MIT6.5830 实验1
GoDB 介绍
实验中实现的数据库被称为GoDB,根据 readMe1 中的内容可知,GoDB 含有:
-
Structures that represent fields, tuples, and tuple schemas;
-
Methods that apply predicates and conditions to tuples;
-
One or more access methods (e.g., heap files) that store relations on disk and provide a way to iterate through tuples of those relations;
-
A collection of operator classes (e.g., select, join, insert, delete, etc.) that process tuples;
-
A buffer pool that caches active tuples and pages in memory and handles concurrency control and transactions (neither of which you need to worry about for this lab); and,
-
A catalog that stores information about available tables and their schemas.
不具有的数据库特性:
-
Views 视图
-
索引
-
查询优化
-
int和定长string之外的数据类型
实现路径: 从下往上,先存储层,再server层。
每个需要实现的函数开头都有 // TODO: some code goes here 提示。并且几乎每个函数都有对应的单测,直接执行对应的 _test.go 文件中的对应单测函数即可。
存储架构
HeapFile:物理上对应一个操作系统的文件,即实验中的 .dat 文件。 逻辑上对应一张表。
HeapPage: 物理概念。内存和磁盘存储的最小单位,固定为 4096B 大小。承上启下的作用,逻辑代码读取内存存储使用 Page ,内存中的数据想写入到磁盘中,也是利用 Page。 和 HeapFile 是一对多。
Tuple: 逻辑上,理解为数据表中的一行。 物理存储上,和 Page 是一对多的关系,Tuple 中包含自己属于那个Page的哪个 Slot 槽位置。
Buffer Pool : 内存中的页面缓存。File和Page虽然是一对多关系,但 File 不能直接从磁盘中读取Page, 需要借助 Buffer Pool 去读取,如果缓存中有直接返回,如果没有,由 Buffer Pool 去磁盘中读取对应的页面。

Exercise1 Tuple
readMe 中提到,Godb中的元组结构用于存储数据库元组的内存值。它们由实现DBVALUE接口的字段组成。不同的数据类型(例如,Intfield,StringField)实现了DBVALUE。元组对象是通过下一节中所述的基础访问方法(例如堆文件或b-trees)创建的。元组还具有一个类型(或架构),称为元组描述符,由tupledesc struct表示,该结构由fieldType对象的集合组成,每个元组中的每个字段都有一个,每个字段描述了相应场的类型。
翻译过来就是数据表中的一行,在内存中的数据结构,很容易理解,肯定有列信息。例如列名 age, 列数据类型, int64。 以及对应的数据值 24 [岁]
type Tuple struct {
Desc TupleDesc // desc 是对 fields 每个元素的描述,例如数据的列名和数据的类型
Fields []DBValue // 仅仅是数据的值,应该和Desc的Fields数组,一一对应。
Rid recordID // 动态的,记录此时在哪个Page,以及Page中的位置[称为slot]
}
type recordID interface {
}
// RecordId 实现 used to track the page and position this page was read from
type RecordId struct {
PageNo int // 动态的,表示当前所在的页号
SlotNo int32 // 动态的,表示当前所在的槽号
}equals tupleDesc
顾名思义没什么难点,直接逐个字段对比即可

copy
注意 golang 中的直接复制是浅复制,对象中有嵌套数组、map、指针等类型时,需要手动处理。例如这里有 FieldType 数组,那么则新建长度相等的 FieldType 数组,调用 copy 数组拷贝。

