Java基础 集合(四)Map详解
目录
简介
Map详解
HashMap
LinkedHashMap
TreeMap
WeakHashMap
Hashtable
前言-与正文无关
生活远不止眼前的苦劳与奔波,它还充满了无数值得我们去体验和珍惜的美好事物。在这个快节奏的世界中,我们往往容易陷入工作的漩涡,忘记了停下脚步,感受周围的世界。让我们一起提醒自己,要适时放慢脚步,欣赏生活中的每一道风景,享受与家人朋友的温馨时光,发现那些平凡日子里隐藏的幸福时刻。因为,这些点点滴滴汇聚起来的,才是构成我们丰富多彩生活的本质。希望每个人都能在繁忙的生活中找到自己的快乐之源,不仅仅为了生存而工作,更为了更好的生活而生活。
送你张美图!希望你开心!
简介
集合可以看作是一种容器,用来存储对象信息。所有集合类都位于java.util包下,值得一提的是支持多线程的集合类位于java.util.concurrent包下。
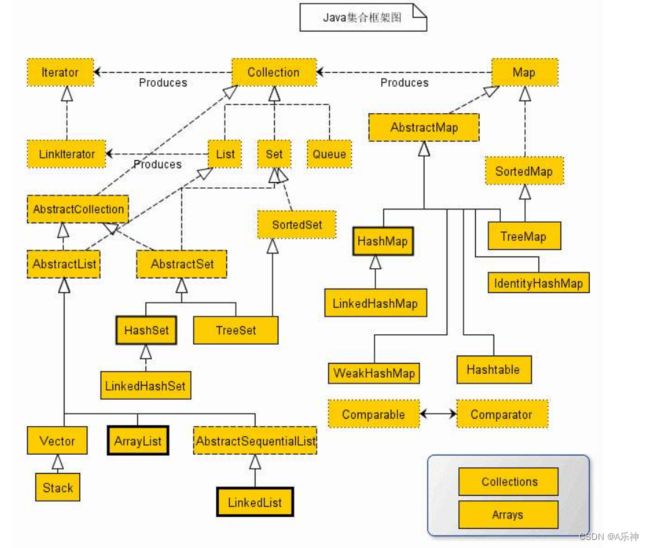
Map接口是由key映射到唯一的value,所以Map不能包含重复的key,每个键至多映射一个值。下图是整个 Map 集合体系的主要组成部分,我将会按照日常使用频率从高到低一一讲解。
不得不提的是 Map 的设计理念:定位元素的时间复杂度优化到 O(1)
Map 体系下主要分为 AbstractMap 和 SortedMap两类集合
AbstractMap是对 Map 接口的扩展,它定义了普通的 Map 集合具有的通用行为,可以避免子类重复编写大量相同的代码,子类继承 AbstractMap 后可以重写它的方法,实现额外的逻辑,对外提供更多的功能。
SortedMap 定义了该类 Map 具有 排序行为,同时它在内部定义好有关排序的抽象方法,当子类实现它时,必须重写所有方法,对外提供排序功能。
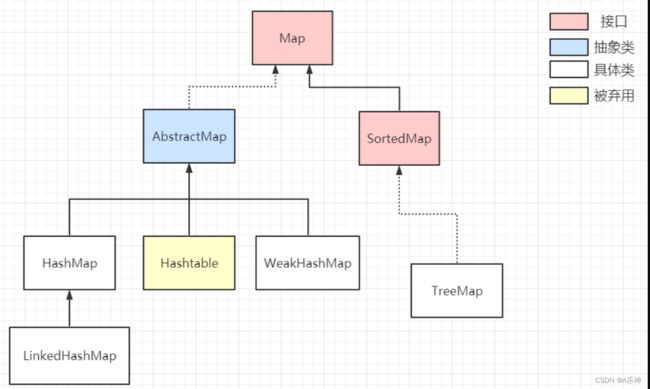
Map详解
HashMap
HashMap 是一个最通用的利用哈希表存储元素的集合,将元素放入 HashMap 时,将key的哈希值转换为数组的索引下标确定存放位置,查找时,根据key的哈希地址转换成数组的索引下标确定查找位置。
HashMap 底层是用数组 + 链表 + 红黑树这三种数据结构实现,它是非线程安全的集合。
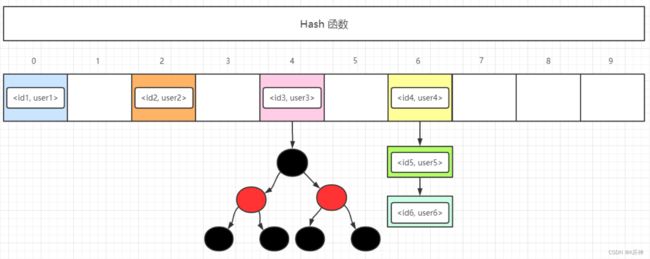
发送哈希冲突时,HashMap 的解决方法是将相同映射地址的元素连成一条链表,如果链表的长度大于8时,且数组的长度大于64则会转换成红黑树数据结构。
LinkedHashMap

LinkedHashMap 可以看作是 HashMap 和 LinkedList 的结合:它在 HashMap 的基础上添加了一条双向链表,LinkedHashMap 是 HashMap 的子类,所以它具备 HashMap 的所有特点,其次,它在 HashMap 的基础上维护了一条双向链表,该链表存储了所有元素,默认元素的顺序与插入顺序一致。若accessOrder属性为true,则遍历顺序按元素的访问次序进行排序。
// 头节点
transient LinkedHashMap.Entry head;
// 尾结点
transient LinkedHashMap.Entry tail; 利用 LinkedHashMap 可以实现 LRU 缓存淘汰策略,因为它提供了一个方法:
protected boolean removeEldestEntry(java.util.Map.Entry eldest) {
return false;
} 该方法可以移除最靠近链表头部的一个节点,而在get()方法中可以看到下面这段代码,其作用是挪动结点的位置:
if (this.accessOrder) {
this.afterNodeAccess(e);
}只要调用了get()且accessOrder = true,则会将该节点更新到链表尾部,具体的逻辑在afterNodeAccess()中,感兴趣的可翻看源码,篇幅原因这里不再展开。
现在如果要实现一个LRU缓存策略,则需要做两件事情:
- 指定
