB。对于64位操作系统,默认内存无限制。
4. 内存回收策略
当指定的内存限制大小达到时,需要选择不同的行为,也就是策略。
redis可以仅仅对命令返回错误,这将导致内存被使用的更多。或者回收一些旧的数据来使得添加数据时避免内存限制。
当maxmemory限制达到的时候,redis使用的策略由maxmemory-policy配置指定。
maxmemory-policy有以下待选:
- noeviction: 返回错误。当内存限制达到,并且客户端尝试执行更多内存被使用的命令(一些删除或者可能导致内存占用减少的命令除外)
- allkeys-lru:使用LRU算法。最少使用的缓存数据将被丢弃。
- volatile-lru:类似使用LRU-K算法。拥有两个队列,一个是缓存队列,一个是过期队列,丢弃数据从过期队列开始。
- allkeys-random:随机回收缓存数据。
- volatile-random:随机回收过期队列的缓存数据。
- volatile-ttl:回收过期队列的缓存数据,而且优先回收存活时间(ttl)较短的缓存数据。
对于volatile前缀的策略,如果回收条件不满足的话,那么和noeviction相同。
选择正确的回收策略非常重要,但是往往很多时候,策略的选择需要大量的经验。
所以一开始可以根据这些特点选择:
- allkey-lru:请求符合幂定理分布。即子集数据比其他数据访问频次更多。或者数据存在较为明显的热点分布的时候。
- allkey-random:请求均匀分布,每个数据被访问的频次差不多,没有明显区别。
- volatitle-ttl:数据有过期时间,或者大部分有过期时间。
过期时间的设置与维护,也是一个耗费资源的过程,所以使用allkeys-lru可能是更加高效的选择。
在配置了内存回收策略后,可以使用INFO命令查看瞬时redis服务器的资源消耗情况。
然后在分析redis资源使用情况,进行调整内存回收策略。
5. 回收原理
原理:
- 客户端执行了新的命令,增加了新的数据,一块内存被占用
- redis在命令执行完后,检查内存使用情况,如果内存限制超出
maxmemory限制,那么调用maxmemory-policy的策略进行回收
所以,设置了maxmemory并不是强制的,redis可能在很短的时间内,内存占用超出了maxmemory的限制。redis的内存占用不断的穿越边界值maxmemory,不断的达到并超过边界,然后又不断的回收回到边界以下。
6. redis的LRU算法
redis的LRU算法,并不是标准的LRU算法。
标准的LRU算法,需要将全部的缓存数据放到队列中,这样会消耗较多的内存。特别是对于redis经常缓存亿万的数据来说,将全部的key或者缓存数据放到队列中,这几乎是无法想象的灾难。
所以,在redis中使用标准的LRU算法是一种性能非常差的选择,因此,在redis中使用的是近似的LRU算法。
redis中近似的LRU算法与标准的LRU算法的区别在于:标准的LRU算法会将全部的数据进行统计;而redis近似的LRU算法则是随机采样,随机采样指定个数的缓存数据,然后根据采样结果,确定丢弃的缓存数据。
==请注意,这里的丢弃只是从内存中丢弃,数据不会丢失。类似我们硬盘上有16个G的数据,但是只有2G的内存,那么需要计算机不断的将新的数据从硬盘读取,覆盖旧的内存数据。==
在redis.conf中有一个配置redis的LRU算法采样数量的配置maxmemory-samples num,采样数值越大,采样范围越大,得出的结论越准确。如果采样是全体数据,那么准确率就是100%。不过采样范围的扩大,会导致整个采样过程,需要消耗更多的资源。
maxmemory-samples也可以使用config set进行设置。
这是redis官网的采样测试结果:
[图片上传失败...(image-16994-1596192689711)]
上面的图片可以被分为4个小块:第一个左上是标准LRU算法,第二个右上是采样10次的redis近似LRU算法,第三个左下是采样5次的结果,redis2.8,第四个右下是采样5次的结果,redis3.0.
小图是从上到下,从左到右创建,也就是左上角的小点是第一个,右下是最后一个。有时间顺序。
每一个小图中,有三种颜色的小点组成:
- 浅灰色:数据被回收
- 深灰色:数据没有被回收
- 深绿色:数据新建
当采样次数为5时,redis3.0好于redis2.8.在第三个中,存在大量的深灰色小点,而且分布没有明显的界限,即使很多很早时间创建,也没有被回收。
在第四个图找那个,我们可以明显的看到灰色区域有较为明显的分割带,不过深灰色色带所占比例不是很多,还不是非常理想。
对于都redis3.0比较,第二个灰色之间有更加明显的分隔带,而且色带分布比例均匀,差不多是50%.
与标准的LRU算法结果比较,采样次数高,redis版本新,算法更接近标准LRU。