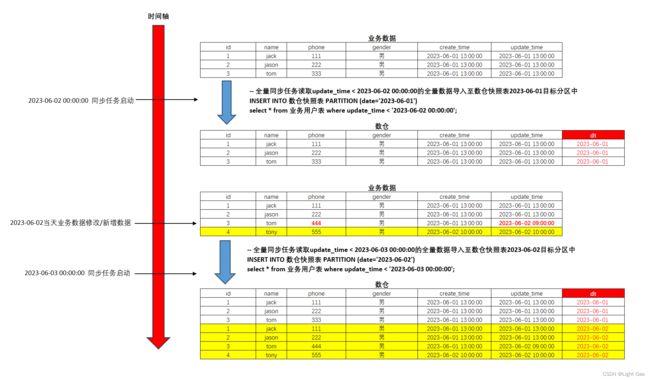
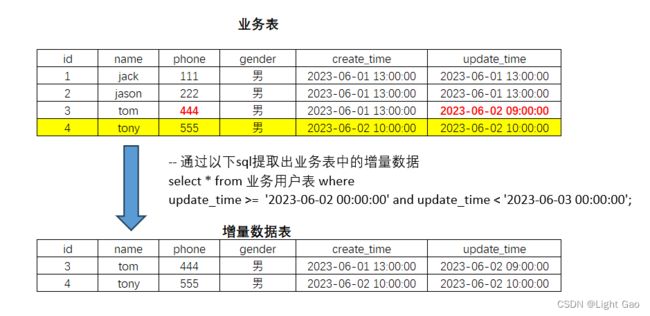
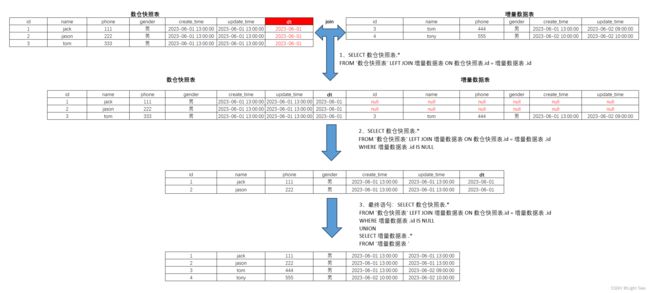
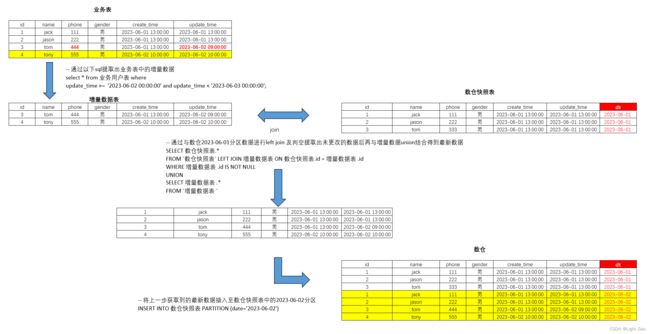
- 什么是缓存雪崩?缓存击穿?缓存穿透?分别如何解决?什么是缓存预热?