merge
拼装两个对象,返回一个新的对象,和 copy 函数的注意点一样。

equals Tuple
两个 tuple 做比较,逐字段对比,其中的 desc 对比可以用之前实现过的 equals 方法。
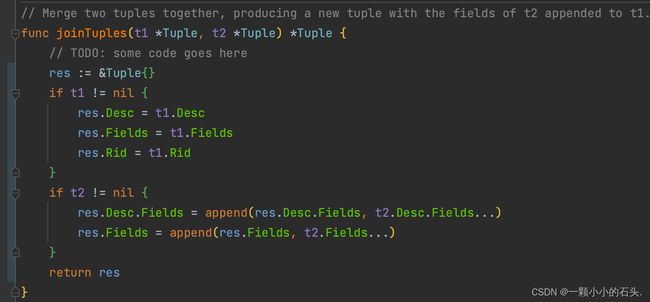
joinTuples
和 tupleDesc 的 merge 函数类似,根据两个 Tuple , 新生成合并的 Tuple,要注意数组不能直接赋值,要逐个拷贝
writeTo
序列化函数是Exercise 1的难点,需要把一个 Tuple 对象给变成字节数组,存储到入参 buffer 中。最简单的想法是直接调用 json.Marshal 变成字节数组,然后放到 buffer 中。这么做也可以通过对应的测试函数,但当做到后面几个 Exercise 就发现不对劲了。
在前面GoDB介绍中提到,本数据库中的数据类型只有 int64 和定长string,对于 int64 就是 8Byte , 而定长 string 在实验中指定了长度是 StringLength = 32 ,仅考虑普通的 aciss 码字符,就对应 32Byte。因为数据长度固定,所以给一行数据的TupleDesc,通过里面的列信息,即可确定一行数据的储存字节数,是固定的。那么一个 4096Byte 大小的 Page 所能存储的行数也就是固定的,后面的很多逻辑依赖于此。例如知道一行数据在Page的slot槽编号,就可以知道具体是在4096Byte 中的哪个位置。
综上,这里必须严格按照函数注释中的要求去自定义逐个字段写入,而不能用其他序列化方式。注意:
-
只需要存储行中每一列的值,不需要存储列信息和数据类型。
-
对于 String 类型,定长为 StringLength = 32 ,长了截断,少了补齐。实验保证不会大于32。
-
注释中指定了让以小端序进行存储。

readTupleFrom
是 writeTo的逆函数,从 buffer 中读取字节出来序列化成 tuple 对象。
因为写入的时候仅写了列值,那么读取的时候也只需要构建列值。列信息在入参 desc 中给到了。
注意:写入的时候对于String类型如果长度不够那么进行了padding,所以读取的时候需要截断一下。

project
"Project" 在数据库领域的意思是:"投影",即根据某个规则把一行数据的部分列挑出来。
在这里指的是给定列信息数组,把 Tuple 中匹配上的那些列挑出来形成一个新的 tuple, 具体的匹配规则可以用提供好的 findFieldInTd 函数。

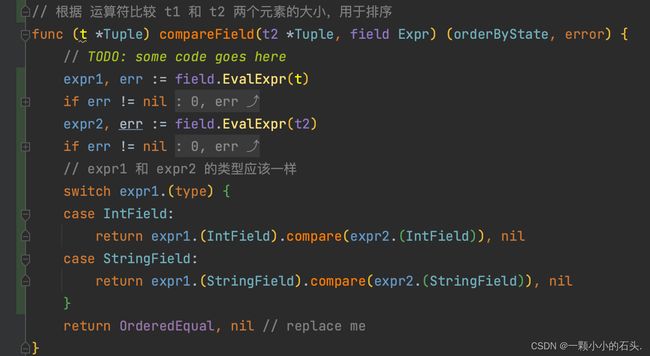
compareField
根据 field 指定的列,比较 t1 和 t2 两个 Tuple 的大小,用于排序
想要比较两个列的大小,首先要从行Tuple中获取到这两个列。观察 EvalExpr函数,正好用的就是刚才的 project 投影。对于整数可以直接比较大小,但对于字符串,需要注意一下比较规则。
 小结
小结
exercise1 的难度不大,主要依赖Go语言的基础知识,每个函数结合对应的单测用例,很容易就能写出来。但需要理解每个函数的作用,否则后面的实现中涉及到行操作的时候想不起来 Tuple 已实现的功能。
Heap File
后面 2,3,4 三个实验部分是相互依赖的,没法单独实现。需要深刻理解存储架构图中的几个数据结构。先从实现稍微简单一些的 heap file 开始。
HeapFile:物理上对应一个操作系统的文件,即实验中的 .dat 文件。 逻辑上对应一张表。结构体定义如下:
type HeapFile struct {
// TODO: some code goes here
// HeapFile should include the fields below; you may want to add
// additional fields
// 表的描述
td *TupleDesc
// 表的文件名
fileName string
// 文件句柄
fileFd *os.File
// 表的缓存池和锁
bufPool *BufferPool
sync.Mutex
}NewHeapFile
初始化函数,需要注意的是这里的openFile参数是创建和读写,不能有 O_TRUNC,否则每次打开文件会先清空已有的内容,导致运行整体的 test.go 失败。

