flink sql运用入门
目录
前言
一、flink是什么?
1.flink api层级
2.flink sql api
二、安装步骤
步骤 1:下载 #
步骤 2:启动集群 #
步骤 3:提交作业(Job) #
步骤 4:停止集群 #
三、SQL 客户端 #
1、准备sql涉及的lib包
2、编写sql脚本
3、web ui查看
总结
前言
目前我司项目中有实时大屏的需求,涉及实时计算部分的选型(以开源为基础),目前主流选择有spark,storm和flink。其中storm只支持流计算,故放弃。spark和flink都能处理流计算和批计算,spark是基于批来模拟流的计算,性能延迟在亚秒级别,虽说也能满足大部分要求,毕竟没有flink这种实时流处理得丝滑。
flink具有灵活的窗口和exactly once语义保证,并且flink计算平台在阿里大面积运用和实践,让我们坚定地选择了flink。
一、flink是什么?
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
1.flink api层级
flink提供了4个层次的api抽象: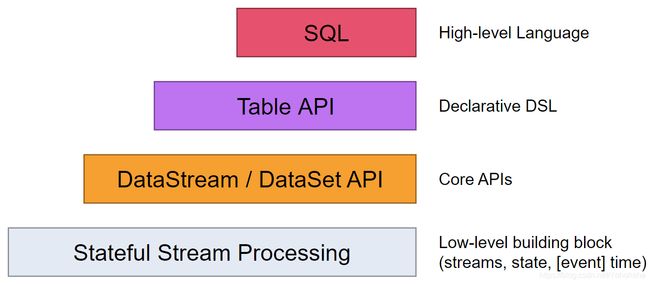
api可以理解为以下两点
1. 越往上层,开发人员写的代码越简洁,面向的开发人员越广。
2. 越往上层,处理的数据越结构化,功能灵活性越低。
2.flink sql api
flink提供的最高层api是flink-sql。它的抽象层次与Table API类似,但是允许用户直接写sql便可以执行job,而无需会写java或scala代码。
因项目组成员没有很深入flink,但是都很熟悉sql,所以推广flink sql在项目中的使用。
二、安装步骤
Flink的运行一般分为三种模式,即local、Standalone、On Yarn、Native Kubernetes,生产环境推荐使用 On Yarn和Native Kubernetes,此处为快速上手,使用最简单的local模式安装。
步骤 1:下载 #
为了运行Flink,只需提前安装好 Java 8 或者 Java 11。你可以通过以下命令来检查 Java 是否已经安装正确。
java -version
下载 release 1.14.4 并解压。
$ tar -xzf flink-1.14.4-bin-scala_2.11.tgz
$ cd flink-1.14.4-bin-scala_2.11
步骤 2:启动集群 #
Flink 附带了一个 bash 脚本,可以用于启动本地集群。
$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host.
Starting taskexecutor daemon on host.
步骤 3:提交作业(Job) #
Flink 的 Releases 附带了许多的示例作业。你可以任意选择一个,快速部署到已运行的集群上。
$ ./bin/flink run examples/streaming/WordCount.jar
$ tail log/flink-*-taskexecutor-*.out
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)
另外,你可以通过 Flink 的 Web UI 来监视集群的状态和正在运行的作业。
步骤 4:停止集群 #
完成后,你可以快速停止集群和所有正在运行的组件。
$ ./bin/stop-cluster.sh三、flink sql运行流程
1、准备sql涉及的lib包
sql作业涉及的包在解压后的Flink lib目录
![]()
我们需要将涉及的连接器的包放入到lib包下后重启flink服务,如kafka 连接器需要flink-connector-kafka_2.11-1.14.4.jar,自定义的mqtt连接器flink-connector-mqtt-talkweb-1.0-SNAPSHOT.jar等

2、编写sql脚本
-- 一、设置sql执行参数
-- 设置job name
SET 'pipeline.name' = '教室控制-今日鉴权次数classroom_authenticationTimes';
-- execution mode either 'batch' or 'streaming'
SET 'execution.runtime-mode' = 'streaming';
-- 启用MiniBatch 聚合
SET 'table.exec.mini-batch.enabled' = 'true';
-- MiniBatch 在允许的延迟间隔
SET 'table.exec.mini-batch.allow-latency' = '10s';
-- MiniBatch 可以缓冲的最大输入记录数
SET 'table.exec.mini-batch.size' = '5000';
-- 二、定义输入
CREATE TABLE IotKafkaTable (
`key` string,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp',
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'kafka',
'topic' = 'topic地址', -- 碰一碰设备上报平板Mac地址
'properties.bootstrap.servers' = 'kafka bootstrap地址',
'scan.startup.mode' = 'earliest-offset',
'key.format' = 'raw', --以下3行为获取kafka key参数
'key.fields' = 'key',
'value.fields-include' = 'EXCEPT_KEY',
'json.ignore-parse-errors' = 'true',
'format' = 'json'
);
-- 三、定义输出
CREATE TABLE classroom_authenticationTimes (
`count` int
) WITH (
'connector' = 'mqtt',
'topic' = 'classroom/authenticationTimes',
'host' = 'mqtt地址',
'retain' = 'true',
'port' = 'mqtt端口'
);
-- 四、根据输入insert输出定义作业
insert into classroom_authenticationTimes
select
cast( count(*) as int) as `count`
from IotKafkaTable t
where t.key like 'tlink/mac%userInfo' and date_format(ts, 'yyyy-MM-dd')=date_format(LOCALTIMESTAMP, 'yyyy-MM-dd');sql脚本编写大致可分层四部分
- 定义sql执行参数,配置job名称,checkpoint等参数
- 定义输入,根据flink自带的连接器或自定义的连接器定义源表
- 定义输出,根据flink自带的连接器或自定义的连接器定义输出表
- 根据输入insert输出定义作业
3、启动SQL 客户端
Flink 的 Table & SQL API 可以处理 SQL 语言编写的查询语句,但是这些查询需要嵌入用 Java 或 Scala 编写的表程序中。此外,这些程序在提交到集群前需要用构建工具打包。这或多或少限制了 Java/Scala 程序员对 Flink 的使用。
SQL 客户端 的目的是提供一种简单的方式来编写、调试和提交表程序到 Flink 集群上,而无需写一行 Java 或 Scala 代码。SQL 客户端命令行界面(CLI) 能够在命令行中检索和可视化分布式应用中实时产生的结果。
启动SQL 客户端 运行sql脚本
./bin/sql-client.sh

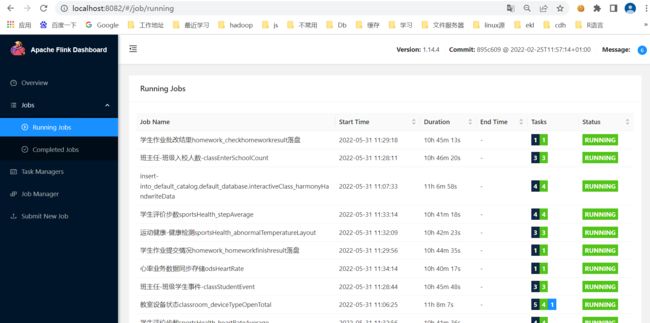
3、web ui查看
flink提供了简单的作业查看界面,提供基本的作业查看,可以提供基本的集群和作业等查看功能
总结
flink底层机制相对比较繁杂,让很多同学望而却步,flink sql能帮助我们快速推广并实施流计算,解决流计算的大部分问题。本文没有从flink的底层概念细说,只引入了flink sql的运用入门,做一个抛砖引玉。