音频几个相关概念及心理声学模型
系列文章目录
音频格式的介绍文章系列:
音频编解码格式介绍:音频几个相关概念及心理声学模型
https://blog.csdn.net/littlezls/article/details/135499627
音频编解码格式介绍:音频编码格式介绍
https://blog.csdn.net/littlezls/article/details/135862140
音频编解码格式介绍(1) ADPCM:adpcm编解码原理及其代码实现
https://blog.csdn.net/littlezls/article/details/83501580
音频编解码格式介绍(2) MP3 :音频格式之MP3:(1)MP3封装格式简介
https://blog.csdn.net/littlezls/article/details/135705670
音频编解码格式介绍(2) MP3 :音频格式之MP3:(2)MP3编解码原理详解
https://blog.csdn.net/littlezls/article/details/135458169
音频编解码格式介绍(3) AAC :音频格式之AAC:(1)AAC简介
https://blog.csdn.net/littlezls/article/details/135692305
音频编解码格式介绍(3) AAC :音频格式之AAC:(2)AAC封装格式ADIF,ADTS,LATM,extradata及AAC ES存储格式
https://blog.csdn.net/littlezls/article/details/135705383
音频编解码格式介绍(3) AAC :音频格式之AAC:(3)AAC编解码原理详解
https://blog.csdn.net/littlezls/article/details/135777833
文章目录
- 系列文章目录
- 前言
- 1、几个重要的概念
-
- (1)SPL(Sound Pressure Level),
- (2)静音门槛曲线
- (3)临界频带(Critical Bands)
- (4)频域上的遮蔽效应
- (5)时域上的遮噪曲线
- 2、心理声学
- 参考资料
前言
本文主要介绍音频几个相关概念及心理声学模型,常见的有损压缩都要用到心理声学模型。
本文网址:https://blog.csdn.net/littlezls/article/details/135499627
1、几个重要的概念
(1)SPL(Sound Pressure Level),
表示声音强度的名词,SPL是评价听觉刺激强度的标准,也就是说,我们对外界声音的感觉强度完全由它决定,其单位为dB。
(2)静音门槛曲线
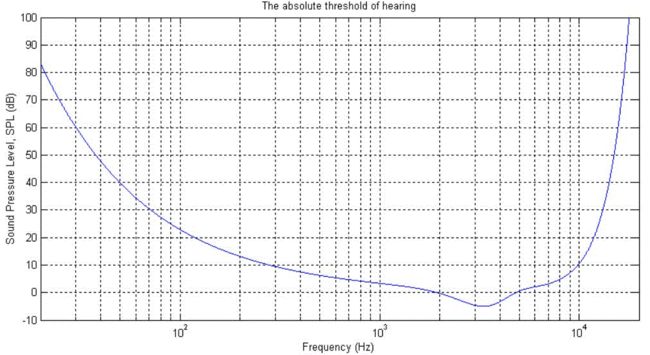
横轴为f(HZ),纵轴为SPL(dB),若声音强度(SPL)低于该曲线的值表示人听不到声音,如下图所示。从图中可以得出几条结论:
