美国大学生足球联赛数据集football——DeepWalk算法
一、数据集介绍
football数据集是根据美国大学生足球联赛而创建的一个数据集,包含115支球队(即图中的点)、616条比赛数据(即图中的边)
二、代码分析
1、加载包
import networkx as nx
import random
from tqdm import tqdm
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
2、加载数据集
# 数据加载,构造图
G = nx.read_gml('football.gml')
print('----------------')
#球队总数
print('len(G):', len(G))
#都有哪些球队
print('G.nodes():', G.nodes())
print('----------------')
#都有哪些比赛
# print('G.edges():', G.edges())
运行结果:
len(G): 115
G.nodes(): ['TexasElPaso', 'ArizonaState', 'MiamiFlorida', 'Army', 'MichiganState', 'SanDiegoState', 'ColoradoState', 'MiddleTennesseeState', 'Michigan', 'OhioState', 'AlabamaBirmingham', 'Vanderbilt', 'Mississippi', 'Clemson', 'California', 'NorthCarolina', 'Temple', 'Auburn', 'Maryland', 'Baylor', 'Wisconsin', 'Florida', 'WashingtonState', 'CentralMichigan', 'SouthernMississippi', 'Illinois', 'IowaState', 'BallState', 'Tennessee', 'UtahState', 'Nebraska', 'ArkansasState', 'NewMexico', 'KansasState', 'Indiana', 'Akron', 'SouthCarolina', 'Pittsburgh', 'Memphis', 'Colorado', 'Hawaii', 'Duke', 'Alabama', 'Navy', 'VirginiaTech', 'Tulane', 'Syracuse', 'BostonCollege', 'Arizona', 'FloridaState', 'SouthernMethodist', 'SanJoseState', 'Arkansas', 'TexasTech', 'Wyoming', 'Stanford', 'Kentucky', 'Utah', 'Missouri', 'NorthTexas', 'MississippiState', 'EastCarolina', 'Nevada', 'Purdue', 'PennState', 'LouisianaState', 'Virginia', 'Iowa', 'Tulsa', 'Rutgers', 'NotreDame', 'WesternMichigan', 'AirForce', 'Connecticut', 'Oregon', 'NewMexicoState', 'NorthernIllinois', 'Kansas', 'CentralFlorida', 'Northwestern', 'TexasA&M', 'OregonState', 'Cincinnati', 'LouisianaMonroe', 'Oklahoma', 'TexasChristian', 'Idaho', 'BrighamYoung', 'SouthernCalifornia', 'Marshall', 'Ohio', 'NorthCarolinaState', 'Houston', 'Kent', 'Toledo', 'BowlingGreenState', 'OklahomaState', 'WestVirginia', 'BoiseState', 'Minnesota', 'Texas', 'LouisianaLafayette', 'MiamiOhio', 'NevadaLasVegas', 'GeorgiaTech', 'Louisville', 'LouisianaTech', 'Rice', 'EasternMichigan', 'WakeForest', 'Washington', 'Georgia', 'FresnoState', 'UCLA', 'Buffalo']
----------------
3、deepwalk
从一个点出发,随机游走10个顶点。
def get_randomwalk(node, path_length):
random_walk = [node]
for i in range(path_length-1):
temp = list(G.neighbors(node))
temp = list(set(temp) - set(random_walk))
if len(temp) == 0:
break
random_node = random.choice(temp)
random_walk.append(random_node)
node = random_node
return random_walk
print('----------------')
print('get_randomwalk:', get_randomwalk('EastCarolina', 10))
运行结果
get_randomwalk: ['EastCarolina', 'AlabamaBirmingham', 'Memphis', 'Houston', 'Louisville', 'Tulane', 'LouisianaLafayette', 'NorthTexas', 'BoiseState', 'NewMexico']
100%|██████████| 115/115 [00:00<00:00, 3286.87it/s]
4、所有点随机游走
# 从图获取所有节点的列表
all_nodes = list(G.nodes())
# 捕获数据集中所有节点的随机游走序列
random_walks = []
for n in tqdm(all_nodes):
# 每个节点游走5次,每次最长距离为10
for i in range(5):
random_walks.append(get_randomwalk(n, 10))
# 输出随机游走序列,及序列个数
print('----------------')
print('random_walks:', random_walks)
print('----------------')
print(len(random_walks))
5、使用word2vec训练随机游走的数据
from gensim.models import Word2Vec
import warnings
warnings.filterwarnings('ignore')
# 训练skip-gram (word2vec)模型
model = Word2Vec(window = 4, sg = 1, hs = 0,
negative = 10, # 负采样
