【考试不慌】ISS615 Database Mgt学习笔记(3) Advanced Database Analysis- EER
Learning Objectives
after studying this chapter, you should be able to:
-
Concisely define each of the following key terms: enhanced entity-relationship (eer) model, subtype, supertype, attribute inheritance, generalization, specialization, completeness constraint, total specialization rule, partial specialization rule, disjointness constraint, disjoint rule, overlap rule, subtype discriminator, supertype/ subtype hierarchy, entity cluster, and universal data model.
-
Recognize when to use supertype/subtype relationships in data modeling.
-
Use both specialization and generalization as techniques for defining supertype/
subtype relationships.
-
Specify both completeness constraints and disjointness constraints in modeling supertype/subtype relationships.
-
Develop a supertype/subtype hierarchy for a realistic business situation.
-
Develop an entity cluster to simplify presentation of an E-R diagram.
-
Explain the major features and data modeling structures of a universal (packaged) data model.
-
Describe the special features of a data modeling project when using a packaged data model.
Enhanced entity-relationship
To cope better with these changes, researchers and consultants have continued to enhance the E-R model so that it can more accurately represent the complex data encountered in today’s business environment. The term enhanced entity-relationship (EER) model is used to identify the model that has resulted from extending the original E-R model with these new modeling constructs.
Why do we need EER
E-R, and especially EER, diagrams can become large and complex, requiring multiple pages (or very small font) for display. Some commercial databases include hundreds of entities. Many users and managers specifying requirements for or using a database do not need to see all the entities, relationships, and attributes to understand the part of the database with which they are most interested.(为了更好地应对这些变化,研究人员和顾问不断增强E-R模型,使其能够更准确地表示当今商业环境中遇到的复杂数据)
Entity clustering is a way to turn a part of an entity-relationship data model into a more macro-level view of the same data. Entity clustering is a hierarchical decomposition technique (a nesting process of breaking a system into further and further subparts), which can make E-R diagrams easier to read and databases easier to design. By grouping entities and relationships, you can lay out an E-R diagram in such a way that you give attention to the details of the model that matter most in a given data modeling task.