daixin8848
缓存redisjava开发语言
缓存雪崩:在一个时间段内,有大量的key过期,或者Redis服务宕机,导致大量的请求到达数据库,带来巨大压力-给key设置不同的TTL、利用Redis集群提高服务的高可用性、添加多级缓存、添加降级流策略缓存击穿:给某一个key设置了过期时间,当key过期的时间,恰好这个时间点有大量的并发请求访问这个key,可能会瞬间把数据库压垮-互斥锁:缓存失败时,只允许一个请求去加载数据并更新缓存,其他请求阻塞
- 在线人数统计业务设计(场景八股文)
业务问题在当经的网站中,在线人数的实时统计已经是一个必不可少的模块了,并且该统计功能最好能够按不同的时间间隔做的统计,现在需要你设计一个在线人数统计的模块,你应该怎么进行设计的呢?背景一个网校下会有多个学员。目前平台大概有十个,平台对应的网校大概五十几个,平均一个网校会有5w个用户,预计总人数为200w,最该学员的在线人数在10w左右。设计思路最开始的时候,想到的就是使用mysql直接实现,但是明
- Aop +反射 实现方法版本动态切换
需求分析在做技术选型的时候一直存在着两个声音,mongo作为数据库比较mysql好,mysql做为该数据比mongo好。当然不同数据库都有有着自己的优势,我们在做技术选型的时候无非就是做到对数据库的扬长避短。mysql最大的优势就是支持事务,事务的五大特性保证的业务可靠性,随之而来的就是事务会产生的问题:脏读、幻读、不可重复度,当然我们也会使用不同的隔离级别来解决。(最典型的业务问题:银行存取钱)
- mysql复习
立夏的李子
mysql数据库database
mysqlselect语法selectfromjoinwheregroupbyhavingorderbylimit联合查询innerjoin()leftjoin(以左表为基准,匹配右表,不匹配的返回左表,右表以null值填充)rightjoind··(去除列重复的数据)索引类型主键索引(PrimaryKey)唯一索引(Unique)常规索引(Index)全文索引(FullText)索引准则索引不是
- Deepseek技术深化:驱动大数据时代颠覆性变革的未来引擎
荣华富贵8
springboot搜索引擎后端缓存redis
在大数据时代,信息爆炸和数据驱动的决策逐渐重塑各行各业。作为一项前沿技术,Deepseek正在引领新一轮技术革新,颠覆传统数据处理与分析方式。本文将从理论原理、应用场景和前沿代码实践三个层面,深入剖析Deepseek技术如何为大数据时代提供颠覆性变革的解决方案。一、技术背景与核心思想1.1大数据挑战与机遇在数据量呈指数级增长的背景下,传统数据处理方法面临数据存储、计算效率和信息提取精度的诸多挑战。
- MySQL复习题
一.填空题1.关系数据库的标准语言是SQL。2.数据库发展的3个阶段中,数据独立性最高的是阶段数据库系统。3.概念模型中的3种基本联系分别是一对一、一对多和多对多。4.MySQL配置文件的文件名是my.ini或my.cnf。5.在MySQL配置文件中,datadir用于指定数据库文件的保存目录。6.添加IFNOTEXISTS可在创建的数据库已存在时防止程序报错。7.MySQL提供的SHOWCREA
- 大数据之路:阿里巴巴大数据实践——大数据领域建模综述
为什么需要数据建模核心痛点数据冗余:不同业务重复存储相同数据(如用户基础信息),导致存储成本激增。计算资源浪费:未经聚合的明细数据直接参与计算(如全表扫描),消耗大量CPU/内存资源。数据一致性缺失:同一指标在不同业务线的口径差异(如“活跃用户”定义不同),引发决策冲突。开发效率低下:每次分析需重新编写复杂逻辑,无法复用已有模型。数据建模核心价值性能提升:分层设计(ODS→DWD→DWS→ADS)
- Android GreenDao介绍和Generator生成表对象代码
目录(?)[-]介绍创建工程转载请注明:http://blog.csdn.net/sinat_30276961/article/details/50052109最近无意中发现了GreenDao,然后查看了一些资料后,发现这个数据库框架很适合用,于是乎,查看了官网的api,并自己写了一个小应用总结一下它的使用方法。介绍按照国际惯例,在开篇,总要先介绍一下什么是GreenDao吧。首先需要说明的是Gr
- Spark SQL架构及高级用法
Aurora_NeAr
sparksql架构
SparkSQL架构概述架构核心组件API层(用户接口)输入方式:SQL查询;DataFrame/DatasetAPI。统一性:所有接口最终转换为逻辑计划树(LogicalPlan),进入优化流程。编译器层(Catalyst优化器)核心引擎:基于规则的优化器(Rule-BasedOptimizer,RBO)与成本优化器(Cost-BasedOptimizer,CBO)。处理流程:阶段输入输出关键动
