软件定义数据中心(SDDC)最后的两块拼图 – GPU池化和内存池化
记得2012年VMWARE首先提出SDDC (Software Defined Data Center)这个说法。当时VMWARE作为CPU虚拟化的先行者和领导者,除了手握SDC (Software Defined Compute)、即CPU虚拟化技术外, 同时也具备了SDS (Software Defined Storage) 和 SDN (Software Defined Network)技术能力。彼时SDS/SDN都是新兴的技术,同时也是云计算的支柱。
现在十年过去了, 软件定义数据中心的技术演进好像没有什么大的变化。业界中我们看到了AI的兴起,随之GPU的重要性达至了前所未有的程度。根据中国信息通信研究院的数据(见如下), 2021年起,智算算力需求和增速的已经超越了基础算力。

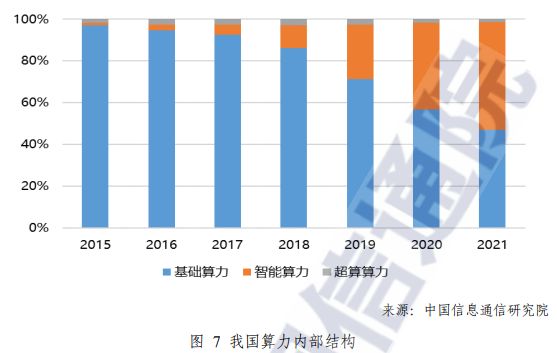
图源:中国信通院 《中国算力发展指数白皮书》
可见,以GPU为代表的AI智能算力(GPU /FPGA /ASIC)设备的重要性未来会很大可能超越CPU这类通用算力设备。
但据统计,GPU却是在数据中心里面属于低利用率的核心元件——根据AWS的数据显示,其GPU平均利用率仅为10~30%;国内有不少用户的GPU利用率甚至不足10%,也就是说目前GPU的利用率非常低。
其主要的原因是目前GPU在数据中心的使用基本是以物理GPU独占使用为主(使用GPU直通虚机或容器)。很少用户使用GPU虚拟化技术,更没有使用GPU虚拟化高阶技术——池化!
数据中心另外一个利用率较低的元件,就是内存了。微软Azure做过调查, 他们有高达25%的内存都是闲置的,有50%的虚拟机使用的内存占比仅为50%,大约有一半的内存没有被用上。谷歌也做过类似的调查, 谷歌服务器集群中DRAM内存平均利用率约为40%, 其内存利用率也有很大的可提升空间。
综合上面所述的情况可知, 目前在数据中心使用软件定义技术来演进的时候,我们目前还存在着这些问题。那么在数据中心朝高效率低能耗演进的方向上,我们必须要解决这两个问题。
SDDC中解决GPU利用率过低的方案
GPU池化
上文叙述过GPU利用率过低的问题,主要是物理GPU独占的使用方式导致。这个就如同二十多年前CPU没有虚拟化的情况一样。那么我们是否可以使用同样的思路方向解决这个问题呢?这个答案显然是可以的!