The EER features of supertypes/subtypes are essential to create generalizable data models; additional generalizing constructs, such as typing entities and relationships, are also employed. It has become very important for data modelers to know how to customize a data model pattern or data model for a major software package (e.g., enterprise resource planning or customer relationship management), just as it has become commonplace for information system builders to customize off-the-shelf software packages and software components.
当前挑战
One of the major challenges in data modeling is to recognize and clearly represent entities that are almost the same, that is, entity types that share common properties but also have one or more distinct properties that are of interest to the organization.
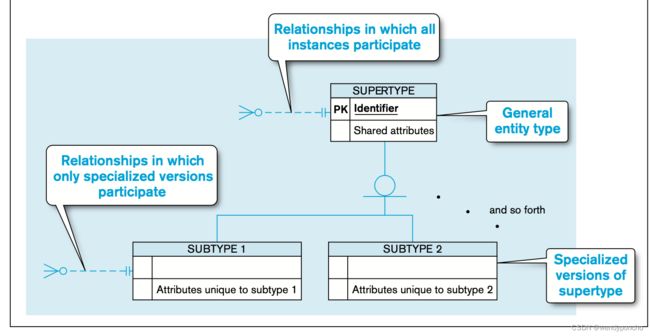
RepresentIng supertypes and subtypes
在数据库设计和数据建模中,超类型/子类型(supertype/subtype)关系是用来描述实体间的一种特殊关系,其中一个更泛化的实体(超类型)可以被分解为多个更具体的实体(子类型)。这些概念和符号的使用帮助设计者更精确地反映现实世界中的层次和分类。
基本概念和符号
-
超类型(Supertype):
- 代表一个泛化的实体,它包含共同的属性和标识符。
- 在E-R图中,超类型通过一条线连接到一个圆圈,表示它可以被细分。
-
子类型(Subtype):
- 是超类型的具体化,包含特有的属性和关系。
- 子类型通过一条线连接到上述的圆圈,每个子类型都是超类型的一个子集。
-
U形符号:
- 连接子类型到圆圈的线上可能会有一个U形符号,强调子类型是超类型的子集,并指示超类型/子类型关系的方向。
- 这个U形符号是可选的,因为超类型/子类型关系的含义和方向通常是显而易见的,在大多数例子中不包括这个符号。
-
属性(Attributes):
- 所有实体共享的属性(包括标识符)与超类型相关联。
- 特定于某个子类型的唯一属性与那个子类型相关联。
-
关系(Relationships):
- 超类型和子类型可能都会涉及到一些关系,共享的关系会与超类型关联,而特有的关系则与相应的子类型关联。
 Supertype/Subtype Relationship Example:
Supertype/Subtype Relationship Example:
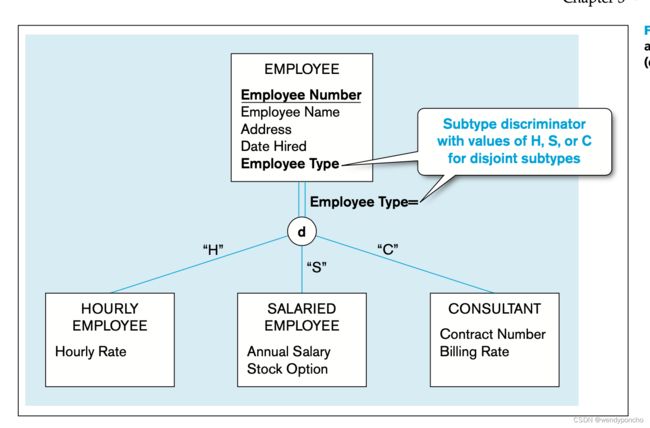
Context: An organization has three basic types of employees - hourly employees, salaried employees, and contract consultants.
Common Attributes (for all employee types):
- Employee Number
- Employee Name
- Address
- Date Hired
Unique Attributes:
- Hourly employees have a unique attribute: Hourly Rate.
- Salaried employees have unique attributes: Annual Salary, Stock Option.
- Contract consultants have unique attributes: Contract Number, Billing Rate.
Modeling Choices:
-
Single Entity Approach:
- Create one entity called EMPLOYEE with all possible attributes.
- Disadvantage: Many attributes would be irrelevant or null for certain instances, leading to a less efficient database structure and more complex program logic.
-
Separate Entities Approach:
- Create separate entities for HOURLY EMPLOYEES, SALARIED EMPLOYEES, and CONSULTANTS.
- Disadvantage: This fails to capture the commonality among the different types of employees and could lead to duplication and more complex data management.
-
Supertype/Subtype Approach:
- Create a supertype called EMPLOYEE with subtypes for each employee category.
- Advantages:
- Shared attributes are associated with the EMPLOYEE supertype.
- Unique attributes are associated with the respective subtypes only.
- This maintains data integrity, reduces redundancy, and accurately models the real-world organization of employees.
