稀疏场景高性能训练方案演变|京东广告算法架构体系最佳实践
近年来,推荐场域为提升模型的表达能力和计算能力,模型规模和计算复杂度大幅增加,同时,高规格硬件资源为模型迭代、算法优化带来了更大的机遇和挑战。为了应对模型规模和算力升级带来的存储、IO和计算挑战,京东零售广告技术团队基于新型硬件,充分利用硬件优势,提出新一代多机多卡全GPU计算全同步训练架构,参数通信基于GPU-RDMA硬件带来的高速带宽优势,采用集合通信方案,结合五级流水线并行训练模式,极大的提升了训练过程中数据通信交换效率。同时研发CPU-DRAM GPU-HBM二级参数服务器缓存训练机制,解决稀疏参数更新时带来的梯度过期问题,为稀疏大模型的落地应用提供了坚实的技术支撑。
一、前言
京东广告训练框架随着广告算法业务发展的特点也在快速迭代升级,回顾近几年大致经历了两次大版本的方案架构演变。第一阶段,随着2016年Tensorflow训练框架的开源,业界开始基于Tensorflow开源框架训练更复杂的模型。模型对特征规模和参数规模需求不断提升,大规模稀疏模型具有更强的表征能力,逐渐成为算法的主流趋势。但是Tensorflow在大规模稀疏参数的训练机制不完备,因此第一次最大能力升级是通过自研高性能参数服务器,支持超大规模TB级稀疏参数模型的建模能力以及基于此架构支持在线学习的能力。 第二阶段,随着用户行为序列建模、多模态建模、多目标等算法技术的发展,模型变得既宽且深,计算算力、通信性能和存储容量逐渐成为瓶颈。基于之前的方案虽然有可能通过扩大训练集群规模满足训练需求,但是在节点拓扑的复杂度、参数通信性能、集群稳定性和模型效果等多个方面都存在较大的问题。随着更先进的NVIDIA A100 等训练GPU硬件资源的出现,基于高性能GPU算力构建的新一代软硬深度结合的训练方案成为第二次架构演变的主要方向。接下来,本文将针对大规模稀疏场景,结合模型的发展趋势,详细介绍各阶段的训练方案。
二、持续演进的大规模稀疏场景训练方案
2.1 基于分布式参数服务器的TB级大规模稀疏场景训练方案
2.1.1 Tensorflow在大规模稀疏场景的局限性
随着业务规模和算法能力不断发展,训练样本规模扩展到百亿级,训练参数规模达到千亿级,为了提高模型训练效率和规模,业界通常采用数据并行和模型并行方式来进行分布式训练。由于Tensorflow采用静态Embedding机制来存储稀疏参数,限制了参数规模,对训练的效率和效果并不友好:
◦静态存储局限性:词表空间过小,hash冲突加剧;词表空间过大,浪费内存资源,难以支持大规模参数存储。
◦在线学习不支持:针对在线学习场景,无法淘汰不重要的特征,也无法单独释放该特征Embedding的内存,参数更新时效性成为瓶颈。
2.1.2 自研高性能参数服务器
为了解决静态Embedding的问题,我们通过自研动态Embedding的高性能参数服务器,将不同的Embedding映射到不同的内存空间,优化存储空间,支持大规模稀疏参数的高效存储,并考虑高并发读写场景,针对稀疏参数设计高性能二级检索方案,优化数据结构,减少并发读写冲突。

图1 动态Embedding参数服务器&训练架构
▪参数二级检索
▪一级参数分片,支撑分布式千亿甚至更大规模参数存储。
▪二级参数分桶,并行无锁读写,支撑数据并行模式下的高并发读写场景。
