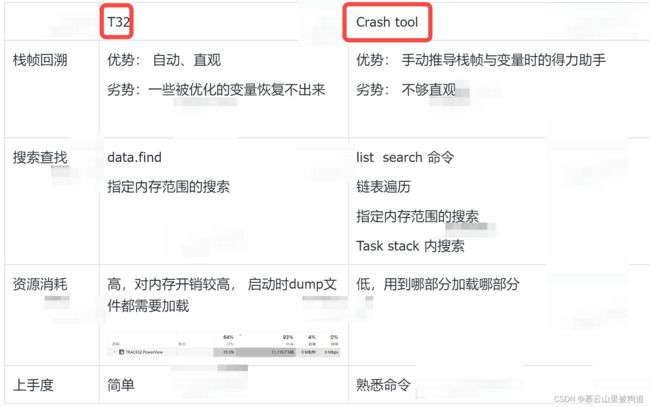
内核trace分析工具入门
内核进程 进程堆栈 各个核运行的进程内容。。。。内核分析的维度比较多,所以需要一些工具分析,包括各个soc参商也有自己的工具,当然他们的分析软件需要有账号
内核问题处理的经验也是通过解析了几百个?dump,分析过各种crash panic 橙屏问题积攒出来的
在计算机科学中,符号表是一种用于语言翻译器(例如编译器和解释器)中的数据结构。在符号表中,程序源代码中的每个标识符都和它的声明或使用信息绑定在一起,比如其数据类型、作用域以及内存地址。所以解dump(简单说就是各种函数数据结构及进程信息都有)时候需要符号表(这个dump要对应这个软件版本的符号表,毕竟不同软件版本的函数变量都是不一样的),才能定位最后carsh在了那个位置,现场的相关函数和数据结构都是哪些,以及相应的进程信息堆栈情况。
TRACE32是由德国Lauterbach公司研制开发的一款仿真测试工具,好像针对ARM及其他架构都可以。不局限于某个芯片平台,也不局限于某个芯片厂商。
Linux中将进程称为"task",是因为在Linux中,进程不仅仅是一个程序在执行,还包括了该程序所需的资源,如内存、文件、网络连接等。因此,"task"这个词更加全面地描述了进程在Linux中的本质。
工具只需要T32软件,通过软件的协助,恢复crash时现场,帮助debug crash原因。这个是我们最常见的使用方式
Crash tool
crash 是一个用于分析内核转储文件的工具,一般和 kdump 搭配使用。命令行工具。
使用 crash 时,要求调试内核 vmlinux 在编译时带有 -g 选项,即带有调试信息。Crash 工具 是在 GDB 的基础之上进一步开发的,所以 Crash 工具的很多命令在 gdb 上应该都是可以直接使用的,本篇文档主要介绍如何使用 Crash 来分析panic/hang 类型的一些 bug,这里需要注意的是有些 bug,如 hang,只能使用 etb 工具来查看最后各个 cpu 都在干什么。
t32常用命令
打call trace v.f /task 0xFFFFFF88E5CEDDC0
查看变量 v.v
查看内存 d.dump
查看cmdline v.v saved_command_line
T32实例(解dump 输出卡死函数及位置)
以某高通平台为例,T32可以理解为通过符号表(知道了具体函数变量位置粗暴理解)来集中展示dump信息(比如所有进程出入栈信息,具体汇编操作,各个芯片核的运行情况等等 太多了 不能一以贯之 一次写不完 我边学边写吧)。
除了通用T32这种通用dump解析工具(所谓解析dump我理解就是展示各种信息),芯片平台一般会有自己的工具来解析。这里也会展示高通自己的工具解析样式。
1,芯片厂商解析
qcom自己的工具,通过qpst工具下载dump,再下载对应的符号表,通过qcap解析输出到浏览器。
解析界面