 EER Diagram Representation:
EER Diagram Representation:
In the EER diagram, you would represent this with the EMPLOYEE entity as the supertype connected to three subtypes:
-
EMPLOYEE (Supertype)
- Shared attributes: Employee Number, Employee Name, Address, Date Hired
-
HOURLY EMPLOYEE (Subtype)
- Unique attribute: Hourly Rate
-
SALARIED EMPLOYEE (Subtype)
- Unique attributes: Annual Salary, Stock Option
-
CONSULTANT (Subtype)
- Unique attributes: Contract Number, Billing Rate
In the diagram, the EMPLOYEE entity would be connected to each subtype with a line. The shared attributes would be listed within the EMPLOYEE entity, and each subtype would list its unique attributes. This structure allows for a clear representation of the relationships and attributes in the database, making it easier to understand, implement, and maintain.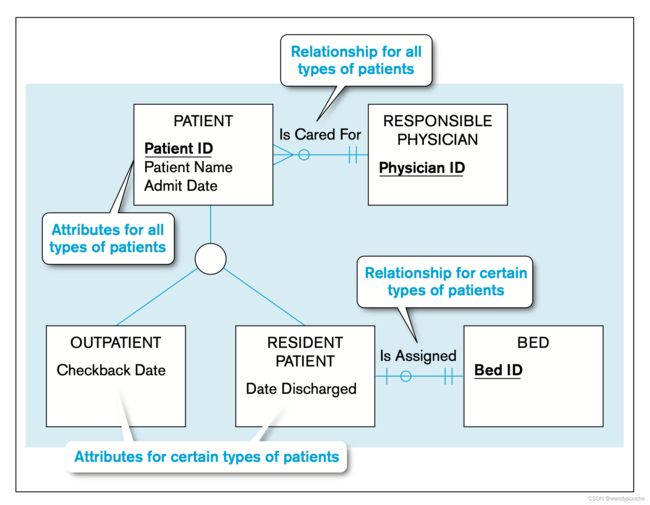
Representing specialization and generalization
泛化 Generalization
A unique aspect of human intelligence is the ability and propensity to classify objects and experiences and to generalize their properties. In data modeling, generalization is the process of defining a more general entity type from a set of more specialized entity types. Thus generalization is a bottom-up process.
泛化是一种自下而上的过程,它从一组更专门化的实体类型中定义出一个更泛化的实体类型。这是人类智能的一个独特方面,即分类事物和经验,并概括它们的属性。
举例:
考虑三种实体类型:汽车(CAR)、卡车(TRUCK)和摩托车(MOTORCYCLE)。在初步的E-R图中,它们被分别表示。但是,仔细观察会发现这三个实体类型有许多共同的属性,如车辆ID(Vehicle ID)、车辆名称(Vehicle Name,包括品牌和型号)、价格(Price)和发动机排量(Engine Displacement)。这个事实提示我们,这三种类型实际上可以看作是更泛化实体类型的不同版本。
在泛化后的模型中,我们将创建一个名为VEHICLE的更泛化实体类型,并确定它与子类型的关系。每个子类型,如CAR、TRUCK和MOTORCYCLE,会继承VEHICLE的共同属性,同时保留各自特有的属性,比如CAR可能有乘客数量(No Of Passengers),而TRUCK有载重(Capacity)和驾驶室类型(Cab Type)。
在数据建模中,特化(specialization)和泛化(generalization)是两种用于开发超类型/子类型关系的心智模型。它们代表了不同的建模过程:
特化(Specialization)
特化是自上而下的过程,与泛化相反。在特化中,我们从一个泛化的实体类型开始,基于不同的特征,将其细分为更专门化的子类型。特化是在识别出一个实体可以有多个独特的分类或实现方式时发生的。
举例:
从VEHICLE这个泛化实体类型出发,我们可能会基于它们的运输能力、用途或其他属性来特化出不同的子类型,如CAR、TRUCK和MOTORCYCLE。这些子类型将继承VEHICLE的所有共同属性,但每个子类型也会有其特定的属性和可能的特定关系。
总结
在现实世界的数据模型开发中,特化和泛化是相辅相成的。泛化帮助我们识别和组织共同属性,而特化则帮助我们基于特定的需求或特征进一步细化实体类型。使用这两种过程,可以构建出一个既灵活又具有层次结构的数据模型,这个模型能够准确地反映现实世界的复杂性和多样性。
Constraints in Supertype: Completeness Constraint
完整性约束(Completeness Constraints)
完整性约束涉及到一个问题:一个超类型的实例是否必须也是至少一个子类型的成员。完整性约束有两个可能的规则:完全特化(total specialization)和部分特化(partial specialization)。
-
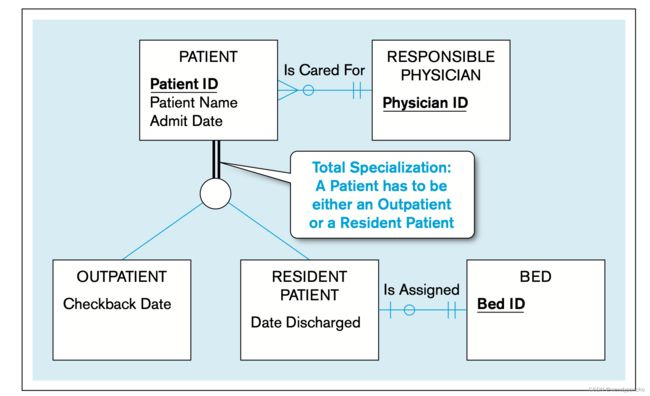
