Spark SQL的高级用法
一. 快速生成多行的序列
需求:请生成一列数据, 内容为 1 , 2 , 3 , 4 ,5
-- 快速生成多行的序列
-- 方式一
select explode(split("1,2,3,4,5",","));
--方式二
/*
序列函数sequence(start,stop,step):生成指定返回的列表数据
[start,stop]必须传入,step步长可传可不传,默认为1,也可以传入负数,传入负数的时候,大数要在前,小数
*/
select explode(sequence(1,5));
select explode(sequence(1,5,1));
select explode(sequence(1,5,2));
select explode(sequence(5,1,-1));
select explode(sequence(5,1,-2));
二. 快速生成表数据
需求: 生成一个两行两列的数据, 第一行放置 男 M 第二行放置 女 F
-- 快速生成表数据
/*
stack(n,expr1, ..., exprk),n代表要分为n行,expr1, ..., exprk是放入每一行每一列的元素
如果不传入列名,则默认使用col0,col1等作为列名
*/
select stack(2,"男","M","女","F");
select stack(2,"男","M","女","F") as (n,v);
三. 如何将一个SQL的结果给到另外一个SQL进行使用
3.1 视图
临时视图关键字:temporary
- 分为永久视图和临时视图
- 相同点:都不会真正的存储数据。主要是用来简化SQL语句
- 不同点:永久试图会创建元数据,在多个会话(Session)中都有效;临时视图只在当前会话有效
3.2 视图和表的区别
视图不会真正的存储数据,而表会真正的存储数据。
但是视图和表在使用的时候区别不大
-- 如何将一个SQL的结果给到另外一个SQL进行使用
-- 方式一:子查询
select
*
from (select stack(2,"男","M","女","F"));
-- 方式二:子查询
with tmp as (
select stack(2,"男","M","女","F")
) select * from tmp;
-- 方式三:永久视图
create view forever_view as
select stack(2,"男","M","女","F");
select * from forever_view;
-- 方式四:临时视图
create temporary view tmp_view as
select stack(2,"男","M","女","F");
select * from tmp_view;
-- 方式五:创建表
create table tb as
select stack(2,"男","M","女","F");
select * from tb;
-- 缓存表:类似Spark Core中的缓存,提高数据分析效率
cache table cache_tb as
select stack(2,"男","M","女","F");
-- 查询缓存表
select * from cache_tb;
-- 清理指定缓存
uncache table cache_tb;
select * from cache_tb;
-- 清空所有的缓存
clear cache;
四. 窗口函数
格式:
分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx])
分析函数的分类:
1- 第一类: 排序函数。row_number() rank() dense_rank() ntile()
1、都是用来编号的
2、如果出现了重复(针对order by中的字段内容)数据
2.1- row_number:不管有没有重复,从1开始依次递增进行编号
2.2- rank():如果数据重复,编号相同,并且会占用后续的编号
2.3- dense_rank():如果数据重复,编号相同,但是不会占用后续的编号
2.4- ntile(n):将数据分为n个桶,不传入参数默认为1
2- 第二类: 聚合函数。sum() avg() count() max() min()…
1、可以通过窗口函数实现级联求各种值的操作。当后续遇到需要在计算的时候,将当前行或者之前之后的数据关联起来计算的情况,可以使用窗口函数。
2、如果没有排序字段,也就是没有order by语句,直接将窗口打开到最大,整个窗口内的数据全部被计算,不管执行到哪一行,都是针对整个窗口内的数据进行计算。
3、如果有排序字段,并且还存在重复数据的情况,默认会将重复范围内的数据放到一个窗口中计算
4、可以通过rows between xxx and xxx来限定窗口的统计数据范围
4.1- unbounded preceding: 从窗口的最开始
4.2- N preceding: 当前行的前N行,例如1 preceding、2 preceding
4.3- current row: 当前行
4.4- unbounded following: 到窗口的最末尾
4.5- N following: 当前行的后N行,例如1 following、2 following
3- 第三类: 取值函数。lead() lag() first_value() last_value()
-- 准备数据
create temporary view t1 (cookie,datestr,pv) as
values
('cookie1','2018-04-10',1),
('cookie1','2018-04-11',5),
('cookie1','2018-04-12',7),
('cookie1','2018-04-13',3),
('cookie1','2018-04-14',2),
('cookie1','2018-04-15',4),
('cookie1','2018-04-16',4),
('cookie2','2018-04-10',2),
('cookie2','2018-04-11',3),
('cookie2','2018-04-12',5),
('cookie2','2018-04-13',6),
('cookie2','2018-04-14',3),
('cookie2','2018-04-15',9),
('cookie2','2018-04-16',7);
select * from t1;
-- 1- 第一类: 排序函数。row_number() rank() dense_rank() ntile()
select
cookie,pv,
row_number() over (partition by cookie order by pv desc) as rs1,
rank() over (partition by cookie order by pv desc) as rs2,
dense_rank() over (partition by cookie order by pv desc) as rs3,
ntile() over (partition by cookie order by pv desc) as rs4
from t1;
-- 2- 第二类: 聚合函数。sum() avg() count() max() min()...