解析结果


2,用T32看dump解析
抓到dump文件,其中out是解析后才有
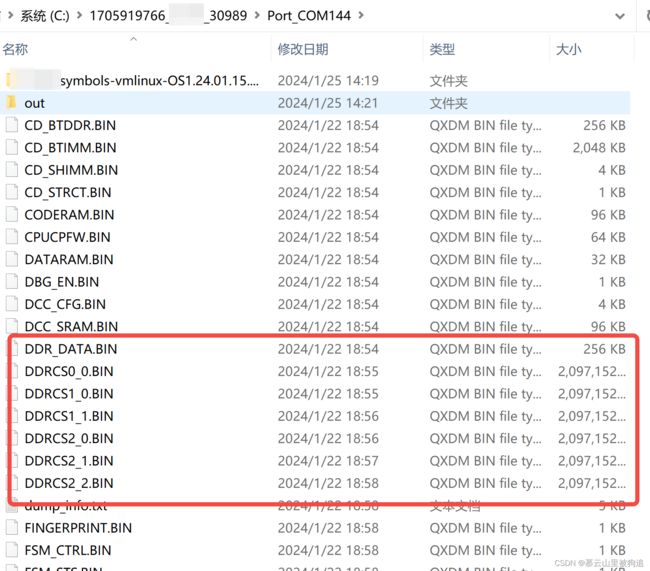
符号表elf文件


用T32看dump解析
搞错了
有了有了,原来是T32有些问题,本地解析还没弄好,再说吧再说吧
这样就可以捣鼓各种trace,task(进程),栈调用,定位,stack(栈)
T32解析需要什么
dump及对应符号表 这是原材料
解析指令
python xxx\ramparse(ramparse路径一个工具如下).py -v <vmlinux_path> --force-hardware <项目名称> -x -a <dump路径dir> -o <output_path> --mod_path <all_load_mod_symbol_path符号表路径>
这里我把ramparse和dump ms(符号表)放到了一起
解析错误,尴尬,爱错错去吧,不看了。话说vmlinux_path这个玩意干啥用的
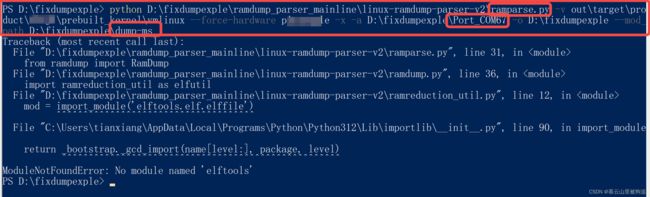
需要用到python
T32工具(不用安装,其实只是用来看结果的),crashman(相当于对应该款芯片的文件,我也不清楚)
3,实例分析
直接上dump解析
call trace,空指针来自src2p
-
通过list确定代码位置
-
addr2非法地址0x8

往上找,灰阴影位置为函数
压栈情况
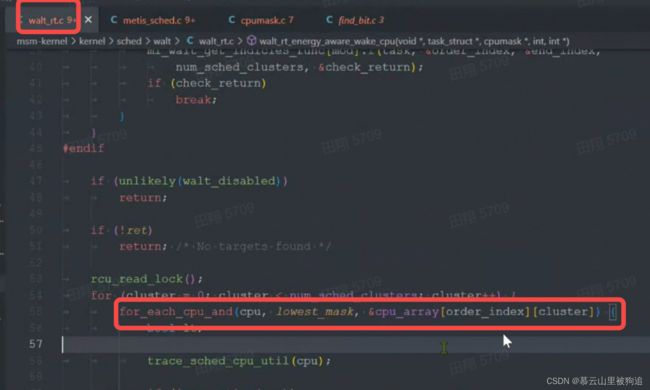
for循环 cluster第一次的时候
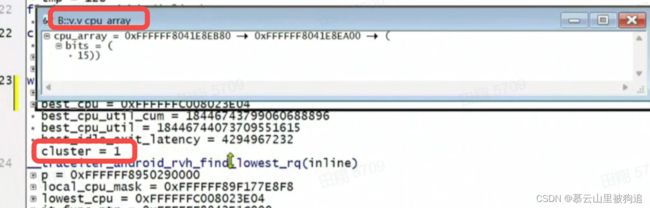
cpumask一级二级指针,这个是指令 v.infocpu_array
结论: lowest_mask 是0xFFFFFF89F177E8F8, 是&cpu_array[order_index][cluster]引入的空指针。cluster = 1, order_index 由于编译器优化,t32没有直接恢复出来
-
检查cpumask_t __read_mostly **cpu_array 变量
直接v.v,可以先用v.info帮忙分析它是啥
&cpu_array[2][1] 为什么会是0x8,结合上面dump内容看就很清晰了, cpu_array[2]是0 ,一个cpumask的大小是8字节,所以 cpu_array[2] +1 就是0x8
恢复上层寄存器
当gcore无法恢复上层现场时, 通过T32能做点什么? 比如遇到Init kill 导致的crash,上层echo c 主动触发的panic。
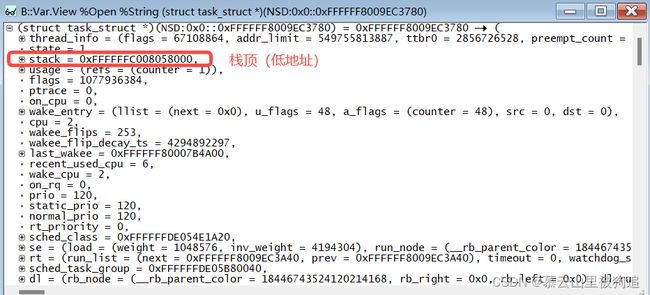
从用户态陷入内核态时,一定会保存用户空间的寄存器,这样从内核态返回时,才能恢复用户态的现场。用户空间的寄存器,会以struct pt_regs结构被保存在内核栈的栈底,内核栈大小固定16K。
从task_struct中获取栈顶 0xFFFFFFC008058000(底地址), 退到栈底0xFFFFFFC00805C000(高地址)。 通过v.info 查看pt_regs结构体大小为0x150, 所以pt_regs地址就是
0xFFFFFFC00805C000-0x150=0xFFFFFFC00805BEB0