完全特化规则 total specialization rule:指定每个超类型的实体实例必须是关系中某个子类型的成员。这通常是用一条双线从超类型实体类型延伸到圆圈来表示。在这种情况下,例如医院中的患者,必须是门诊患者或住院患者,不存在第三种类型。
-
部分特化规则 Partial specialization rule:指定超类型的实体实例被允许不属于任何子类型。这种情况下,一个实体可以是超类型的实例,但不必然是任何子类型的实例。例如,如果在VEHICLE的数据模型中,摩托车(MOTORCYCLE)是一种车辆,但它没有在数据模型中作为子类型被表示。

Specifying disjointness constraints
A constraint that addresses whether an instance of a supertype may simultaneously be a member of two (or more) subtypes.
不相交规则(Disjoint Rule)
A rule that specifies that an instance of a supertype may not simultaneously be a member of two (or more) subtypes.
不相交规则指出,如果一个超类型的实例是一个子类型的成员,那么它就不能同时是任何其他子类型的成员。这意味着子类型之间是互斥的,一个实例在任何给定的时间只能属于一个子类型。
举例:
考虑病人(PATIENT)的例子,一个病人在任何给定的时间要么是门诊病人(OUTPATIENT),要么是住院病人(RESIDENT PATIENT),但不能同时是两者。在超类型和子类型连接的圆圈中标记字母“d”来表示这是一个不相交的规则。需要注意的是,病人的子类(门诊或住院)可能会随时间变化,但在任何特定的时间点上,病人只能是一种类型

重叠规则(Overlap Rule)
重叠规则指出,一个超类型的实例可以同时是两个(或多个)子类型的成员。这意味着子类型之间可以有重叠,一个实例可以同时属于多个子类型。
A rule that specifies that an instance of a supertype may simultaneously be a member of two (or more) subtypes.
举例:
考虑部件(PART)的例子,有些部件既是制造出来的,也是购买的。这里需要澄清的是,PART的一个实例指的是特定的部件编号(即一种类型的部件),而不是单个部件(由Part No标识符指示)。例如,考虑部件编号4000,当前手头上有250个此类部件,其中100个是制造的,剩下的150个是购买的。在这种情况下,跟踪单个部件并不重要。当跟踪单个部件很重要时,每个部件都会被分配一个序列号标识符,根据该单个部件是否存在,手头上的数量为一或零。
The overlap rule is specified by placing the letter o in the circle, as shown in Figure 3-7b. Notice in this figure that the total specialization rule is also specified, as indicated by the double line. Thus, any part must be either a purchased part or a manufactured part, or it may simultaneously be both of these.
Defining subtype discriminators
A subtype discriminator is an attribute of a supertype whose values determine the target subtype or subtypes.

Supertype/subtype hierarchy
A supertype/subtype hierarchy is a hierarchical arrangement of supertypes and subtypes, where each subtype has only one supertype (Elmasri and Navathe, 1994).
an example oF a supertype/subtype hIerarchy Suppose that you are asked to model the human resources in a university. Using specialization (a top-down approach), you might proceed as follows: Starting at the top of a hierarchy, model the most general entity type first. In this case, the most general entity type is PERSON. List and associ- ate all attributes of PERSON. The attributes shown in Figure 3-10 are SSN (identifier), Name, Address, Gender, and Date Of Birth. The entity type at the top of a hierarchy is sometimes called the root.
