KMP算法——(算法竞赛c++实现)
目录
1、了解KMP算法;
2、普通暴力做法与KMP的区别;
2.1、暴力求解:
2.2、KMP算法求解
3、KMP中有关ne[N]数组的理论;
4、构造ne数组
5、例题——KMP字符串来喽
1、了解KMP算法;
首先我们需要了解什么是KMP算法?
1、首先这是一个字符串匹配算法,是在暴力(两个for镶套)做法上进行优化从而得到的,与暴力做法相比KMP算法大大减少了时间复杂度;
2、KMP算法,它是在1977年由Knuth、Morris、Pratt联合发表,因此取这三位创始人的首字母最终组成KMP这一名字;
3、KMP主要思想:拿空间换时间;
4、KMP时间复杂度:O(m+n);
5、 KMP主要分两步:求next数组、匹配字符串。
2、普通暴力做法与KMP的区别;
KMP字符串题目概述:
给定一个模式串 S(长串),以及一个模板串 P(短串),所有字符串中只包含大小写英文字母以及阿拉伯数字。模板串 P 在模式串 S 中多次作为子串出现。求出模板串 P 在模式串 S 中所有出现的位置的起始下标。
2.1、暴力求解:
首先我们会联想到用两个for循环镶套进行依次遍历,即是设置两个指针分别指向模式串和模板串,两个指针从左到右一个个地匹配,如果这个依次向右匹配过程中有某个字符不匹配,模板串(p)指针就跳回到第一位,模式串(s)指针向右移动一位。
暴力求法运行操作图如下所示:
1.首先两者均从下标为0处进行操作;
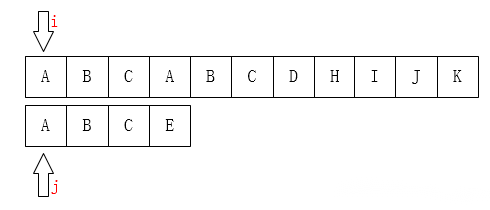
2.接着两个指针依次往后进行对比,对比相同下标字符是否相同;

3.当相同下标字符不同的情况,i指针向右移动一位,j指针从第一位开始;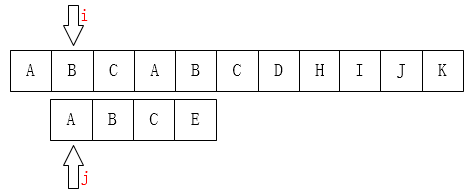
(暴力求解过程中两个指针都有回溯,从而浪费了大量的时间导致tql)
暴力求法代码如下所示:
#include
using namespace std;
int n, m, t;
string s, p;//s为较长字符串(模式串)
int main()
{
cin >> n >> p >> m >> s;
for (int i = 0; i < m; i++)
{
bool flag = true;// 最开始是匹配成功的状态
for (int j = 0; j < n; j++)
{
if (s[i + j] != p[j])
{
flag = false;//只要有一个不通过,则false
break;
}
}
if (flag == true)
{
cout << i << " ";
}
}
return 0;
}
2.2、KMP算法求解
KMP思想:当出现字符串不匹配的情况时,可以知道一部分之前已经匹配的的文本内容,利用这些信息避免从头再去做匹配,同时比较指针不回溯, 而是直接跳过一些字符串(利用next数组),使得原来模式串中的前缀直接移动到后缀位置上。(其中前缀表担负重任)
KMP运行操作图如下所示:
1.我们可以发现因为主串在到第四位的时候匹配失败,到第四位之前和主串都匹配,如果继续将主串指针右移一位的话就会不匹配。但之前因为我们已经知道前面三个字符都是匹配的,那我们就可以利用这个信息找出接下来指针该移动的位置。思路就是可以让i先不动,只需要移动j即可;
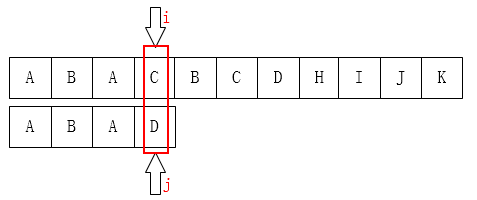
2.在每次失配时,不是把p串往后移一位,而是把p串往后移动至下一次可以和前面部分匹配的位置,这样就可以跳过大多数的失配步骤,从而减少运算次数降低了时间复杂度。而每次p串移动的步数就是通过查找next[ ]数组(接下来会继续介绍)确定的。