我们可以将物理的GPU抽象虚拟化成软件定义的虚拟GPU。根据应用的要求按需提供算力资源(包括算力和显存)——这就是GPU虚拟化技术。
谈论到GPU虚拟化,可能有人就会疑惑:N公司早就推出了grid vGPU技术来实现GPU虚拟化。不过现在大家也没有看到有什么数据中心利用这个技术来提升GPU的利用率啊?对的,这个描述是符合现实情况的。就像二十多年前的INTEL,绝不会主动去发明类似VMWARE的CPU虚拟化技术去提高CPU利用率、从而减少CPU的销售量,同样的道理, N公司也找不到任何好的商业理由去投入更大精力做GPU虚拟化这个事情。其实grid vGPU本身只是做了一个物理GPU的简单等比例切分,只能局限在一个物理服务器节点的GPU切分,它不能做到整个数据中心的GPU的池化。
要想将GPU的算力资源利用提升到最高效率,需要将GPU的算力资源抽象虚拟化成类似一个算力“大水池”, 每个需要使用算力资源的应用就好像水龙头一样,后面可以接入”大水池“内实现按需所取”水量“(算力资源)。这个就是GPU虚拟化目前最高阶段 —— GPU池化,见如下的GPU虚拟化技术演进的示意图:
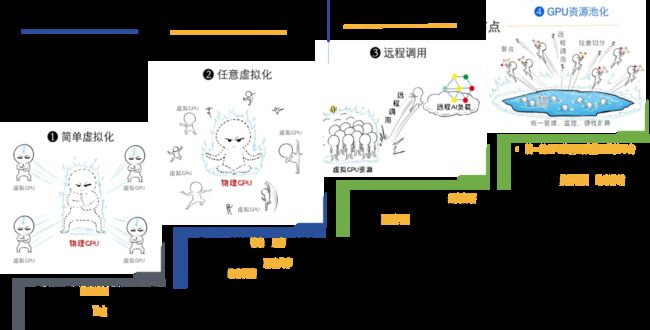
GPU资源池化技术演进四阶段
趋动科技的OrionX AI算力池化软件就是使用了软件定义算力的方式实现了GPU池化,从而最大化提高数据中心中的GPU利用率!通过如下的简单示意图,可以看到OrionX通过软件定义算力池,各个不同的AI应用可以在池内调取所需的GPU算力资源,解决了简单GPU虚拟化不能完美解决的利用率低问题。
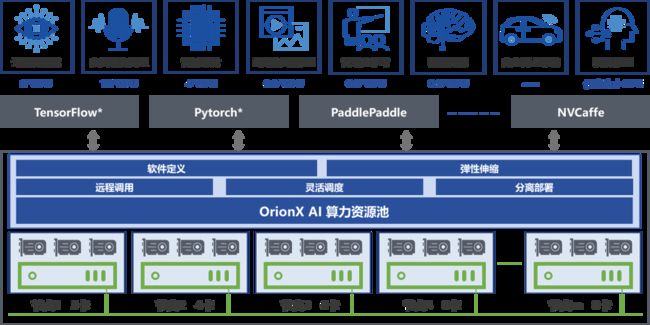
OrionX AI算力池化解决方案
从目前业界GPU虚拟化的技术方案来说, 软件定义方式实现的GPU池化是符合现代化的软件定义数据中心演进中解决算力效率的最好的技术路线。可以说,软件定义的GPU池化是软件定义数据中心技术中最后的拼图之一!
SDDC提高内存利用率的技术
CXL实现内存池化
目前大型数据中心内也存在着内存利用率不到一半的情况,很明显这个也是一个巨大的浪费!但是为什么内存利用率是这个情况呢?微软的Azure认为DRAM使用效率低的一个主要原因是”memory stranding“,内存滞留。这个是指服务器的所有CPU核全部被租用,即分配给客户虚机之后,仍有未分配的内存容量,这部分内存将无法被租用,产生滞留。
如何使用这部分“滞留”内存?试想一下,如果我们能将内存解耦分离到一个‘内存池‘,同时这个’内存池‘可以共享给各个主机访问使用,那么是否就解决了这个问题呢?