Next, define all major subtypes of the root. In this example, there are three subtypes of PERSON: EMPLOYEE (persons who work for the university), STUDENT (persons who attend classes), and ALUMNUS (persons who have graduated). Assuming that there are no other types of persons of interest to the university, the total specialization rule applies, as shown in the figure. A person might belong to more than one subtype (e.g., ALUMNUS and EMPLOYEE), so the overlap rule is used. Note that overlap allows for any overlap. (A PERSON may be simultaneously in any pair or in all three subtypes.) If certain combinations are not allowed, a more refined supertype/subtype hierarchy would have to be developed to eliminate the prohibited combinations.
Attributes that apply specifically to each of these subtypes are shown in the figure. Thus, each instance of EMPLOYEE has a value for Date Hired and Salary. Major Dept is an attribute of STUDENT, and Degree (with components Year, Designation, and Date) is a multivalued, composite attribute of ALUMNUS.
超类型/子类型层级结构中的属性分配和继承有两个重要特点:
-
属性在层级中尽可能高的逻辑级别上分配:
- 这意味着,如果某个属性适用于整个层级中的所有实体,那么这个属性应该被分配给最顶层的实体。例如,如果社会安全号码(SSN)适用于所有人,那么它应该被分配给层级结构的根部,即PERSON实体。相比之下,如果某个属性只适用于层级结构中的某个特定子集,比如“雇佣日期”(Date Hired)只适用于员工,那么它应该被分配给EMPLOYEE实体。这种方法确保了属性能够被尽可能多的子类型所共享。
-
层级结构中较低的子类型不仅继承其直接超类型的属性,还继承所有更高层级超类型的属性:
- 这意味着,层级结构中的任何实体实例都会拥有从根节点到其直接父节点路径上所有实体的属性。例如,FACULTY(教员)实体的一个实例将具有以下所有属性:SSN、Name(姓名)、Address(地址)、Gender(性别)、Date Of Birth(出生日期)(这些来自PERSON);Date Hired(雇佣日期)和Salary(薪资)(这些来自EMPLOYEE);以及Rank(职称)(来自FACULTY本身)。这确保了数据模型的一致性和完整性,同时也减少了数据冗余。
总结来说,超类型/子类型层级结构通过在适当的层级分配属性,并通过继承机制确保属性在层级中向下传递,从而实现了数据模型的高效组织和管理。这种方法不仅有助于确保数据的准确性和一致性,还简化了数据维护和更新的过程。
EER modelIng example: Pine valley Furniture company
After studying this diagram, you might use some questions to help you clarify the meaning of entities and relationships. Three such areas of questions are (see annotations in Figure 3-11 that indicate the source of each question):
-
Why do some customers not do business in one or more sales territories?
-
Why do some employees not supervise other employees, and why are they not all supervised by another employee? And, why do some employees not work in a work center?
-
Why do some vendors not supply raw materials to Pine Valley Furniture?
-
You may have other questions, but we will concentrate on these three to illustrate
how supertype/subtype relationships can be used to convey a more specific (semantically rich) data model.
After some investigation into these three questions, we discover the following business rules that apply to how Pine Valley Furniture does business:
-
There are two types of customers: regular and national account. Only regular customers do business in sales territories. A sales territory exists only if it has at least one regular customer associated with it. A national account customer is asso- ciated with an account manager. It is possible for a customer to be both a regular and a national account customer.
-
Two special types of employees exist: management and union. Only union employees work in work centers, and a management employee supervises union employees. There are other kinds of employees besides management and union. A union employee may be promoted into management, at which time that employee stops being a union employee.
-
Pine Valley Furniture keeps track of many different vendors, not all of which have ever supplied raw materials to the company. A vendor is associated with a contract number once that vendor becomes an official supplier of raw materials.