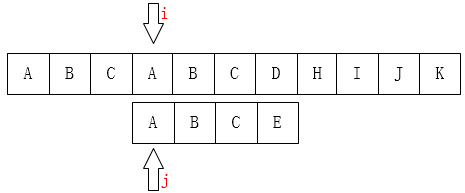
3、KMP中有关ne[N]数组的理论;
前缀:除了最后一个字符以外,该字符串的全部头部组合;
例如:ababa
其前缀为:a、ab、aba、abab;
其后缀为:a、ba、aba、baba;
后缀:除了第一个字符以外,该字符串的全部尾部组合;
例如:ABCDABD
其前缀为:A、AB、ABC、 ABCD、ABCDA、ABCDAB;
其后缀为:D、BD、ABD、DABD、CDABD、BCDABD;
部分匹配表(前缀表):一个字符串的前缀和后缀的最长公有元素的长度;(不包括自身)
用下面的具体示例进行描述:
1、"A"的前缀和后缀都为空集,共有元素的长度为0;2、"AB"的前缀为{ A },后缀为{ B },共有元素的长度为0;
3、"ABC"的前缀为{ A, AB },后缀为{ C, BC },共有元素的长度0;
4、"ABCD"的前缀为{ A, AB, ABC },后缀为{ D, CD, BCD },共有元素的长度为0;
5、"ABCDA"的前缀为{ A, AB, ABC, ABCD },后缀为{ A, DA, CDA, BCDA },共有元素为"A",长度为1;
6、"ABCDAB"的前缀为{ A, AB, ABC, ABCD, ABCDA },后缀为{B, AB, DAB, CDAB, BCDAB],共有元素为"AB",长度为2;
7、"ABCDABD"的前缀为{A, AB, ABC, ABCD, ABCDA, ABCDAB},后缀为{D, BD, ABD, DABD, CDABD, BCDABD},共有元素的长度为0。
idx : 数组的下标;
ne[i] : 以i为结尾的部分匹配的值,ne数组即为前缀表;
例如:aabaaf
p[N] a a b a a f
idx 1 2 3 4 5 6
ne[N] 0 1 0 1 2 01、ne[N]数组的含义:它是一个前缀表,或者说是一个前缀表达的某种变形 ,目的是储存p[ 1, j ]串中前缀和后缀相同的最大长度(部分匹配值);
2、通过求部分匹配值求出ne[N]的值;
3、ne[N]是一个前缀表,它的作用是用来回退的,它记录了模式串和模板串不匹配时,模板串应该从哪里重新匹配的信息;
模板串每次向后移动位数:移动位数 = 已匹配的字符数 - 对应的部分匹配值***很重要***
移动位数 = 已匹配的字符数 - 对应的部分匹配值(最长共有元素长度)
例如:
s串:aabaabaaf
p串:aabaaf
1、首先p串与s串的前五位相互匹配,但当p串的第六位(f)与s串(b)不匹配时,此时就要利用KMP的方法将p串进行向后移动;
2、求p串中出最长公有元素的长度(储存在ne[N]中);(本例题中最长共有元素长度为2)
3、移动位数 = 已匹配的字符数 - 对应的部分匹配值;(本例题移动位数为“5-2=3”)
4、移动之后为:
s串:aabaabaaf
p串: aabaaf
4、构造ne数组
主要有如下三步:
一、初始化ne数组;
二、处理后缀不同的情况;
三、处理后缀相同的情况;
一、初始化ne数组;
首先定义两个指针i和j,j是指向前缀的起始位置,i是指向后缀的起始位置,然后对ne数组进行初始化赋值。
int j = 0;
ne[0] = j;二、处理后缀不同的情况;
因为j是从0开始的,所以i需要从2开始,比较p[i]与p[j+1]是否相同,遍历模式串循环下标从2开始;
for (int i = 2 ; i <= n; i++)如果s[i]与s[j+1]不相同,也就是前后缀末尾不同的情况,那该怎么会退呢??
