Hive调优
- 改硬件.(CPU, 磁盘, 内存)
- 开启或者增大某些设置(配置). 负载均衡, 严格模式(禁用低效SQL), 动态分区数...
- 关闭或者减小某些设置(配置). 严格模式(动态分区), 推测执行...
- 减少IO传输. Input(输入)/Output(输出), 列存储orc, 压缩协议snappy, join优化
Hive调优--参数
概述:
hive的参数配置, 就是在那里配置hive的参数信息, 根据配置地方不同, 作用范围也不一样.
配置方式:
1. set方式进行设置.
2. 命令行方式进行设置.
3. 配置文件方式进行设置.
参数设置优先级
set参数声明 > 命令行参数 > 配置文件参数
注:一般执行SQL需要指定的参数,都是通过 参数声明 方式进行配置
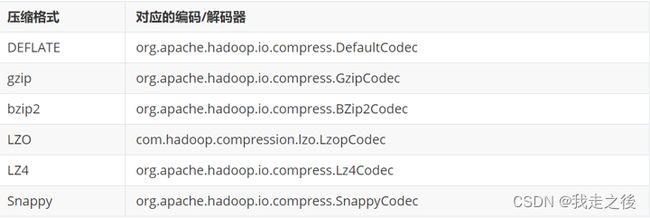
Hive调优--压缩和存储
1.Hive压缩方式:
概述:
压缩方式就类似于windows的压缩包, 可以降低传输, 提高磁盘利用率. 区分压缩协议好坏的参考维度:
1. 压缩比, 即: 压缩后文件大小.
2. 解压速度, 即: 读的速度.
3. 压缩速度, 即: 写的速度.
2.Hive表存储方式
概述:
分为 行存储 和 列存储两种.
具体划分:
行存储: TextFile(默认), SequenceFile
列存储: ORC(推荐), Parquet
行存储 和 列存储的区别?
行存储:
优点: select * 效率高.
缺点: select 列 效率低, 每列数据类型不一致, 密集度较低, 占用资源较多(CPU, 磁盘, 内存)
列存储:
优点: select 列 效率高, 每列数据类型一致, 密集度较高, 占用资源较少(CPU, 磁盘, 内存)
缺点: select * 效率低.
Hive调优--Fetch抓取
核心点:
在执行HiveSQL的时候, 能不转MR, 就不转MR.
设置方式:
set hive.fetch.task.conversion=fetch抓取的模式;Fetch抓取模式介绍:
more: 默认的, 全表扫描, 查询指定的列, limit分页查询, 简单查询不走MR, 其它的要转MR任务.
minimal: 全表扫描, 查询指定的列, limit分页查询不走MR, 其它的要转MR任务.
none: 所有的HiveSQL, 底层都要转MR.、
Hive调优--本地模式
核心点:
如果HiveSQL必须要转成MR任务来执行, 则尽量在本机(本地)直接执行, 而不是交由Yarn来调度执行, 针对于数据量比较小的需求, 可以提高效率.
相关设置:
开启本地mr
set hive.exec.mode.local.auto=true;设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=134217728;设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=4;Hive调优--SQL优化
列裁剪.
能写 select 列1, 列2... 就不要写 select *
分区裁剪
编写SQL的时候, 能使用分区条件, 建立一定要写分区字段.
开启负载均衡
如果key分布不均, 就可能导致数据倾斜的问题(Group by数据倾斜), 可以通过 开启负载均衡解决.
开启负载均衡之后, 如果遇到了GroupBy数据倾斜问题, 程序的底层会开启两个MR任务.
第1个MR负责将(发生数据倾斜的)数据随机打散, 交由不同的ReduceTask任务来处理, 获取结果.
第2个MR会将 第1个MR的结果当做数据源来处理, 进行最终的合并动作, 获取最终结果.
Hive调优--动态分区
建议动态分区的时候, 关闭严格模式(默认开启), 严格模式要求: 动态分区的时候, 至少指定1个静态分区.
格式:
动态分区: partition(分区字段)
静态分区: partition(分区字段=值)
重点参数:
set hive.exec.dynamic.partition.mode=nonstrict;
-- 开启非严格模式 默认为 strict(严格模式)
set hive.exec.dynamic.partition=true;
-- 开启动态分区支持, 默认就是true
可选参数
set hive.exec.max.dynamic.partitions=1000;
-- 在所有执行MR的节点上,最大一共可以创建多少个动态分区。
set hive.exec.max.dynamic.partitions.pernode=100;
-- 每个执行MR的节点上,最大可以创建多少个动态分区
set hive.exec.max.created.files=100000;
-- 整个MR Job中,最大可以创建多少个HDFS文件Hive调优--并行度和并行执行机制
并行度解释: 即: 根据业务要求, 增大或者减少MapTask 和 ReduceTask的任务数.
并行执行: 默认Hive同一时间只能执行1个阶段, 如果多个阶段之间的依赖度比较低, 就可以开启并行执行, 让多个阶段同时执行, 降低MR job任务的执行时间.
set hive.exec.parallel=true;
-- 打开任务并行执行 默认false
set hive.exec.parallel.thread.number=16;
-- 同一个sql允许最大并行度,默认为8。Hive调优--严格模式
核心点:
禁用低效的SQL.
设置方式:
set hive.mapred.mode=strict | nonstrict;细节:
1. 这个严格模式是禁用低效的SQL, 和动态分区的严格模式没有任何关系.
2. 严格模式是禁用低效的SQL, 例如, 如下的SQL是禁止执行的:
A. 分区表, 查询时, 没有写分区字段.
B. order by全局排序时, 没有写limit
C. 禁用笛卡尔积.
Hive调优--推测执行
核心点:
类似于木桶效应(装多少水取决于最短的哪个木板), job任务执行多长时间, 取决于执行最慢的哪个任务.
针对于这种情况, 可以基于哪些"拖后腿"(执行速度过于慢)的任务, 可以搞1个它的备份任务, 让这个备份任务.
和它处理同一份数据, 谁先执行完毕, 就将其结果作为最终结果.
建议:
默认是开启的, 建议关闭, 具体: 看需求.