▪ 稀疏参数存储&训练
▪基于Map实现稀疏参数存储,支撑动态Embedding、增量导出等复杂功能。
▪稀疏参数延迟初始化,支撑特征准入&淘汰等复杂策略。
▪参数&优化器状态同构存储,支撑复杂优化算法(带一二阶动量)的高性能实现。
▪离&在线一体化设计
▪通用化服务接口&模型参数格式,一套核心框架服务离&在线场景,支持在线学习。
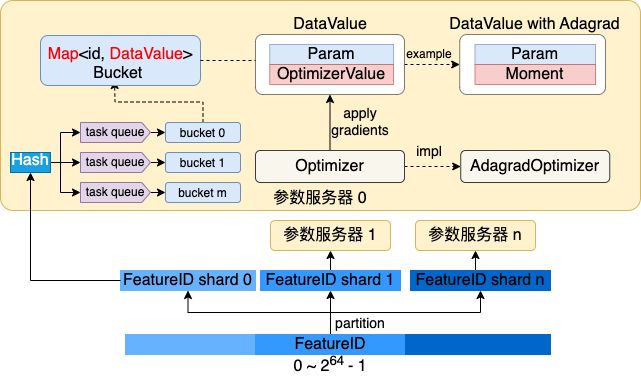
图2 动态Embedding高性能参数服务器实现设计
在2020年底广告实现了高性能参数服务器架构,2021年初在搜索广告场景构建了离在线一体实时在线学习闭环系统。性能方面,支持千亿参数规模,提升算法建模空间,对比TF原生PS训练性能提升25%,对比阿里DeepRec和腾讯TFRA,内存节省约15%至20%。效果方面,在搜索精排模型场景落地京东零售首个OnlineLearning架构,模型时效性从天级提高到分钟级。
2.2 基于高性能算力的全GPU训练方案
2.2.1 分布式参数服务器方案的局限性
为了精细刻画用户的行为,捕捉用户的兴趣变化,推荐系统模型进入到更深层次的序列化、多模态建模。推荐领域模型建模逐渐发展到以一定规模Transformer结构结合大规模Embedding为主,抽象结构则是中等规模稠密参数 + 大规模稀疏参数,对模型训练架构的存储、计算、IO等方面都提出了更高的要求。虽然可以通过更大的参数服务器规模 + 更大的数据并行规模来提升整体训练集群吞吐,但该方案存在一定局限性:
▪参数服务器规模仅能满足大规模Embedding稀疏模型,但是针对Transformer等稠密模型无法分片,会导致模型训练性能&效果显著下降;
▪训练节点规模急剧扩大到上百,导致通信拓扑复杂,训练稳定性下降,梯度过期问题加剧;
▪大量参数IO使得参数服务器与训练节点之间的参数传输成为通信性能瓶颈。
图3 分布式参数服务器存在的问题
随着Nvidia推出新一代NVIDIA A100 80GB SXM GPU服务器,伴随NvLink、IB网络等GPU-RDMA硬件加持,相较P40,在存储容量(显存640GB、内存1~2TB、SSD10+TB级别)、通信性能 (由PCIe总线提供的32GB/s升级到NVLink卡间互联的600GB/s的高速带宽,多机之间通过IB网络采用RDMA进行通信,通信带宽相比于TCP而言,从1G/s 提升到50G/s)以及计算能力(从12TFLOPS升级到156 TFLOPS) 都有质的突破。更高算力的硬件资源为模型迭代和优化带来了更大的机遇,同时也给训练架构设计带来了更大的挑战,基于高性能GPU算力构建的新一代软硬深度结合的训练方案成为第二次架构演变的主要方向。
2.2.2 基于高性能算力的全GPU训练方案
如何把分布式训练中上百个节点的复杂拓扑结构,融入到高算力GPU的一体化方案中,实现千亿甚至更大规模参数在GPU上的高性能计算,在业界是一个比较有挑战的问题,在新一代训练架构的落地实践中我们主要面临三个核心挑战:
▪存储挑战:不同于传统NLP、CV几十G模型规模,推荐领域大规模稀疏模型通常在几百G以上,远超单显卡80G显存上限,需要设计一种新的参数存储和计算策略;
▪IO挑战:大规模稀疏参数、稠密参数的拉取与计算为训练集群带来极高的IO需求,需要设计一种新的交互式策略,实现卡与卡间,机与机间参数高性能通信;