NumPages
获取一个文件有多少页,根据 readMe 里面的指示,直接用文件大小除以页面大小 4096

readPage
读取一页,readMe 里面提到,这里就是从原始文件本身中读取,而不是从 bufferPool 里面读取。因为页的大小是否定的,所以在文件中的偏移量是 pageNo*PageSize
读取出来的是4096个字节,但函数要求返回的是Page对象,所以需要初始化并反序列化出Page对象,在后面的内容中进行实现。

insertTuple
文件中插入一个元祖,即表中插入一行,首先要找到对应的page进行插入,如果已有的所有page都没有位置可插入时,新生成页。
-
找Page时一定要倒着找,否则如果表的数据量比较大,前面的页都是满的,导致循环次数越来越多。更高级的实现应该有一个地方专门记录哪些页面有空闲空间[在 blotDB叫freePageList]。
-
首先要找到对应的page,根据注释提示从 bufferPool 里面找page,具体的实现在后面的内容。
-
怎么知道page有没有空位置,那么就需要用到 page 中的属性,totalSlots 是可容纳的行数[tuple数],usedNumSlots 是已使用的行数。前面提到,对于一个确定的表,因为字段都是定长的,所以每行的数据大小是固定的,每页能容纳的行数也是固定的,所以totalSlots很容易算出来。有空位置之后调用 page 的 插入元祖函数,具体的实现在后面。
-
已有的所有page都没有位置可插入时,新生成页。页号则延续之前的最后一个,保持连续性。另外根据注释提示,新生成的页需要刷入到磁盘中。思考一下为什么从 bufferPool 里面读取的页面修改后不需要刷盘,而生成的页面需要刷盘?这涉及到数据库的刷盘策略。
-
图片中的for循环应该是 i>=0

deleteTuple
删除一行数据,这里需要提前知道这行数据所在的pageNo页号和slotNo槽号,这涉及到上一节Tuple结构体中 RecordId 的实现,其中保存的就是当前所在的pageNo页号和slotNo槽号。
知道行所在的页号,则可使用 Buffer Pool 读取页,然后使用 page 的 deleteTuple函数进行删除。

flushPage
刷盘函数,把一个Page对象刷到磁盘中。 Page对象是内存中的数据结构,和磁盘进行交互需要是二进制字节,所以先使用的 page 的 toBuffer 函数进行序列化,然后直接根据 页号 * 页大小 写入文件偏移位置。

Iterator
返回一个迭代器,用于外界从文件从逐行读取数据。在实现上,先迭代页,再迭代槽。
作为一个go程序员,做业务开发时几乎没有用过闭包,很难理解在返回的函数中引用函数外变量的用法。尤其是这里涉及到迭代器的嵌套,因为 Page 已经实现过了自己的迭代器 tupleIter 函数,如何在这里正确的引用,需要对闭包有一定理解。