accessOrder = true可以设定链表按照访问顺序排列,通过提供的构造器可以设定accessOrder
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}- 重写
removeEldestEntry()方法,内部定义逻辑,通常是判断容量是否达到上限,若是则执行淘汰。
关于 LinkedHashMap 主要介绍两点:
- 它底层维护了一条
双向链表,因为继承了 HashMap,所以它也不是线程安全的 - LinkedHashMap 可实现
LRU缓存淘汰策略,其原理是通过设置accessOrder为true并重写removeEldestEntry方法定义淘汰元素时需满足的条件
TreeMap
TreeMap 是 SortedMap 的子类,所以它具有排序功能。它是基于红黑树数据结构实现的,每一个键值对key自然排序,另一种是可以通过传入定制的Comparator进行自定义规则排序。
// 按照 key 自然排序,Integer 的自然排序是升序
TreeMap naturalSort = new TreeMap<>();
// 定制排序,按照 key 降序排序
TreeMap customSort = new TreeMap<>((o1, o2) -> Integer.compare(o2, o1)); TreeMap 底层使用了数组+红黑树实现,所以里面的存储结构可以理解成下面这幅图哦。

图中红黑树的每一个节点都是一个Entry,在这里为了图片的简洁性,就不标明 key 和 value 了,注意这些元素都是已经按照key排好序了,整个数据结构都是保持着有序 的状态!
关于自然排序与定制排序:
- 自然排序:要求
key必须实现Comparable接口。
由于Integer类实现了 Comparable 接口,按照自然排序规则是按照key从小到大排序。
TreeMap treeMap = new TreeMap<>();
treeMap.put(2, "TWO");
treeMap.put(1, "ONE");
System.out.print(treeMap);
// {1=ONE, 2=TWO} - 定制排序:在初始化 TreeMap 时传入新的
Comparator,不要求key实现 Comparable 接口
TreeMap treeMap = new TreeMap<>((o1, o2) -> Integer.compare(o2, o1));
treeMap.put(1, "ONE");
treeMap.put(2, "TWO");
treeMap.put(4, "FOUR");
treeMap.put(3, "THREE");
System.out.println(treeMap);
// {4=FOUR, 3=THREE, 2=TWO, 1=ONE} 通过传入新的Comparator比较器,可以覆盖默认的排序规则,上面的代码按照key降序排序,在实际应用中还可以按照其它规则自定义排序。
compare()方法的返回值有三种,分别是:0,-1,+1
(1)如果返回0,代表两个元素相等,不需要调换顺序
(2)如果返回+1,代表前面的元素需要与后面的元素调换位置
(3)如果返回-1,代表前面的元素不需要与后面的元素调换位置
而何时返回+1和-1,则由我们自己去定义,JDK默认是按照自然排序,而我们可以根据key的不同去定义降序还是升序排序。
关于 TreeMap 主要介绍了两点:
- 它底层是由
红黑树这种数据结构实现的,所以操作的时间复杂度恒为O(logN) - TreeMap 可以对
key进行自然排序或者自定义排序,自定义排序时需要传入Comparator,而自然排序要求key实现了Comparable接口 - TreeMap 不是线程安全的。
WeakHashMap
WeakHashMap 日常开发中比较少见,它是基于普通的Map实现的,而里面Entry中的键在每一次的垃圾回收都会被清除掉,所以非常适合用于短暂访问、仅访问一次的元素,缓存在WeakHashMap中,并尽早地把它回收掉。
当Entry被GC时,WeakHashMap 是如何感知到某个元素被回收的呢?