- 大数据技术笔记—spring入门
卿卿老祖
篇一spring介绍spring.io官网快速开始Aop面向切面编程,可以任何位置,并且可以细致到方法上连接框架与框架Spring就是IOCAOP思想有效的组织中间层对象一般都是切入service层spring组成前后端分离已学方式,前后台未分离:Spring的远程通信:明日更新创建第一个spring项目来源:科多大数据
- Mac OSX 下的mysql数据库文件存放位置
Bruuuces
mysqlmacosx位置存放
之前我的mysql的系统数据库里的表被我玩坏了,万般无奈之下只得删除所有mysql的东西重新构建数据库。按照网上搜到的内容删除后重装发现数据库没有什么变化。于是自己在每个可能存放数据库文件的目录查找,最终确认目录位置如下:使用HomeBrew安装为/usr/local/var/mysql使用官方下载的dmg镜像安装为/usr/local/mysql删除这个目录再重新安装mysql就会重新生成系统数
- mac os 10.9 mysql_MAC OSX 10.9 apache php mysql 环境配置
AY05
macos10.9mysql
#终端内运行sudoapachectlstart#启动Apachesudoapachectlrestart#重启Apachesudoapachectlstop#停止Apache#配置Apachesudovi/private/etc/apache2/httpd.conf#将里面的这一行去掉前面的##LoadModulephp5_modulelibexec/apache2/libphp5.so#配置P
- mac升级mysql_Mac OSX下的MySQL数据库升级
weixin_39801714
mac升级mysql
MacOSX下的数据库升级最麻烦的不过权限的问题.本文的MySQL的安装方式为OSX下DMG磁盘镜像的安装方式,MacPorts/Homebrew的方式大同小异.从5.6.17升级到5.7.18安装目录信息ls-al/usr/local|grepmysqllrwxr-xr-x1rootwheel30B52100:39mysql@->mysql-5.6.17-osx10.7-x86_64drwxr-
- 【MySQL】MySQL数据库如何改名
武昌库里写JAVA
面试题汇总与解析springbootvue.jssqljava学习
MySQL建库授权语句https://www.jianshu.com/p/2237a9649ceeMySQL数据库改名的三种方法https://www.cnblogs.com/gomysql/p/3584881.htmlMySQL安全修改数据库名几种方法https://blog.csdn.net/haiross/article/details/51282417MySQL重命名数据库https://
- HikariCP调试日志深度解析:生产环境故障排查完全指南
HikariCP调试日志深度解析:生产环境故障排查完全指南更新时间:2025年7月4日|作者:资深架构师|适用版本:HikariCP5.x+|难度等级:中高级前言在生产环境中,数据库连接池往往是系统性能的关键瓶颈。HikariCP作为当前最流行的Java连接池,其调试日志包含了丰富的运行时信息,能够帮助我们快速定位和解决各种连接池相关问题。本文将深入解析HikariCP的日志体系,提供一套完整的故
- 大学社团管理系统(11831)
codercode2022
javaspringbootspringechartsspringcloudsentineljava-rocketmq
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦一、项目演示项目演示视频二、资料介绍完整源代码(前后端源代码+SQL脚本)配套文档(LW+PPT+开题报告)远程调试控屏包运行三、技术介绍Java语言SSM框架SpringBoot框架Vue框架JSP页面Mysql数据库IDEA/Eclipse开发四、项目截图有需要的同学,源代码和配套文档领取,加文章最下方的名片哦!
- 前端数据库:IndexedDB从基础到高级使用指南
文章目录前端数据库:IndexedDB从基础到高级使用指南引言一、IndexedDB概述1.1什么是IndexedDB1.2与其他存储方案的比较二、基础使用2.1打开/创建数据库2.2基本CRUD操作添加数据读取数据更新数据删除数据三、高级特性3.1复杂查询与游标3.2事务高级用法3.3性能优化技巧四、实战案例:构建离线优先的待办事项应用4.1数据库设计4.2同步策略实现五、常见问题与解决方案5.