第一,人的听觉频率范围大约在10Hz~20KHz之间
第二,大约在3KHz到4KHz时SPL有最小值,也就是所人在该频率范围内的听觉最敏锐
(3)临界频带(Critical Bands)
因为人耳对不同频率的敏感程度不同,MPEG1/Audio将22KHz范围内可感知的频率范围划分为23~26个临界频带,如下图。
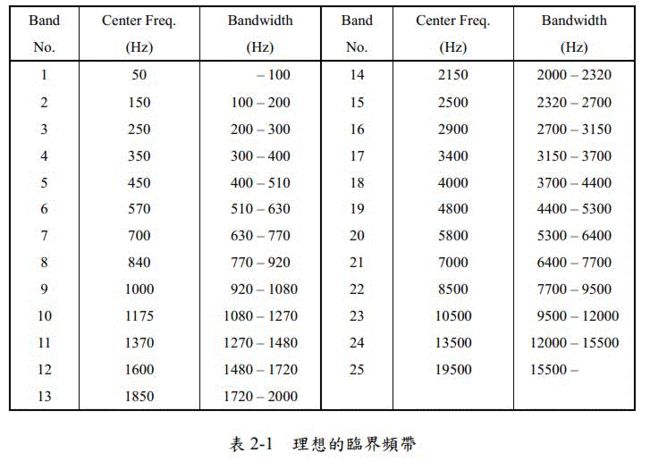
从表中能得出几条结论:
第一,当当中心频率值在500Hz以内时,不同临界频带的带宽()几乎相同,约100Hz
当中心频率值大于500Hz后,随着f值得上升,临界频带的带宽剧增
第二,从表中也可以看出,人耳对低频的解析度要比高频更好
(4)频域上的遮蔽效应
SPL较大的信号容易掩盖频率相近的SPL较小的信号,叫声音的遮蔽效应。就比如在机场很难听到打电话的声音。
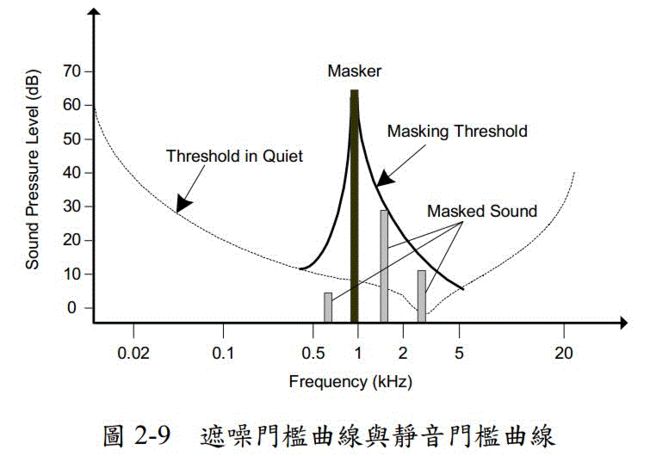
如上图所示,Masking Threshold将大约在0.7kHz,1.6kHz和2.3kHz的信号遮蔽了,当然0.7kHz信号的SPL在静音门槛曲线之下,不被遮蔽也是听不到的。
在这里,涉及3个重要的量——SMR、SNR和MNR。
SMR(signal-to-maskratio):指在一个临界频带内,从masker到遮噪门槛值的距离。
SNR(signal-to-noiseratio):指信号经过m位元量化后的信噪比,等于量化前信号方差和量化噪声的方差之比,。
MNR(mask-to-noise):用来测量人耳可以感知的失真参数,
如下图所示,展示了3者之间的关系,其中的灰色区域Critial Band指临界频带,Masking Threshold就是遮噪门槛曲线,图中的SMR指在临界频带内最大的SMR值。
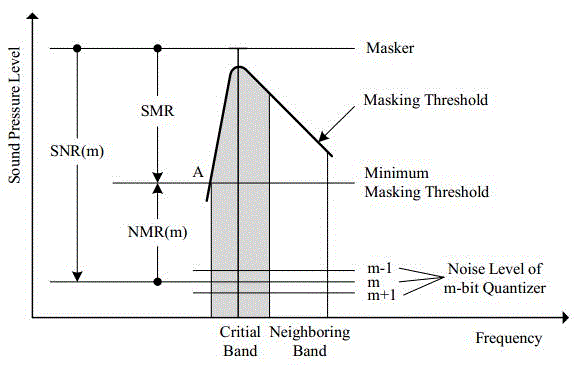
值得注意的是,(1)我们上面讨论的SMR、SNR和NMR三者都是基于临界频带的,但遮蔽效应不仅对临界频带有影响,对临近的临界频带也有影响,称为遮噪延展性(2)上图所显示的是一个临界频带内的一条遮噪曲线,实际情况存在多条遮噪曲线,结果是这些曲线的叠加。
(5)时域上的遮噪曲线
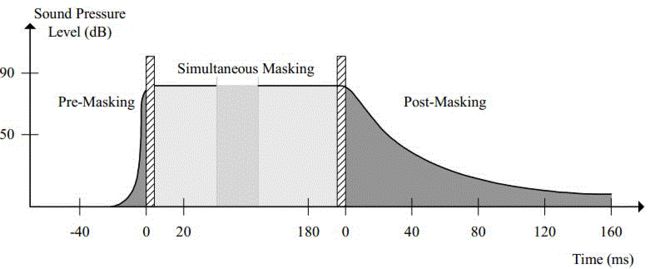 从上图可以看出,在一段很短的时间内(200ms左右),若出现了两个声音,不管出现的先后顺序,SPL大的声音(masker)会遮蔽SPL小的声音(maskee)。
从上图可以看出,在一段很短的时间内(200ms左右),若出现了两个声音,不管出现的先后顺序,SPL大的声音(masker)会遮蔽SPL小的声音(maskee)。
若maskee出现在前,则遮噪曲线如上图的Pre-Masking;若maskee出现在后,则遮噪曲线如上图中的Post-Masking。由图中很容易看出,Post-Masking要比Pre-Masking在时间轴上要长很多。Pre-Masking能遮蔽前回音,这是选择MDCT窗口的一个依据。