select
cookie,pv,
-- 一次性直接将窗口打开到最大
sum(pv) over(partition by cookie) as rs1,
-- 依次慢慢打开窗口,如果数据相同,直接放到同一个窗口中
sum(pv) over(partition by cookie order by pv) as rs2,
-- 依次慢慢打开窗口,限定窗口的统计范围从窗口的最开始到当前行
sum(pv) over(partition by cookie order by pv rows between unbounded preceding and current row) as rs3,
-- 以当前行为中心,往前推一行。也就是从上一行计算到当前行
sum(pv) over(partition by cookie order by pv rows between 1 preceding and current row ) as rs4,
-- 从窗口的最开始一直统计到窗口的最终结尾
sum(pv) over(partition by cookie order by pv rows between unbounded preceding and unbounded following) as rs5,
-- 从当前行统计到窗口的结尾
sum(pv) over(partition by cookie order by pv rows between current row and unbounded following) as rs6,
-- 以当前行为中心,统计上一行、当前行、下一行总共3行的数据
sum(pv) over(partition by cookie order by pv rows between 1 preceding and 1 following) as rs7,
sum(pv) over(partition by cookie order by pv rows between 2 preceding and 3 following) as rs8
from t1;
-- 3- 第三类: 取值函数。lead() lag() first_value() last_value()
select
cookie,pv,
-- 默认取下一行数据
lead(pv) over(partition by cookie order by pv) as rs1,
-- 默认取上一行数据
lag(pv) over(partition by cookie order by pv) as rs2,
-- 默认取窗口内的第一条数据
first_value(pv) over(partition by cookie order by pv) as rs3,
-- 默认取窗口内的最后一条数据
last_value(pv) over(partition by cookie order by pv) as rs4
from t1;
五. 横向迭代
/*
需求: 已知 c1列数据, 计算出 c2 和 c3列数据
c2 = c1+2
c3=c1*(c2+3)
*/
-- 数据准备
select explode(sequence(1,3));
select stack(3,1,2,3);
-- 方式一:子查询
-- 计算c2
with t1 as (
select explode(sequence(1,3)) as c1
)select c1,(c1+2) as c2 from t1;
-- 计算c3
with t1 as (
select explode(sequence(1,3)) as c1
)
select c1,c2,c1*(c2+3) as c3 from
(select c1,(c1+2) as c2 from t1);
-- 方式二:视图方式
-- 准备数据
create temporary view view_t1 as
select explode(sequence(1,3)) as c1;
select * from view_t1;
-- 计算c2并创建视图
create temporary view view_t2 as
select c1,(c1+2) as c2 from view_t1;
select * from view_t2;
-- 计算c3并创建视图
create temporary view view_t3 as
select c1,c2,c1*(c2+3) as c3 from view_t2;
select * from view_t3;
六. 纵向迭代
需求: 计算 c4:
计算逻辑: 当c2=1 , 则 c4=1 ; 否则 c4 = (上一个c4 + 当前的c3)/2
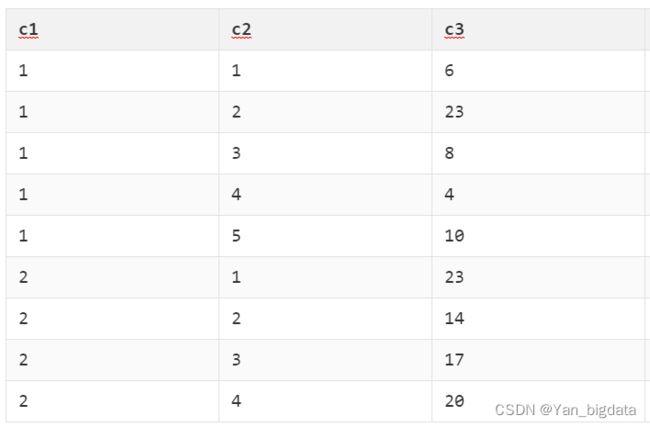
-- 数据准备
create temporary view view_data (c1,c2,c3)
as values
(1,1,6),
(1,2,23),
(1,3,8),
(1,4,4),
(1,5,10),
(2,1,23),
(2,2,14),
(2,3,17),
(2,4,20);
select * from view_data;