▪算力挑战:CPU的算力性能限制了推荐模型的规模与计算复杂度,需要设计一种新的训练并行策略,实现CPU与GPU的算力均衡。
结合对业界方案的调研以及广告推荐算法的业务场景特点,我们设计了基于高性能算力的全GPU训练方案:基于GPU-HBM+CPU-DRAM两级交叉缓存来实现全参数的GPU存储计算,结合GPU-RDMA集合通信技术突破大规模参数训练的通信瓶颈,同时构建CPU&GPU异构的分布式流水线并行训练框架,实现了CPU和GPU计算算力的最大化协同。

图4 基于高性能算力的全GPU训练方案
基于GPU-HBM和CPU-DRAM的两级交叉参数服务器,实现稀疏参数的跨域存储。GPU作为一级缓存有效利用GPU高带宽、高算力的优势,极大提升训练吞吐,CPU作为二级缓存有效利用CPU内存的高容量、易扩展的优势,提升参数的规模上限。该方案可以进一步扩展SSD固态硬盘,形成HBM-DRAM-SSD的三级参数服务器方案,支撑更大规模万亿参数级别的高性能训练。

图5 GPU-HBM+CPU-DRAM 两级交叉存储方案
基于GPU-RDMA集合通信的全参数同步训练范式。在参数通信方式上:参数的拉取方式相比于传统的分布式参数服务器架构,由CPU-to-CPU的TCP通信升级为GPU-to-GPU的RDMA通信,带宽吞吐量实现了数量级的显著提升(1GB/s->600GB/s)。在参数更新方面:通过AllReduce、AllToAll等集合通信技术,实现全参数同步训练范式,保证模型效果。基于上述能力,框架一体化设计实现了参数交互&参数训练的最佳配速。
CPU&GPU异构的分布式流水线并行训练框架,将模型按CPU密集型子图(重逻辑)与GPU密集型子图(重计算)进行分图,部署于CPU&GPU异构集群进行分布式分图训练,在发挥各自硬件算力优势的同时,解决CPU与GPU算力不匹配的问题,达到算力均衡。同时构建多级流水线并行训练模式,使训练集群整体IO、计算吞吐最大化
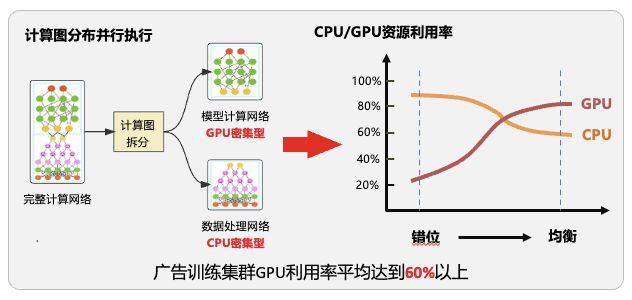
图6 CPU&GPU异构的分布式流水线并行训练框架
多机多卡算力水平扩展:基于上述核心能力,借助 IB 网络,进一步实现单机多卡到多机多卡的算力水平扩展,训练加速比达到1.85+,做到业界领先。
三、总结与展望
综上,新一代基于高性能算力的全GPU训练方案,在广告多个业务线进行了落地实践:推荐首页CTR模型规模从30G扩展到130G,资源0增长的情况下,训练性能提升55%,并通过技术迁移仅一个月时间将技术方案复用至商详、中长尾信息流核心位置,实现模型规模百G的突破,算法迭代效率提升400%,助力推荐、搜索等核心业务线取得显著的效果收益。
算法在不断的迭代发展,硬件也在不断的推陈出新,广告训练框架也在持续的演变,我们正在规划设计下一代算法架构体系,其最显著的特点就是算法、算力、架构的深度融合以及在线、离线一体化的设计方案。算法架构体系建设是一个充满挑战的新的技术领域,需要不断探索、学习和创新。我们欢迎对此感兴趣的同事联系我们一起加入讨论,共同探索解决方案,汇集智慧,共同成长。让我们携手应对挑战,共同开拓这一前沿领域,为技术创新和团队发展贡献我们的热情与智慧。
作者:京东零售-广告研发部-算法应用组
来源:京东零售技术 转载请注明来源