是的,目前业界正在使用CXL(Compute Express Link)技术来实现这个目标。CXL是Intel牵头推出的一种全新的互联技术标准,CXL技术联盟已经出超过165个成员,几乎涵盖了所有主要的CPU、GPU、内存、存储和网络设备制造商,见下图 (或参考链接CXL成员 - https://www.computeexpresslink.org/members):

CXL技术联盟成员(部分)
现在CXL现在已经发展到3.0版本了,见下图:
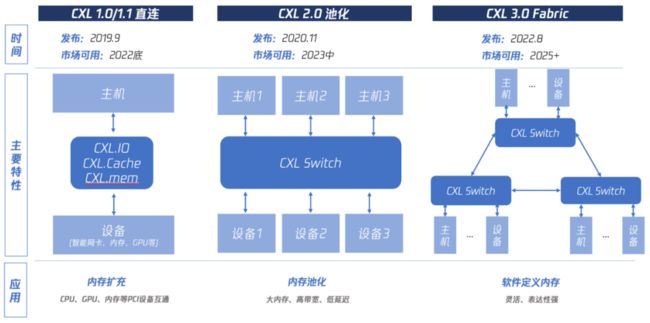
CXL 3.0架构图
-
CXL1.0/1.1 可归纳为“直连”,也就是让主机CPU可以直接访问PCIe设备的内存,具体分为三个子协议:CXL.io用于设备注册发现、CXL.cache用于设备访问CPU内存、CXL.mem 用于CPU访问设备内存。这可达到主机内存扩充的目的。
-
CXL2.0 可归纳为“池化”,就是让多个主机CPU和多个设备可通过一个CXL Switch硬件连接在一起,可以相互访问,在较小延迟影响的前提下提供高容量大带宽。这可达到内存池化的目的。
-
CXL3.0 可归纳为Fabric,可以让多个Switch形成级联结构,支持更复杂的结构。这可以达到“软件定义内存”的目的。
通过CXL的协议,可以令到CPU内存空间和附加设备上内存实现一致性,所以使得不同的XPU可以同时访问同一块芯片。换句话来说,对于应用编程人员来说附加设备(芯片)的内存与CPU可以访问内存的地址是统一编址的。这样就令memory sharing具备了可行的基础。那么我们可以通过高速的CXL交换机将多个主机互联组成一个高速‘内存网络‘, 通过该内存网络加上上述CXL的地址一致性的能力就可以组成了一个完全可以共享的内存池,解决了‘memory stranding’的问题!架构可以参考下图:
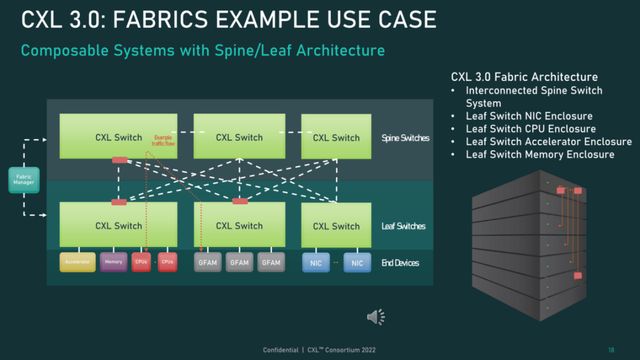
当然组成了内存池化的架构后,必然也需要管理软件来完成具体的功能,例如需要管理不同物理内存的地址,哪一块内存mapping到哪个主机,内存容量优化(压缩和去重), 数据保护和安全等等。逻辑上来说,这个可以说是软件定义内存的实现方式!
总 结
其实从存储池化到GPU池化和内存池化,无论那种池化, 我们都可以看到需要先做解耦,就是将需要使用的资源不用绑定到应用运行所在的物理主机,例如存储/GPU/内存都不一定在应用运行的物理主机内。那么解耦后,资源可能在本地、也可能在远程主机,所以远程调用资源就变为必须的功能之一,这样才可以完全地实现池化。
从目前业界的情况来说,内存池化的技术,不像GPU池化那样具备较多的实际客户案例,而且内存池化这种技术更多是大型数据中心需求的,也多在大型数据中心测试和实验。GPU池化是更像CPU虚拟化和存储池化一样,是一个更具普遍需求和适用性更广的技术。总的来说,通过软件定义的方式实现GPU池化和内存池化,是现代化软件定义数据中心的最后2块拼图。完成了这2块拼图后,才可以真正地称之为“ SDDC - 软件定义数据中心” !
参考文章:
· 联手体系结构专业委员会:“GPU池化”术语发布 | CCF术语快线-中国计算机学会
https://www.ccf.org.cn/Media_list/gzwyh/jsjsysdwyh/2022-06-17/789819.shtml
· 一文告诉你CXL是什么,有什么新的机会
https://zhuanlan.zhihu.com/p/592735085
· CXL 3.0标准发布,速度翻番
https://baijiahao.baidu.com/sid=1740186624339843668&wfr=spider&for=pc
· 公有云的CXL内存池化
https://zhuanlan.zhihu.com/p/640945820
· MemVerge范承工:CXL正在迎来大内存的曙光
https://www.doit.com.cn/p/487781.html