Rule 1 means that there is a total, overlapping specialization of CUSTOMER into REGULAR CUSTOMER and NATIONAL ACCOUNT CUSTOMER. A composite attribute of CUSTOMER, Customer Type (with components National and Regular), is used to designate whether a customer instance is a regular customer, a national account, or both. Because only regular customers do business in sales territories, only regular customers are involved in the Does Business In relationship (associative entity).
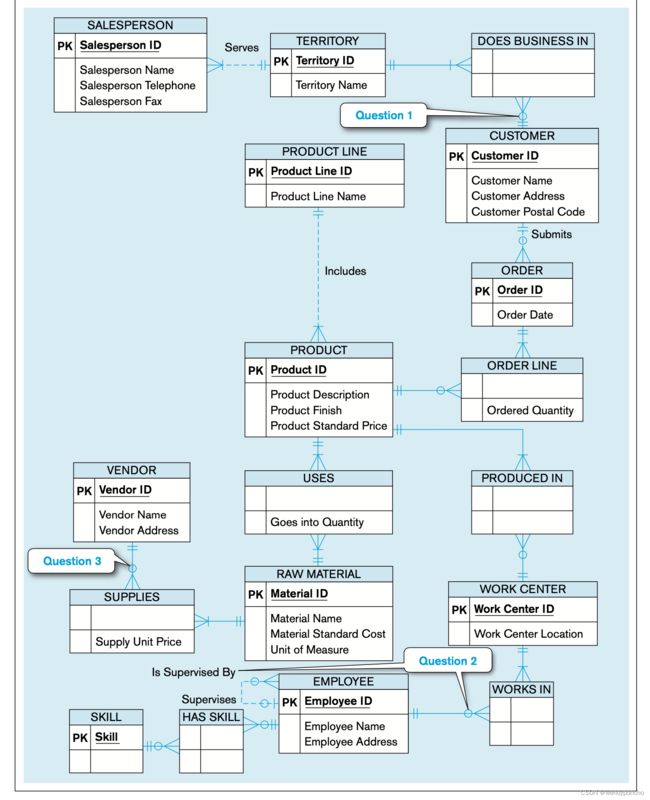
Rule 2 means that there is a partial, disjoint specialization of EMPLOYEE into MANAGEMENT EMPLOYEE and UNION EMPLOYEE. An attribute of EMPLOYEE, Employee Type, discriminates between the two special types of employees. Specialization is partial because there are other kinds of employees besides these two types. Only union employees are involved in the Works In relationship, but all union employees work in some work center, so the minimum cardinality next to Works In from UNION EMPLOYEE is now mandatory. Because an employee cannot be both management and union at the same time (although he or she can change status over time), the specialization is disjoint.
 Rule 3 means that there is a partial specialization of VENDOR into SUPPLIER because only some vendors become suppliers. A supplier, not a vendor, has a contract number. Because there is only one subtype of VENDOR, there is no reason to specify a disjoint or overlap rule. Because all suppliers supply some raw material, the minimum cardinality next to RAW MATERIAL in the Supplies relationship (associative entity in Visio) now is one.
Rule 3 means that there is a partial specialization of VENDOR into SUPPLIER because only some vendors become suppliers. A supplier, not a vendor, has a contract number. Because there is only one subtype of VENDOR, there is no reason to specify a disjoint or overlap rule. Because all suppliers supply some raw material, the minimum cardinality next to RAW MATERIAL in the Supplies relationship (associative entity in Visio) now is one.
