python基础——字符编码
如有兴趣了解更多请关注我的个人博客https://07xiaohei.com/
前言:
python 2.x默认的字符编码是ASCII,默认的文件编码也是ASCII。
python 3.x默认的字符编码是unicode,默认的文件编码是utf-8。
不同的编码之间不能互相识别,不能相互转化,会报错或出现乱码,所以一定要进行区别。
因此,本篇介绍这三种出现的编码以及额外的中文GB2312编码。
(一)ASCII编码:
1. 概念:
ASCII编码是美国信息交换标准代码,是基于拉丁字母的一套电脑编码,主要用于显示现代英语和其他西欧语言,是最通用的信息交换标准。
2. 产生原因:
所有的数据在存储和运算时都要使用二进制表示,在字符和字符串中,对字母、数字以及一些常用符号的存储需要确定使用哪些确定的二进制数来表示对应的符号,因此,ASCII码产生了。
3. ASCII码内容:
ASCII编码使用1个字节表示常用字符,基础ASCII码字符从对应的二进制数范围从0到127(指定的7位二进制数),扩展则从128到255(指定的8位二进制数)。
基础ASCII码对应内容如下:
-
0~31及127 (共33个)是控制字符或通信专用字符(其余为可显示字符)。
如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;
通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;
ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。
-
32 空格
-
33-47 ! " # $ % & ’ ( ) * + , - . /
-
48-57 数字0-9
-
58-64 : ; < = > ? @
-
91-96 [ \ ] ^ _ `
-
65-90 大写字母A-Z
-
97-122 小写字母a-z
-
123-126 { | } ~
4. python中ASCII码的转换:
事实上下面的两个函数可以传入和Unicode相对应的字符,但这些内容之后讨论。
-
ASCII码转字符函数chr():
形式:chr(int)
int为整数,在此处范围为0~255,可以是十进制和十六进制的形式的数字。
chr函数返回整数对应的字符。
print(chr(112)) # 运行结果: # p -
字符转ASCII码函数ord():
形式:ord(char)
char为字符,在此处传入字符可以是那些ASCII码表内有对应的整数的字符,字符长度为1。
返回值为ASCII码表内对应的整数。
print(ord("a")) # 运行结果: # 97
(二)GB2312编码:
1. 概念:
为了能够在计算机中存储汉字,中国国家标准总局发布了一系列的汉字字符集国家标准编码,这些编码统称为GB码,GB全称GuoBiao,也就是国标,所以也称为国标码。
GB2312是上述编码中最早颁布的和最有影响力的一种汉字编码格式,2312来自于1980年发布的《信息交换用汉字编码字符集 基本集》的标准号GB 2312-1980。
GB2312因其使用的普遍,也被称为国标码(狭义角度),通行于我国内地,几乎所有的中文系统和国际化软件都支持GB2312。
GB2312兼容ASCII码,不过需要进行一些转换才能完成。
2. 产生原因:
为了满足国内在计算机中使用汉字的需要。
3. GB2312内容:
共收录了6763个常用汉字(一级汉字3755个,二级汉字3008个)和682个特殊符号,特殊符号包括数字和字母,但是这些数字和字母占据的是两个字节,和ASCII码的数字和字母的区别,相当于输入法中的"全角"和"半角",编译器只能识别"半角",不能识别"全角",注意区别。
GB2312编码对所收录字符进行了“分区”处理,共94个区,每区含有94个位,共8836个码位。这种表示方式也称为区位码。
01-09区收录除汉字外的682个字符。
10-15区为空白区,没有使用。
16-55区收录3755个一级汉字,按拼音排序。
56-87区收录3008个二级汉字,按部首/笔画排序。
88-94区为空白区,没有使用。
GB2312中每个字符占据2bytes,且最高位不为0(和ASCII码兼容),第一个字节为“高字节”,对应94个区,代表区号;第二个字节为“低字节”,对应94个位,代表位号。
因此,区位码范围是:0101-9494。对区号和位号分别加上0xA0就是GB2312编码。、
例如最后一个码位是9494,区号和位号分别转换成十六进制是5E5E,0x5E+0xA0=0xFE,所以该码位的GB2312编码是FEFE。
从上面可以看出,GB2312编码范围就是A1A1-FEFE,其中汉字的编码范围为B0A1-F7FE,第一字节0xB0-0xF7(对应区号:16-87),第二个字节0xA1-0xFE(对应位号:01-94)。
4. python中GB2312码的转换:
将python字符串编码为GB2312后,类型为bytes,一般以双字节形式保存,如果是可以以一个字节字符保存的按一个字节保存。
print("中国".encode('gb2312'))
print("a".encode('gb2312'))