- 修改gitlab默认的语言
Victor刘
gitlab
文章目录网上的方法1.采用数据库触发器的方法2.登录pg库2.1查看表2.2创建function2.3创建触发器2.4修改历史数据网上的方法网上修改/opt/gitlab/embedded/service/gitlab-rails/config/application.rb的方法,我试了,没生效,没进一步研究1.采用数据库触发器的方法2.登录pg库su-gitlab-psqlpsql-h/var/
- 如何在 Ubuntu 24.04 或 22.04 Linux 上安装和运行 Redis 服务器
山岚的运维笔记
Linux运维及使用linux服务器ubunturedis数据库
Redis(RemoteDictionaryServer,远程字典服务器)是一种内存数据结构存储,通常用作NoSQL数据库、缓存和消息代理。它是开源的,因此用户可以免费安装,无需支付任何费用。Redis旨在为需要快速数据访问和低延迟的应用程序提供速度和效率。Redis支持多种数据类型,包括字符串(Strings)、列表(Lists)、集合(Sets)、哈希(Hashes)、有序集合(SortedS
- 数据库基础概念梳理
22:30Plane-Moon
数据库
1.数据存储类型表(Table):存储结构化数据的标准方式,数据以行和列的形式组织,具有固定的格式。非结构化数据(UnstructuredData):如音频、视频、图片、文本文档等,其格式不固定,不易直接用表存储。2.SQL的核心优势SQL尤其擅长处理和操作存储在表中的结构化数据。2.1数据类型约束(DataTypeConstraints):定义列可存储的数据种类。整数类型:TINYINT(1字节
- SQL笔记纯干货
AI入门修炼
oracle数据库sql
软件:DataGrip2023.2.3,phpstudy_pro,MySQL8.0.12目录1.DDL语句(数据定义语句)1.1数据库操作语言1.2数据表操作语言2.DML语句(数据操作语言)2.1增删改2.2题2.3备份表3.DQL语句(数据查询语言)3.1查询操作3.2题一3.3题二4.多表详解4.1一对多4.2多对多5.多表查询6.窗口函数7.拓展:upsert8.sql注入攻击演示9.拆表
- Ubuntu24安装MariaDB/MySQL后不知道root密码如何解决
Ubuntu24.04安装MariaDB后root密码未知?解决方案在此在Ubuntu24.04上新安装MariaDB后,许多用户会发现自己不知道root用户的密码,甚至在安装过程中也没有提示设置密码。这是因为在较新的MariaDB版本中,默认情况下root用户采用了unix_socket身份验证插件。这意味着您可以使用操作系统的root用户权限直接登录MariaDB,而无需输入密码。本文将为您详
- mysql创建线程处理链接请求
斜不靠谱
mysqld通过RUN_HOOK(server_state,before_handle_connection,(NULL));调用/**Threadhandlerforaconnection@paramargConnectionobject(Channel_info)Thisfunction(normally)doesthefollowing:-Initializethread//初始化线程-In
- 大数据精准获客并实现高转化的核心思路和实现方法
2401_88470328
大数据精准获客数据分析数据挖掘大数据需求分析bigdata
大数据精准获客并实现高转化的核心思路和实现方法大数据精准获客并实现高转化的核心思路和实现方法在当今信息爆炸的时代,企业如何通过海量的数据精准获取潜在客户,并提高转化率,已经成为营销策略中的关键环节。大数据精准获客的核心思路在于数据驱动、多渠道触达以及优化转化路径,从而实现高效的市场推广和客户转化。数据驱动原理和机制数据驱动的核心在于通过分析用户行为数据,挖掘潜在客户的需求和喜好,从而制定更加精准的
- 一地鸡毛—一个中年男人的日常2021241
随止心语所自欲律
2021年8月31日,星期二,阴有小雨。早起5:30,跑步10公里。空气清新,烟雨朦胧,远山如黛,烟雾缭绕,宛若仙境。空气中湿气很大,朦胧细雨拍打在脸上,甚是舒服,跑步的人明显减少。早上开会,领导说起逐年大幅度下滑的工作业绩,越说越激动,说得脸红脖子粗。开完会又讨论了一下会议精神,心情也有波动,学习热情不高。心里还有一个大事,是今日大数据分析第1次考试,因自己前期没学,而且计算机编程方面没有任何基
- 分布式全局唯一ID生成:雪花算法 vs Redis Increment,怎么选?