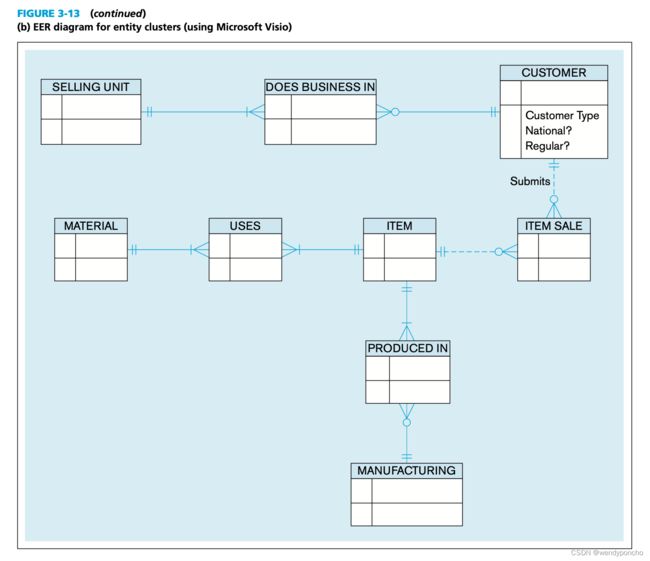
Entity clustering
An entity cluster is a set of one or more entity types and associated relationships grouped into a single abstract entity type. Because an entity cluster behaves like an entity type, entity clusters and entity types can be further grouped to form a higher-level entity cluster. Entity clustering is a hierarchical decomposition of a macro-level view of the data model into finer and finer views, eventually resulting in the full, detailed data model.
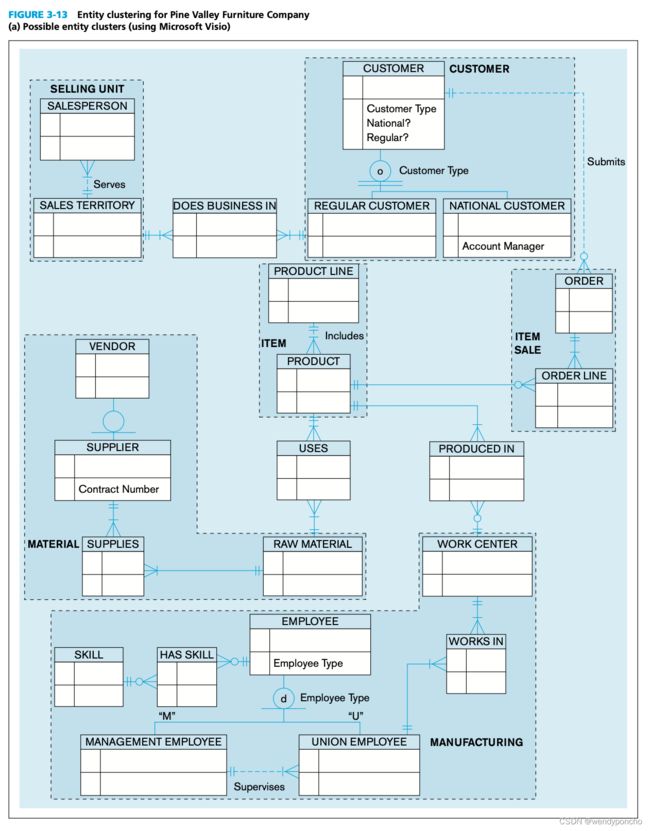
-
SELLING UNIT represents the SALESPERSON and SALES TERRITORY entity types and the Serves relationship
-
CUSTOMER represents the CUSTOMER entity supertype, its subtypes, and the relationship between supertype and subtypes
-
ITEM SALE represents the ORDER entity type and ORDER LINE associative entity as well as the relationship between them
-
ITEM represents the PRODUCT LINE and PRODUCT entity types and the Includes relationship
-
MANUFACTURING represents the WORK CENTER and EMPLOYEE supertype entity and its subtypes as well as the Works In associative entity and Supervises relationships and the relationship between the supertype and its subtypes. (Figure 3-14 shows an explosion of the MANUFACTURING entity cluster into its components.)
-
MATERIAL represents the RAW MATERIAL and VENDOR entity types, the SUPPLIER subtype, the Supplies associative entity, and the supertype/subtype relationship between VENDOR and SUPPLIER.