方式一:创建临时视图继续计算c4的值,对于练习阶段数据量小还行,即使是数量小,也有很多重复代码,所以对于以后海量数据的计算,这种方法显然是不合理的。
--方式一:
-- 步骤一:当c2=1 , 则 c4=1
create temporary view col_tmp1 as
select c1,c2,c3,if(c2=1,1,null)as c4 from view_data;
select * from col_tmp1;
-- 步骤二:否则 c4 = (上一个c4 + 当前的c3)/2
create temporary view col_tmp2 as
select
c1,c2,c3,
if(c2=1,1,((lag(c4) over (partition by c1 order by c2))+c3)/2) as c4
from col_tmp1;
select * from col_tmp2;
create temporary view col_tmp3 as
select
c1,c2,c3,
if(c2=1,1,((lag(c4) over (partition by c1 order by c2))+c3)/2) as c4
from col_tmp2;
select * from col_tmp3;
create temporary view col_tmp4 as
select
c1,c2,c3,
if(c2=1,1,((lag(c4) over (partition by c1 order by c2))+c3)/2) as c4
from col_tmp3;
select * from col_tmp4;
create temporary view col_tmp5 as
select
c1,c2,c3,
if(c2=1,1,((lag(c4) over (partition by c1 order by c2))+c3)/2) as c4
from col_tmp4;
select * from col_tmp5;
方式二:基于pandas进行自定义聚合函数(UDAF)操作
#!/usr/bin/env python
# @desc :
__coding__ = "utf-8"
__author__ = "bytedance"
import pyspark.sql.functions as F
import pandas as pd
import os
from pyspark.sql import SparkSession
from pyspark.sql.types import FloatType
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1- 创建SparkSession对象
spark = SparkSession.builder\
.config('spark.sql.shuffle.partitions',1)\
.appName('sparksql_udaf')\
.master('local[*]')\
.getOrCreate()
# 2- 数据输入
spark.sql("""
create temporary view view_data (c1,c2,c3)
as values
(1,1,6),
(1,2,23),
(1,3,8),
(1,4,4),
(1,5,10),
(2,1,23),
(2,2,14),
(2,3,17),
(2,4,20)
""")
# 3- 数据处理
# 3.1- 当c2=1 , 则 c4=1
spark.sql("""
create temporary view heng_tmp_1 as
select
c1,c2,c3,if(c2=1,1,null) as c4
from view_data
""")
spark.sql("""
select * from heng_tmp_1
""").show()
# 3.2- 否则 c4 = (上一个c4 + 当前的c3)/2
# 3.2.1- 基于Pandas实现UDAF函数,创建自定义的Python函数
# 3.2.2- 注册进SparkSQL中
# @F.pandas_udf(returnType=FloatType())
@F.pandas_udf(returnType="float")
def c4_udaf_func(c3:pd.Series, c4:pd.Series) -> float:
print(f"{c3}")
print(f"{c4}")
tmp_c4 = None
for i in range(0,len(c3)):
if i==0:
tmp_c4 = c4[i] # c4[0]
else:
tmp_c4 = (tmp_c4 + c3[i]) / 2
return tmp_c4
spark.udf.register("c4_udaf",c4_udaf_func)
spark.sql("""
select
c1,c2,c3,
c4_udaf(c3,c4) over(partition by c1 order by c2) as c4
from heng_tmp_1
""").show()
# 4- 数据输出
# 5- 释放资源
spark.stop()