OCR-paddleocr
PaddleOCR 分为 Detection(文本检测)、Direction classifier(方向分类器)和 Recognition(文本识别)三部分,因此 需要三个模型。
一、介绍
-
PaddleOCR是一款超轻量、中英文识别模型
-
目标是打造丰富、领先、实用的文本识别模型/工具库
-
3.5M实用超轻量OCR系统,支持在服务器,移动,嵌入式和IoT设备之间进行培训和部署
-
同时支持中英文识别;支持倾斜、竖排等多种方向文字识别
-
支持GPU、CPU预测
-
可运行于Linux、Windows、MacOS等多种系统
-
用户既可以通过PaddleHub很便捷的直接使用该超轻量模型,也可以使用PaddleOCR开源套件训练自己的超轻量模型
体积小、运行快、简单方便、性能好、中英文
二、安装
1、如果机器上装了 CUDA 9 或 CUDA 10(参考windows10安装CUDA),请运行:python3 -m pip install -i Simple Index paddlepaddle-gpu;
没有可用的GPU,则安装CPU版本:python3 -m pip install -i Simple Index paddlepaddle
2、pip3 install -i Simple Index "paddleocr>=2.0.1"
windows上安装会报错:提示需要安装 Microsoft Visual C++ 14.0
解决:下载python_Levenshtein的whl文件,pip安装
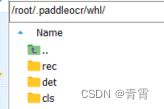
linux模型保存在: /root/.paddleocr/whl/,分别对应检测、识别、分类
三、paddleocr使用
3.1、参数
|
Parameter
|
Description
|
Default value
|
|
use_gpu
|
是否启用GPU
|
TRUE
|
|
gpu_mem
|
GPU memory size used for initialization
|
8000M
|
|
image_dir
|
The images path or folder path for predicting when used by the command line
|
|
|
det_algorithm
|
选择的检测算法类型
|
DB
|
|
det_model_dir
|
文本检测推理模型文件夹。 参数传递有两种方式:
|
None
|
|
det_max_side_len
|
图像长边的最大尺寸。 当长边超过这个值时,长边会调整到这个大小,短边会按比例缩放
|
960
|
|
det_db_thresh
|
Binarization threshold value of DB output map
|
0.3
|
|
det_db_box_thresh
|
The threshold value of the DB output box. Boxes score lower than this value will be discarded
|
0.5
|
|
det_db_unclip_ratio
|
The expanded ratio of DB output box
|
2
|
|
det_east_score_thresh
|
Binarization threshold value of EAST output map
|
0.8
|
|
det_east_cover_thresh
|
The threshold value of the EAST output box. Boxes score lower than this value will be discarded
|
0.1
|
|
det_east_nms_thresh
|
The NMS threshold value of EAST model output box
|
0.2
|
|
rec_algorithm
|
选择的识别算法类型
|
CRNN(卷积循环神经网络)
|
|
rec_model_dir
|
文本识别推理模型文件夹。 参数传递有两种方式:
|
None
|
|
rec_image_shape
|
图像形状识别算法
|
"3,32,320"
|
|
rec_batch_num
|
When performing recognition, the batchsize of forward images
|
30
|
|
max_text_length
|
识别算法可以识别的最大文本长度
|
25
|
|
rec_char_dict_path
|
the alphabet path which needs to be modified to your own path when rec_model_Name use mode 2
|
./ppocr/utils/ppocr_keys_v1.txt
|
|
use_space_char
|
是否识别空格
|
TRUE
|
|
drop_score
|
按分数过滤输出(来自识别模型),低于此分数的将不返回
|
0.5
|
|
use_angle_cls
|
是否加载分类模型
|
FALSE
|
|
cls_model_dir
|
分类推理模型文件夹。 参数传递有两种方式:
|
None
|
|
cls_image_shape
|
图像形状分类算法
|
"3,48,192"
|
|
label_list
|
label list of classification algorithm
|
['0','180']
|
|
cls_batch_num
|
When performing classification, the batchsize of forward images
|
30
|
|
enable_mkldnn
|
是否启用 mkldnn
|
FALSE
|
|
use_zero_copy_run
|
Whether to forward by zero_copy_run
|
FALSE
|
|
lang
|
支持语言,目前只支持中文(ch)、English(en)、French(french)、German(german)、Korean(korean)、Japanese(japan)
|
ch
|
|
det
|
ppocr.ocr 函数执行时启用检测
|
TRUE
|
|
rec
|
ppocr.ocr func exec 时启用识别
|
TRUE
|
|
cls
|
Enable classification when ppocr.ocr func exec((Use use_angle_cls in command line mode to control whether to start classification in the forward direction)
|
FALSE
|
|
show_log
|
Whether to print log
|
FALSE
|
|
type
|
Perform ocr or table structuring, 取值在 ['ocr','structure']
|
ocr
|
|
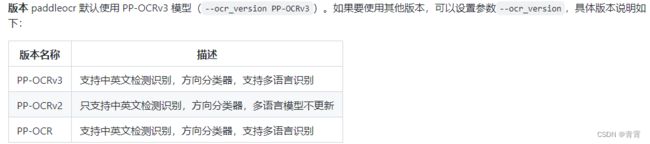
ocr_version
|
OCR型号版本号,目前模型支持列表如下:
|
PP-OCRv3
|
3.2、基本使用
测试数据集: PaddleOCR provides a series of test images, click here to download,包含测试图片、测试图表、字体
1、文本检测、方向分类、文本识别:设置参数--use_gpu false禁用gpu设备,--use_angle_cls true 加载分类模型
paddleocr --image_dir ./imgs_en/img_12.jpg --use_angle_cls true --lang en --use_gpu false
输出将是一个列表,每个项目包含边界框、文本和识别置信度:

2、仅文本检测:将 --rec 设置为 false
paddleocr --image_dir ./imgs_en/img_12.jpg --use_angle_cls true --lang en --use_gpu false --rec false
输出将是一个列表,每个项目仅包含边界框

3、仅文本识别:将 --det 设置为 false
paddleocr --image_dir ./imgs_en/img_10.jpg --use_angle_cls true --lang en --use_gpu false --det false
输出将是一个列表,每个项目都包含文本和识别置信度:

四、代码使用
检测、角度分类和识别:
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr supports Chinese, English, French, German, Korean and Japanese.
# You can set the parameter `lang` as `ch`, `en`, `fr`, `german`, `korean`, `japan` to switch the language model in order.
ocr = PaddleOCR(
use_angle_cls=True,
lang='en',
use_gpu=False,
det_model_dir="/root/.paddleocr/whl/det/en/en_PP-OCRv3_det_infer/", # 检测模型
cls_model_dir="/root/.paddleocr/whl/cls/ch_ppocr_mobile_v2.0_cls_infer/", # 分类模型
rec_model_dir="/root/.paddleocr/whl/rec/en/en_PP-OCRv3_rec_infer/" # 识别模型
) # need to run only once to download and load model into memory
img_path = '/ppocr_img/imgs_en/img_12.jpg'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
# draw result
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf') # 字体需要准备
im_show = Image.fromarray(im_show)
im_show.save('result.jpg') 输出:


五、easyocr VS paddleocr

easyocr识别结果:

paddleocr识别结果:

paddleocr更准确