B::v.v (struct pt_regs)0xFFFFFFC00805BEB0 恢复出来用户态寄存器
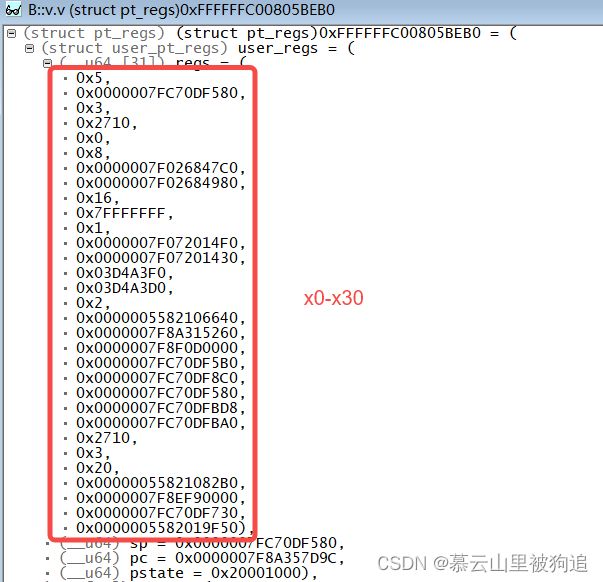
内核sp pc寄存器
ARM中所有寄存器都是32位的。这里以cortex-a7内核的MX6ULL处理器为例,按照功能可以分为两类:运行需要寄存器(程序正常运行所需要的,比如变量暂存,pc制作等,总共43个),系统管理控制寄存器(存在于协处理器cp15的16个寄存器,用于mmu存储管理控制,cache控制,中断控制,浮点运算单元FPU等功能)。因此cortex-a7内核总的有59个寄存器。

4,一个dump是一个经验,100个就是100个经验
内核问题有的会把机器卡死,表现为冻屏,橙屏
或者系统卡
原因呢?有内存类 非法地址访问(写入只读内存、从不可读取的内存读取、引用空指针、访问受管理程序保护的内存、访问用户空间地址、栈溢出等)
调度类 死锁,互相持锁 Linux在中断处理程序中,如果使用可能睡眠的函数,引起panic、死锁、io error等引起的调度类panic
大部分问题其实定位到core trace就已经定位到位置,从代码逻辑梳理也能大概定位到原因。只不过T32能把具体场景比较详细的还原出来
太粗暴太简陋了。后面再写好些
参考链接:
【ARM Linux 系统稳定性分析入门及渐进 1 -- Crash 工具简介】_linux ramdump-CSDN博客
T32 使用技巧 - 知乎
arm中SP,LR,PC寄存器及处理器运行模式_lr寄存器-CSDN博客