alpha=0.03, min_alpha=0.0007,
seed = 14)
# 从random_walks中创建词汇表
model.build_vocab(random_walks, progress_per=2)
model.train(random_walks, total_examples = model.corpus_count, epochs=20, report_delay=1)
print('model:', model)
# 输出和EastCarolina相似的球队
print('model.similar_by_word:', model.similar_by_word('EastCarolina'))
运行结果
575
model: Word2Vec(vocab=115, size=100, alpha=0.03)
model.similar_by_word: [('Army', 0.9480490684509277), ('FloridaState', 0.9365841746330261), ('Louisville', 0.9252589344978333), ('Tulane', 0.9110944867134094), ('AlabamaBirmingham', 0.9061299562454224), ('GeorgiaTech', 0.9037945866584778), ('WakeForest', 0.9031023979187012), ('Virginia', 0.8917067646980286), ('Duke', 0.8815759420394897), ('Maryland', 0.8811277151107788)]
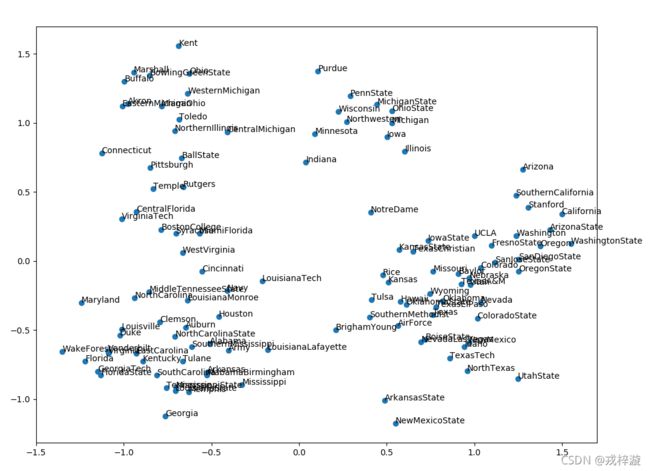
6、绘图
def plot_nodes(word_list):
# 每个节点的embedding为100维
X = model[word_list]
#print(type(X))
# 将100维向量减少到2维
pca = PCA(n_components=2)
result = pca.fit_transform(X)
#print(result)
# 绘制节点向量
plt.figure(figsize=(12,9))
# 创建一个散点图的投影
plt.scatter(result[:, 0], result[:, 1])
for i, word in enumerate(word_list):
plt.annotate(word, xy=(result[i, 0], result[i, 1]))
plt.show()
# 将所有的球队embedding进行绘制
plot_nodes(model.wv.vocab)
运行结果
三、完整代码
# 使用DeepWalk
import networkx as nx
import random
from tqdm import tqdm
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 数据加载,构造图
G = nx.read_gml('football.gml')
print('----------------')
#球队总数
print('len(G):', len(G))
#都有哪些球队
print('G.nodes():', G.nodes())
print('----------------')
#都有哪些比赛
print('G.edges():', G.edges())
"""
随机游走
input: 将节点和被遍历的路径的长度作为输入
output: 返回遍历节点的顺序:
"""
def get_randomwalk(node, path_length):
random_walk = [node]
for i in range(path_length-1):
temp = list(G.neighbors(node))
temp = list(set(temp) - set(random_walk))
if len(temp) == 0:
break
random_node = random.choice(temp)
random_walk.append(random_node)
node = random_node
return random_walk
print('----------------')
print('get_randomwalk:', get_randomwalk('EastCarolina', 10))
# 从图获取所有节点的列表
all_nodes = list(G.nodes())
# 捕获数据集中所有节点的随机游走序列
random_walks = []
for n in tqdm(all_nodes):
# 每个节点游走5次,每次最长距离为10
for i in range(5):
random_walks.append(get_randomwalk(n, 10))
# 输出随机游走序列,及序列个数
print('----------------')
print('random_walks:', random_walks)
print('----------------')
print(len(random_walks))
# 使用skip-gram,提取模型学习到的权重
from gensim.models import Word2Vec
import warnings
warnings.filterwarnings('ignore')
# 训练skip-gram (word2vec)模型
model = Word2Vec(window = 4, sg = 1, hs = 0,
negative = 10, # 负采样
alpha=0.03, min_alpha=0.0007,
seed = 14)
# 从random_walks中创建词汇表
model.build_vocab(random_walks, progress_per=2)
model.train(random_walks, total_examples = model.corpus_count, epochs=20, report_delay=1)
print('model:', model)
# 输出和EastCarolina相似的球队
print('model.similar_by_word:', model.similar_by_word('EastCarolina'))
# 在二维空间中绘制所选节点的向量
def plot_nodes(word_list):
# 每个节点的embedding为100维
X = model[word_list]
#print(type(X))
# 将100维向量减少到2维
pca = PCA(n_components=2)
result = pca.fit_transform(X)
#print(result)
# 绘制节点向量
plt.figure(figsize=(12,9))
# 创建一个散点图的投影
plt.scatter(result[:, 0], result[:, 1])
for i, word in enumerate(word_list):
plt.annotate(word, xy=(result[i, 0], result[i, 1]))
plt.show()
# 将所有的球队embedding进行绘制
plot_nodes(model.wv.vocab)