雪花算法vsRedisIncrement:分布式全局唯一ID生成方案深度对比在分布式系统开发中,“全局唯一ID”是绕不开的核心问题。无论是分库分表的数据库设计、订单编号的唯一性保证,还是日志追踪的链路标识,都需要一套可靠的ID生成方案。今天我们就来聊聊两种主流方案——雪花算法(Snowflake)和RedisIncrement,并从原理、特性到适用场景,帮你理清如何选择。同时,我们还将对比其他常见
- 【Druid】学习笔记
fixAllenSun
学习笔记oracle
【Druid】学习笔记【一】简介【1】简介【2】数据库连接池(1)能解决的问题(2)使用数据库连接池的好处【3】监控(1)监控信息采集的StatFilter(2)监控不影响性能(3)SQL参数化合并监控(4)执行次数、返回行数、更新行数和并发监控(5)慢查监控(6)Exception监控(7)区间分布(8)内置监控DEMO【4】Druid基本配置参数介绍【5】Druid相比于其他数据库连接池的优点
- 构建高效的物流车辆定位管理系统
体制教科书
本文还有配套的精品资源,点击获取简介:物流车辆定位管理系统利用信息技术提高物流效率和安全性。通过集成GPS技术进行实时车辆追踪和监控,它提供及时的货物运送和异常处理。系统的关键技术包括GPS车辆定位、C#编程语言、数据库管理、车辆管理、在途情况监控、预警与通知、数据分析与报告、用户界面设计、安全性与隐私保护以及系统集成。这些要素共同保障物流流程的高效、安全和智能化。1.物流车辆定位管理系统的应用与
- Spring AI Alibaba 快速入门指南(适合初学者)
会飞的架狗师
AIspring人工智能java
如果你是刚接触AI开发或Spring框架的初学者,不用担心,本指南会用简单易懂的语言带你一步步了解并使用SpringAIAlibaba。一、什么是SpringAIAlibaba(小白也能懂)简单来说,SpringAIAlibaba就是一个“工具包”,它把阿里巴巴的AI技术(比如通义千问大模型、向量数据库等)和大家常用的Spring框架“打包”到了一起。**打个比方:**就像你想做蛋糕(开发AI应用
- Java朴实无华按天计划从入门到实战(强化速战版-66天)
岫珩
Java后端java开发语言学习Java时间安排学习计划
致敬读者感谢阅读笑口常开生日快乐⬛早点睡觉博主相关博主信息博客首页专栏推荐活动信息文章目录Java朴实无华按天计划从入门到实战(强化速战版-66天)1.基础(18)1.1JavaSE核心(5天)1.2数据库与SQL(5天)1.3前端基础(8天)2.进阶(17天)2.1JavaWeb核心(5天)2.2Mybatis与Spring全家桶(6天)2.3中间件入门(4天)2.4实践项目(2天)3.高阶(1
- java杨辉三角
3213213333332132
java基础
package com.algorithm;
/**
* @Description 杨辉三角
* @author FuJianyong
* 2015-1-22上午10:10:59
*/
public class YangHui {
public static void main(String[] args) {
//初始化二维数组长度
int[][] y
- 《大话重构》之大布局的辛酸历史
白糖_
重构
《大话重构》中提到“大布局你伤不起”,如果企图重构一个陈旧的大型系统是有非常大的风险,重构不是想象中那么简单。我目前所在公司正好对产品做了一次“大布局重构”,下面我就分享这个“大布局”项目经验给大家。
背景
公司专注于企业级管理产品软件,企业有大中小之分,在2000年初公司用JSP/Servlet开发了一套针对中
- 电驴链接在线视频播放源码
dubinwei
源码电驴播放器视频ed2k
本项目是个搜索电驴(ed2k)链接的应用,借助于磁力视频播放器(官网:
http://loveandroid.duapp.com/ 开放平台),可以实现在线播放视频,也可以用迅雷或者其他下载工具下载。
项目源码:
http://git.oschina.net/svo/Emule,动态更新。也可从附件中下载。
项目源码依赖于两个库项目,库项目一链接:
http://git.oschina.
- Javascript中函数的toString()方法
周凡杨
JavaScriptjstoStringfunctionobject
简述
The toString() method returns a string representing the source code of the function.
简译之,Javascript的toString()方法返回一个代表函数源代码的字符串。
句法
function.