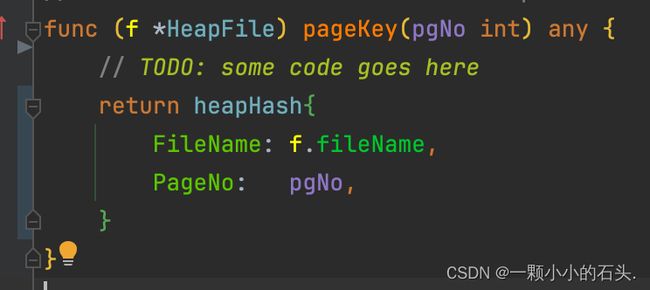
pageKey
直接使用提供好的heapHash结构体即可,函数主要用于唯一确定一个page
Heap Page
前面反复提到, Page 是磁盘和内存的最小存储单位,但在逻辑上,Page是一个带有丰富属性的结构体,保存了页的信息和内部行信息,只有在需要存储到磁盘中的时候,才序列化成 4096Byte 大小的字节数组。
// 一页的大小是固定的 PageSize 4096,还有一种页是 sortPage
type heapPage struct {
// TODO: some code goes here
// 页的头,共8字节,一个页里面只会存一种表
totalSlots int32 // 总的 slots 数目,也就是最大能存放的行数
usedNumSlots int32 // 已使用的 slots 数目,已存放的行数
tupleList []*Tuple // 存储的行
tupleDesc *TupleDesc // 列信息
// 页的文件
file *HeapFile
// 页的编号,从0开始,用于file文件中定位位置
pageNo int
// 是否是脏页
whetherDirty bool
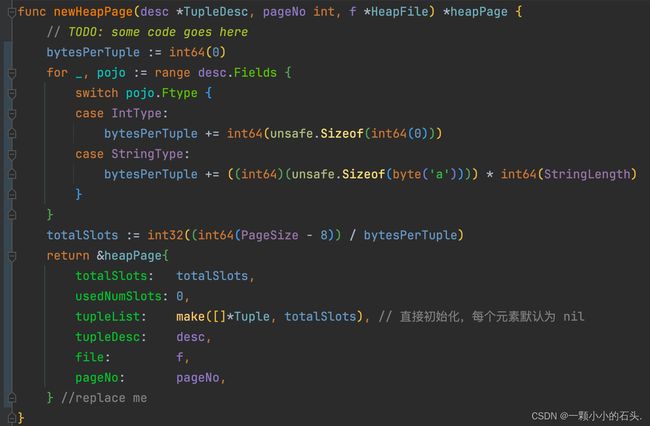
}newHeapPage
和 Heap File 一样,首先是初始化函数。需要注意:
-
入参给定了列信息TupleDesc,前面提到已知列信息的情况下,就知道一行数据的大小,进一步可算出totalSlots, 文件开头的注释中告知了计算数据类型存储大小的方法 unsafe.Sizeof,虽然 int64 确定是 8字节,但按照注释中的写法更优雅。
-
tupleList 行数组需要进行初始化,并填充 totalSlots 个 nil 占位,用于之后 insert 时找 nil 位置进行插入。
getNumSlots
获取槽的数量,只有研究明白调用方是怎么使用的,才知道要返回的是总槽数,还是已用槽数,还是剩余槽数。

insertTuple
在页中插入一行[Tuple],找到一个空闲的 slot,即槽上是 nil,插入完设置脏页标识。注意
-
需要正确设置元祖的 recordID 属性,指定所在页号和槽号,用于之后其他函数定位这行数据的位置。
-
已用槽数需要自增1

deleteTuple
从页中删除一行,对应插入实现很简单,首先从 recordID 中取出行所在的槽号,循环 tupleList 进行查找删除。

toBuffer
将 Page 序列化成 4096 大小的字节数组,用于存储到文件中。这里需要注意:
-
仅序列化页头字段和tupleList元祖列表,tupleList 中的 nil 值不进行序列化
-
如果当前页不够 4096Byte , 最后需要填充一下

initFromBuffer
从Buffer中反序列化页,是 toBuffer 的逆实现。所以同样需要注意两点:
-
由 usedNumSlots 字段确定有多少行会被反序列化出来。另外需要重新保存 recordId 属性。
-
Tuple 的 readTupleFrom 函数已经考虑到了字节填充,无需额外处理。