print(type("中国".encode('gb2312')))
print(len("中国".encode('gb2312')))
print(len("中国"))
print(len("a".encode('gb2312')))
# 运行结果:
# b'\xd6\xd0\xb9\xfa'
# b'a'
#
# 4
# 2
# 1
(三)Unicode标准编码:
1. 概念:
Unicode是国际标准字符集,是计算机科学领域里的一项业界标准。是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求,Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。
注意:Unicode标准编码对应的是一个符号集,规定了每个符号的二进制值,但是没有规定符号如何存储。
2. 产生原因:
为了所有语言都统一到一套编码里,解决ASCII不能表示其他语言的问题。
3. Unicode标准编码内容:
Unicode字符集的标准编码范围是 0x0000 - 0x10FFFF,可以容纳一百多万个字符, 每个字符都有一个独一无二的编码,也即每个字符都有一个二进制数值和它对应,这里的二进制数值也叫码点。
比如:汉字"中"的码点是 0x4E2D, 大写字母A的码点是0x41。
但在Unicode标准编码中,A的存储为0x00000041,必须补0对齐其字节数统一为4(最大存储的字节数为4),Unicode标准编码使用32位进行补0编码的方式占据了过大的空间,浪费了存储空间,因此其不能被用于硬盘存储(文件的存储)和数据传输(网络上的传输)中。
这使得Unicode需要其他的特定编码格式,稍后我们详细介绍其中的一种编码方式:UTF-8编码。
在python中,如果想要进行硬盘存储和数据传输,需要将字符串转化为bytes类型。
4. 字符串前加u、r、b:
-
字符串前加u表示以Unicode格式进行编码,一般用于中文字符串前面(一般字符串是不用加的,因为python默认用Unicode进行编码)。
print(u"123") print(u"中") # 运行结果: # 123 # 中 -
字符串前面加r表示后面的字符串是普通字符串,也就是没有转义字符等其他含义。
print(r"\n\n\n") print(r"123") print(r"中") # 运行结果: # \n\n\n # 123 # 中 -
字符串前面加b表示字符串是bytes类型,只能处理ASCII码内有的类型(其他类型需要编码解码等操作)。
print(b"123") print(b"\n\n\n") # print(b"中") 出错 # # 运行结果: # b'123' # b'\n\n\n'
5. python中Unicode标准编码的转换:
-
Unicode编码转字符函数chr():
形式:chr(int)
int为整数,在此处范围为0~ 1114111,可以是十进制和十六进制 (最大0x10FFFF) 的形式的数字。
chr函数返回整数对应的字符。
print(chr(114514)) # 运行结果: # 可能无法显示,但是确实是个字符 -
字符转Unicode标准编码函数ord():
形式:ord(char)
char为字符,在此处传入字符可以是那些Unicode编码表内有对应的整数的字符,字符长度为1。
返回值为Unicode码表内对应的整数。
print(ord("汉")) # 运行结果: # 27721
(四)UTF-8编码:
1. 概念:
UTF(Unicode Transformation Format),是指Unicode转换格式。
UTF-8是Unicode特定编码的一种,是对Unicode字符串的编码具体实现和存储方法,也是在互联网上使用最广的一种 Unicode 的实现方式。
UTF-8的最大特点就是就是它是一种变长的编码方式,可以使用1~4个字节来表示一个符号,根据不同的符号变化字节长度。
2. 产生原因:
解决Unicode标准编码占用空间过大的问题,统一编码方式。
3. UTF-8编码内容:
UTF-8的编码规则很简单,只有二条:
-
对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的——UTF-8编码能够兼容ASCII编码,这也是互联网普遍采用UTF-8的原因之一。
-
对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表是Unicode编码码点对应UTF-8需要的字节数量以及编码格式:
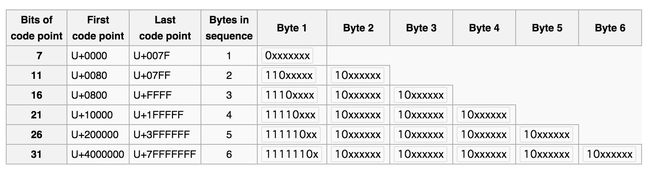
第一列表示Unicode码点的位数;二三列表示码点的取值范围;第四列表示UTF-8需要的字节数;后面几列则是具体的表示,其中的1和0都是固定的前缀,而x表示可编码的二进制位,与前面的码点位数匹配。
可以看出,前面有多少个连续的1,后面就有多少位可编码的字节数,随后的一个0表示停止计量字节数,是对可编码位置和不可编码位置的分割,每个字节的10则是固定前缀。
比如下面的“汉”的Unicode和UTF-8编码对应如下:
print(bin(ord("汉")))
print(bin(int.from_bytes("汉".encode())))