答案就是如果ne[j]记录了j之前的子字符串的相同前后缀的长度,如果s[i]!=s[j+1],则要查找下标j+1的前一元素在ne数组中的值。代码如下:
while (j && p[i] != p[j + 1])//前后缀不相同
{
j = ne[j];//向后退
}
三、处理前后缀相同的情况;
如果s[i]==s[j+1],那么就同时向后移动i和j,说明找到了相同的前后缀,同时还要将j(前缀的长度)赋值给ne[i],因为ne[i]要记录相同的前后缀的长度。代码如下
if (p[i] == p[j + 1]) j++;//找到相同的前后缀
ne[i] = j整体构建ne[N]数组代码如下:
// 构建ne数组,表示匹配不成功时可以直接向后跳多少位
for (int i = 2, j = 0; i <= n; i ++ )
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++ ;
// 不匹配了,j此时是最大的前缀后缀相等的长度,将其赋值给ne[i],最大长度就是跳转的位置
ne[i] = j;
}
5、例题——KMP字符串来喽
题目描述:
给定一个字符串 S,以及一个模式串 P,所有字符串中只包含大小写英文字母以及阿拉伯数字。模式串 P 在字符串 S 中多次作为子串出现;
求出模式串 P 在字符串 S 中所有出现的位置的起始下标。
输入格式
第一行输入整数 N,表示字符串 P 的长度。
第二行输入字符串P。
第三行输入整数 M,表示字符串 S 的长度。
第四行输入字符串 S。
输出格式
共一行,输出所有出现位置的起始下标(下标从 0 开始计数),整数之间用空格隔开。
数据范围
1<=N<=1e5
1<=M<=1e6
输入样例:
3 aba 5 ababa输出样例:
0 2
详解代码模板:
#include
using namespace std;
const int N = 100010, M = 1000010;
char q[N], s[M];//q为模式串(长串),s为模板串(短串)
int ne[N], n, m;
int main()
{
cin >> n >> q + 1 >> m >> s + 1;//q,s的下标均从1开始
for (int i = 2, j = 0; i <= n; i++)//j表示匹配成功的长度,i表示q数组中的下标
//因为q数组的下标是从1开始的,只有1个时,ne[1]一定为0,所以i从2开始
{
while (j && q[i] != q[j + 1]) j = ne[j]; //如果不行可以换到next数组
if (q[i] == q[j + 1]) j++;//成功了就加1
ne[i] = j;//对应其下标
}
//j表示匹配成功的长度,因为刚开始还未开始匹配,所以长度为0
for (int i = 1, j = 0; i <= m; i++)
{
while (j && s[i] != q[j + 1]) j = ne[j];
//如果匹配不成功,则换到j对应的next数组中的值
if (s[i] == q[j + 1]) j++;
if (j == n)//说明已经完全匹配上去了
{
printf("%d ", i - j);
//因为题目中的下标从0开始,所以i-j不用+1;
j = ne[j];
//为了观察其后续是否还能跟S数组后面的数配对成功
}
}
return 0;
}
简介模板代码:
#include
using namespace std;
const int N = 100010, M = 1000010;
char q[N], s[M];
int ne[N], n, m;
int main()
{
cin >> n >> q + 1 >> m >> s + 1;
for (int i = 2, j = 0; i <= n; i++)
{
while (j && q[i] != q[j + 1]) j = ne[j];
if (q[i] == q[j + 1]) j++;
ne[i] = j;
}
for (int i = 1, j = 0; i <= m; i++)
{
while (j && s[i] != q[j + 1]) j = ne[j];
if (s[i] == q[j + 1]) j++;
if (j == n)
{
printf("%d ", i - j);
j = ne[j];
//为了观察其后续是否还能跟S数组后面的数配对成功
}
}
return 0;
}