在 WeakHashMap 内部维护了一个引用队列queue
private final ReferenceQueue这个 queue 里包含了所有被GC掉的键,当JVM开启GC后,如果回收掉 WeakHashMap 中的 key,会将 key 放入queue 中,在expungeStaleEntries()中遍历 queue,把 queue 中的所有key拿出来,并在 WeakHashMap 中删除掉,以达到同步。
private void expungeStaleEntries() {
for (Object x; (x = queue.poll()) != null; ) {
synchronized (queue) {
// 去 WeakHashMap 中删除该键值对
}
}
}再者,需要注意 WeakHashMap 底层存储的元素的数据结构是数组 + 链表,没有红黑树哦,可以换一个角度想,如果还有红黑树,那干脆直接继承 HashMap ,然后再扩展就完事了嘛,然而它并没有这样做:
public class WeakHashMap extends AbstractMap implements Map {
} 所以,WeakHashMap 的数据结构图我也为你准备好啦。
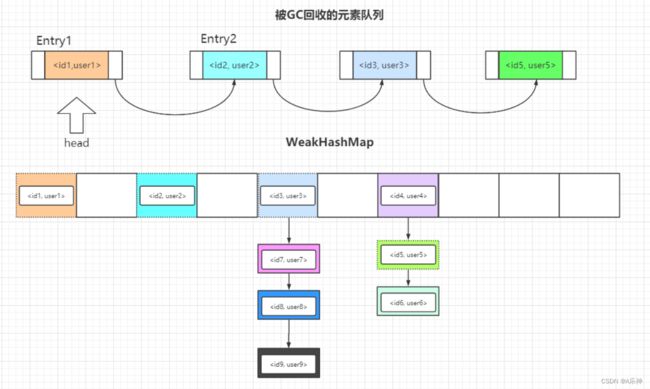
图中被虚线标识的元素将会在下一次访问 WeakHashMap 时被删除掉,WeakHashMap 内部会做好一系列的调整工作,所以记住队列的作用就是标志那些已经被GC回收掉的元素。
关于 WeakHashMap 需要注意两点:
- 它的键是一种弱键,放入 WeakHashMap 时,随时会被回收掉,所以不能确保某次访问元素一定存在
- 它依赖普通的
Map进行实现,是一个非线程安全的集合 - WeakHashMap 通常作为缓存使用,适合存储那些只需访问一次、或只需保存短暂时间的键值对
Hashtable
Hashtable 底层的存储结构是数组 + 链表,而它是一个线程安全的集合,但是因为这个线程安全,它就被淘汰掉了。
下面是Hashtable存储元素时的数据结构图,它只会存在数组+链表,当链表过长时,查询的效率过低,而且会长时间锁住 Hashtable。
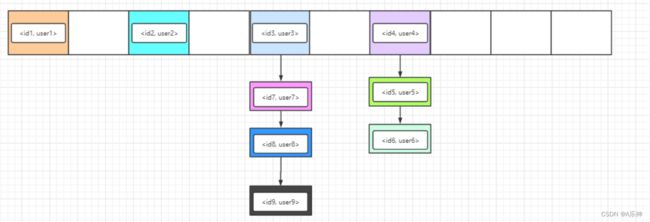
这幅图是否有点眼熟,本质上就是 WeakHashMap 的底层存储结构了
HashTable 本质上是 HashMap 的前辈,它被淘汰的原因也主要因为两个字:性能
HashTable 是一个 线程安全 的 Map,它所有的方法都被加上了 synchronized 关键字,也是因为这个关键字,它注定成为了时代的弃儿。
HashTable 底层采用 数组+链表 存储键值对,由于被弃用,后人也没有对它进行任何改进
HashTable 默认长度为 11,负载因子为 0.75F,即元素个数达到数组长度的 75% 时,会进行一次扩容,每次扩容为原来数组长度的 2 倍
HashTable 所有的操作都是线程安全的。
------------------------------------------与正文内容无关------------------------------------
如果觉的文章写对各位读者老爷们有帮助的话,麻烦点赞加关注呗!作者在这拜谢了!
混口饭吃了!如果你需要Java 、Python毕设、商务合作、技术交流、就业指导、技术支持度过试用期。请在关注私信我,本人看到一定马上回复!
这是我全部文章所在目录,看看是否有你需要的,如果遇到觉得不对地方请留言,看到后我会查阅进行改正。
A乐神-CSDN博客