# 运行结果:
# 0b110110001001001
# 0b111001101011000110001001 注意,11100的最后这个0是因为上面是15位,前面有一位空0需要补齐
4. python中UTF-8码的转换:
-
encode()函数
描述:以指定的编码格式编码Unicode标准编码,也就是python的默认字符串,默认编码为 ‘utf-8’。
语法:str.encode(encoding=‘utf-8’, errors=‘strict’)
str未无编码的python默认字符串,Unicode标准编码格式,否则需要先解码再编码。
encoding 参数可选,即要使用的编码,默认编码为 ‘utf-8’,也可以指定gb2312等编码。
errors 参数可选,设置不同错误的处理方案。默认为 ‘strict’,意为编码错误引起一个UnicodeEncodeError。 其它可能值有 ‘ignore’, ‘replace’, 'xmlcharrefreplace’以及通过 codecs.register_error() 注册其它的值。
返回编码后的字符串,bytes类型。
-
decode()函数:
描述:以指定的编码格式解码字符串为Unicode标准编码格式,也就是默认字符串,默认为UTF-8编码进行解码。
语法:str.decode(encoding=‘utf-8’, errors=‘strict’)
str为已编码的字符串,bytes类型,编码格式多种。
encoding 参数可选,即要解码的对应编码,默认为 ‘utf-8’,如:utf-8,gb2312等。
errors参数可选,设置不同错误的处理方案。默认为 ‘strict’,意为编码错误引起一个UnicodeDecodeError。其它可能得值有 ‘ignore’, 'replace’以及通过 codecs.register_error() 注册其它的值。
str1 = "世界"
str2 = b'\xe4\xb8\xad\xe5\x9b\xbd'
str3 ='\n'
str4 = r'\n'
str5 = "\u5408"
print(str1)
print(str1.encode("utf-8"))
print(type(str1.encode("utf-8")))
print(str2)
print(str2.decode("utf-8"))
print(type(str2.decode("utf-8")))
print(str3.encode("utf-8"))
print(str4.encode("utf-8"))
print(str5.encode("utf-8"))
print(str5.encode("utf-8").decode("utf-8"))
# 运行结果:
# 世界
# b'\xe4\xb8\x96\xe7\x95\x8c'
#
# b'\xe4\xb8\xad\xe5\x9b\xbd'
# 中国
#
# b'\n'
# b'\\n'
# b'\xe5\x90\x88'
# 合
(五)python字符串的Unicode存储原因和优化:
1. 原因:
为什么python中依旧要使用Unicode存储而不用UTF-8编码:
UTF-8编码方案的每个字符的占用字节长度是变化的,导致了无法按索引随意访问单个字符,如果对某个字符串str[n]使用UFT-8编码去访问,需要统计前n个字符占用的字节长度,导致了运行时间从 O(1) 变成了 O(n) ,时间开销太大。
因此Python内部需要采用定长的方式存储字符串来加快各种操作的速度,所以依然使用Unicode存储。
2. 优化:
-
三种内部表示Unicode字符串:
为了减少内存的消耗,三种内部表示Unicode字符串
-
每个字符 1 个字节(Latin-1)
如果字符串的所有字符都在ASCII码范围内,那么就可以用占用1个字符的Latin-1编码进行存储。
-
每个字符 2 个字节(UCS-2)
如果字符串中存在了需要占用两个字节的字符,整个字符串全部采用占用2个字节的UCS-2编码存储。
大多数的自然语言只需要2字节编码。
-
每个字符 4 个字节(UCS-4)
如果加入一些极特殊的字符导致有占用4个字节的字符,就会全体采用UCS-4编码,基本和Unicode彼岸准编码一致。
import sys print(sys.getsizeof("a")) print(sys.getsizeof("aa")) print(sys.getsizeof("我")) print(sys.getsizeof("a我")) print(sys.getsizeof("我我")) #运行结果: # 50 # 51 aa-a=1,a占用一个字节 # 76 # 78 a我-我=2,a占用两个字节 # 78 a和我的占用相同了 -
-
字符串驻留机制:
将短小的字符串做成池,当程序创建字符串对象前先检查池中是否有能满足的字符串。
池中驻留的字符串一般为下划线、字母和数字不超过20的字符串。
驻留检查:
- 空字符串
''及所有; - 变量名;
- 参数名;
- 字符串常量(代码中定义的所有字符串);
- 字典键;
- 属性名称;
此机制节省了大量的重复字符串内存。
- 空字符串