- struts处理自定义异常
g21121
struts
很多时候我们会用到自定义异常来表示特定的错误情况,自定义异常比较简单,只要分清是运行时异常还是非运行时异常即可,运行时异常不需要捕获,继承自RuntimeException,是由容器自己抛出,例如空指针异常。
非运行时异常继承自Exception,在抛出后需要捕获,例如文件未找到异常。
此处我们用的是非运行时异常,首先定义一个异常LoginException:
/**
* 类描述:登录相
- Linux中find常见用法示例
510888780
linux
Linux中find常见用法示例
·find path -option [ -print ] [ -exec -ok command ] {} \;
find命令的参数;
- SpringMVC的各种参数绑定方式
Harry642
springMVC绑定表单
1. 基本数据类型(以int为例,其他类似):
Controller代码:
@RequestMapping("saysth.do")
public void test(int count) {
}
表单代码:
<form action="saysth.do" method="post&q
- Java 获取Oracle ROWID
aijuans
javaoracle
A ROWID is an identification tag unique for each row of an Oracle Database table. The ROWID can be thought of as a virtual column, containing the ID for each row.
The oracle.sql.ROWID class i
- java获取方法的参数名
antlove
javajdkparametermethodreflect
reflect.ClassInformationUtil.java
package reflect;
import javassist.ClassPool;
import javassist.CtClass;
import javassist.CtMethod;
import javassist.Modifier;
import javassist.bytecode.CodeAtt
- JAVA正则表达式匹配 查找 替换 提取操作
百合不是茶
java正则表达式替换提取查找
正则表达式的查找;主要是用到String类中的split();
String str;
str.split();方法中传入按照什么规则截取,返回一个String数组
常见的截取规则:
str.split("\\.")按照.来截取
str.
- Java中equals()与hashCode()方法详解
bijian1013
javasetequals()hashCode()
一.equals()方法详解
equals()方法在object类中定义如下:
public boolean equals(Object obj) {
return (this == obj);
}
很明显是对两个对象的地址值进行的比较(即比较引用是否相同)。但是我们知道,String 、Math、I
- 精通Oracle10编程SQL(4)使用SQL语句
bijian1013
oracle数据库plsql
--工资级别表
create table SALGRADE
(
GRADE NUMBER(10),
LOSAL NUMBER(10,2),
HISAL NUMBER(10,2)
)
insert into SALGRADE values(1,0,100);
insert into SALGRADE values(2,100,200);
inser
- 【Nginx二】Nginx作为静态文件HTTP服务器
bit1129
HTTP服务器
Nginx作为静态文件HTTP服务器
在本地系统中创建/data/www目录,存放html文件(包括index.html)
创建/data/images目录,存放imags图片
在主配置文件中添加http指令
http {
server {
listen 80;
server_name
- kafka获得最新partition offset
blackproof
kafkapartitionoffset最新
kafka获得partition下标,需要用到kafka的simpleconsumer
import java.util.ArrayList;
import java.util.Collections;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.
- centos 7安装docker两种方式
ronin47
第一种是采用yum 方式
yum install -y docker
- java-60-在O(1)时间删除链表结点
bylijinnan
java
public class DeleteNode_O1_Time {
/**
* Q 60 在O(1)时间删除链表结点
* 给定链表的头指针和一个结点指针(!!),在O(1)时间删除该结点
*
* Assume the list is:
* head->...->nodeToDelete->mNode->nNode->..
- nginx利用proxy_cache来缓存文件
cfyme
cache
user zhangy users;
worker_processes 10;
error_log /var/vlogs/nginx_error.log crit;
pid /var/vlogs/nginx.pid;
#Specifies the value for ma
- [JWFD开源工作流]JWFD嵌入式语法分析器负号的使用问题
comsci
嵌入式
假如我们需要用JWFD的语法分析模块定义一个带负号的方程式,直接在方程式之前添加负号是不正确的,而必须这样做:
string str01 = "a=3.14;b=2.71;c=0;c-((a*a)+(b*b))"
定义一个0整数c,然后用这个整数c去
- 如何集成支付宝官方文档
dai_lm
android
官方文档下载地址
https://b.alipay.com/order/productDetail.htm?productId=2012120700377310&tabId=4#ps-tabinfo-hash
集成的必要条件
1. 需要有自己的Server接收支付宝的消息
2. 需要先制作app,然后提交支付宝审核,通过后才能集成
调试的时候估计会真的扣款,请注意
- 应该在什么时候使用Hadoop
datamachine
hadoop
原帖地址:http://blog.chinaunix.net/uid-301743-id-3925358.html
存档,某些观点与我不谋而合,过度技术化不可取,且hadoop并非万能。
--------------------------------------------万能的分割线--------------------------------
有人问我,“你在大数据和Hado
- 在GridView中对于有外键的字段使用关联模型进行搜索和排序
dcj3sjt126com
yii
在GridView中使用关联模型进行搜索和排序
首先我们有两个模型它们直接有关联:
class Author extends CActiveRecord {
...