tupleIter
返回一个迭代槽Tuple的迭代器,比较简单的闭包实现。需要注意 recordId 字段的填充。
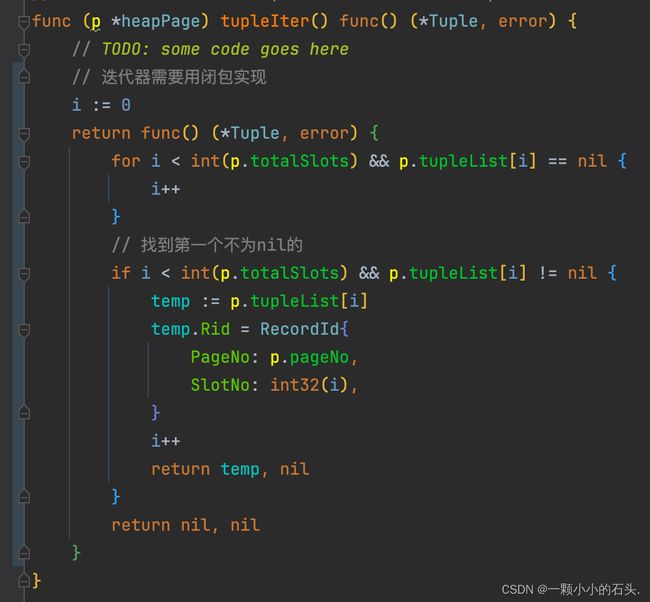
其他
剩余的几个小函数中, getFile 函数的实现需要考虑到接口特性,直接返回 p.file 会类型错误。

BufferPool
缓冲池的实现先以简单的方式满足实验一的要求,在之后的实验中进一步完善。
type BufferPool struct {
// TODO: some code goes here
pageNumber int // 有多少页 page, 是 map的逻辑容量
heapPageMap map[heapHash]*Page // 缓存的 page
currentTid TransactionID // 当前所占用的事务id
mu sync.Mutex // 加锁
}FlushAllPages
将池中所有页刷入磁盘中,直接循环调用file的刷盘函数即可。

CommitTransaction
事务提交,虽然没有实现到事务的部分,但本实验的测试函数中已经涉及到。根据注释中的提示,仅对池中的脏页进行刷盘。

GetPage
BufferPool最核心的函数,给上层提供一个获取页的方法,如果池中没有此页,则去磁盘文件中进行读取,读完之后放到池中。
如果池中的容量已满,需要进行evict驱逐。目前先不用管各种高深的LRU、LFU等页面淘汰算法,先直接用随机淘汰

实验总结和思考
完成以上代码后,GoDB的存储层实现已经结束,运行各个文件对应的 test 文件应该是全部通过的。总体难度不大,代码比较简单,难的是实验没有提前先讲清楚 Tuple、Page、File、BufferPool 之间的关系,即存储的架构。实验不足的思考如下:
无聚簇索引
普通的关系型数据库,例如MySQL的InnoDB存储引擎,默认是聚簇索引方式进行数据的排列。而本实验没有聚簇索引的概念,导致行数据是随机存储的,没有按照某个键进行顺序存储,也不需要进行排序。极大的简化了Tuple在页面中的增删查改操作难度。
数据定长
实验仅支持整数和字符串,且是定长32的字符串。导致每一行数据的存储大小都相等,体现到代码实现中,可以根据槽编号直接定位一行数据在页4096Byte中的具体位置,极大的简化了数据寻址的难度。而不是像MySQL varchar(64) 那样有变长字段,存储大小是不固定的,每页需要有页头来存储每一行数据的偏移量和大小。
InnoDB Buffer Pool
Buffer Pool 是数据库存储层的精髓所在,上层逻辑对底层文件存储的查询必须经过 buffer pool 这一层缓存,因为内存随机读写速度和磁盘随机读写速度至少快1000倍以上。本次实验仅仅用map实现了一个基本的缓存,但缺少事务的支持,也没有考虑并发的场景,将在实验3处理这些问题。
另外一般的业务层的缓存,例如 redis, localCache 等都会在数据修改时写底库。而MySQL 库 InnoDB 存储引擎的buffer pool的作用不仅仅能加速读取速度,而且在插入和删除后,不必直接去底层刷盘,因此极大地提高性能。
所以线上对 buffer pool 缓存命中率要求一般为99%以上,一般设置为可用物理内存的60%~80%。所以任何情况下的全表扫描都会载入大量页面,导致命中率大幅下降【例如后面讲到的join操作】