2、心理声学
感知音频编码器是利用人类听觉系统的掩蔽效应,在不降低主观感知音频质量的情况下,删除冗余的信息进行存储和传输。也就是说感知音频编码器是“主动积极地”压缩数字音频,从而使高质量、低比特率的音频信号可以在网络及通信系统中传输。
输入的原音频信号在时间域上被划分为帧,并在每一帧内分解为多个频带,称为“子带”,从而将输入的音频信号其划分为“时频段”。当在每个时频段中对信号进行量化以降低比特率时,会引入量化噪声(quantization noise)。当量化噪声被原音频信号掩盖或低于绝对听力阈值(absolute threshold)时,则无法被听见。因此,如果量化噪声由下沿抵达掩蔽阈值,则可以实现最有效的编码。
心理声学模型(Psychoacoustic model)的功能就是分析原音频信号来计算每个时频段的量化噪声的掩蔽阈值。因此,它可以在音频信号无失真的情况下,最有效地为音频信号的数字表达分配比特。由于提高量化步长会增加量化噪声的强度,所以掩蔽阈值较低的时频段需要被精细地量化。掩蔽阈值较高的时频段则可以被粗糙地量化,以降低比特率。
研究声音心理学模型用途有:
(1)研究模型的感知熵Perceptual EntropyPE值决定做MDCT变换时使用长窗框还是短窗框
PE能显示特定信号在理论上的压缩极限。PE的单位是bits/sample,代表每个取样在维持CD音质的情况下,能够压缩到的最低位元数。MP3中定义,当PE>1800时,使用短窗框的MDCT来处理该grannul(MP3每个数据帧包含2个grannul,每个grannul包含18*32个subband采样)的子频带信号。因为当PE>1800表示这段音讯变化比较大,可能产生回音,不适合使用长框。
(2)研究模型的SMR值决定量化编码时的比特数分配
对于第二条,下面的位元分配将给出解释。
(1)位元分配
位元分配目的是使每个频带的MNR达到最大,使音质最佳。过程为:寻找最小的MNR频带,分配位元给该频带以提高MNR,接着重新计算各频带的MNR。重复上述过程,直到位元分配结束。
(2)非均匀量化
其中SMR由声音心理学模型提供,SNR信噪比则是由量化确定的。
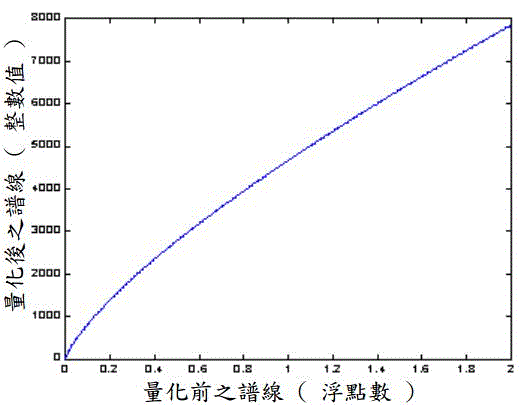
下图为量化器的输入输出曲线,量化器的输入为浮点值频率,输出为整形值的频率。
由图知,量化器将输入的浮点值量化后变为整型值,且量化过程为非线性非均匀的。
参考资料
[1]:MP3编码分析:https://blog.csdn.net/xiahouzuoxin/article/details/7849249
[2]:心理声学模型在感知音频编码中的应用:https://blog.csdn.net/Jianing_Wang/article/details/105779558