}
class Post extends CActiveRecord {
...
function relations() {
return array(
'
- 使用NSString 的格式化大全
dcj3sjt126com
Objective-C
格式定义The format specifiers supported by the NSString formatting methods and CFString formatting functions follow the IEEE printf specification; the specifiers are summarized in Table 1. Note that you c
- 使用activeX插件对象object滚动有重影
蕃薯耀
activeX插件滚动有重影
使用activeX插件对象object滚动有重影 <object style="width:0;" id="abc" classid="CLSID:D3E3970F-2927-9680-BBB4-5D0889909DF6" codebase="activex/OAX339.CAB#
- SpringMVC4零配置
hanqunfeng
springmvc4
基于Servlet3.0规范和SpringMVC4注解式配置方式,实现零xml配置,弄了个小demo,供交流讨论。
项目说明如下:
1.db.sql是项目中用到的表,数据库使用的是oracle11g
2.该项目使用mvn进行管理,私服为自搭建nexus,项目只用到一个第三方 jar,就是oracle的驱动;
3.默认项目为零配置启动,如果需要更改启动方式,请
- 《开源框架那点事儿16》:缓存相关代码的演变
j2eetop
开源框架
问题引入
上次我参与某个大型项目的优化工作,由于系统要求有比较高的TPS,因此就免不了要使用缓冲。
该项目中用的缓冲比较多,有MemCache,有Redis,有的还需要提供二级缓冲,也就是说应用服务器这层也可以设置一些缓冲。
当然去看相关实现代代码的时候,大致是下面的样子。
[java]
view plain
copy
print
?
public vo
- AngularJS浅析
kvhur
JavaScript
概念
AngularJS is a structural framework for dynamic web apps.
了解更多详情请见原文链接:http://www.gbtags.com/gb/share/5726.htm
Directive
扩展html,给html添加声明语句,以便实现自己的需求。对于页面中html元素以ng为前缀的属性名称,ng是angular的命名空间
- 架构师之jdk的bug排查(一)---------------split的点号陷阱
nannan408
split
1.前言.
jdk1.6的lang包的split方法是有bug的,它不能有效识别A.b.c这种类型,导致截取长度始终是0.而对于其他字符,则无此问题.不知道官方有没有修复这个bug.
2.代码
String[] paths = "object.object2.prop11".split("'");
System.ou
- 如何对10亿数据量级的mongoDB作高效的全表扫描
quentinXXZ
mongodb
本文链接:
http://quentinXXZ.iteye.com/blog/2149440
一、正常情况下,不应该有这种需求
首先,大家应该有个概念,标题中的这个问题,在大多情况下是一个伪命题,不应该被提出来。要知道,对于一般较大数据量的数据库,全表查询,这种操作一般情况下是不应该出现的,在做正常查询的时候,如果是范围查询,你至少应该要加上limit。
说一下,
- C语言算法之水仙花数
qiufeihu
c算法
/**
* 水仙花数
*/
#include <stdio.h>
#define N 10
int main()
{
int x,y,z;
for(x=1;x<=N;x++)
for(y=0;y<=N;y++)
for(z=0;z<=N;z++)
if(x*100+y*10+z == x*x*x
- JSP指令
wyzuomumu
jsp
jsp指令的一般语法格式: <%@ 指令名 属性 =”值 ” %>
常用的三种指令: page,include,taglib
page指令语法形式: <%@ page 属性 1=”值 1” 属性 2=”值 2”%>
include指令语法形式: <%@include file=”relative url”%> (jsp可以通过 include