爬虫学习笔记-Cookie登录古诗文网
1.导包请求
import requests2.获取古诗文网登录接口
url = 'https://so.gushiwen.cn/user/login.aspxfrom=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}3.发送请求,获取登录页面源码
response = requests.get(url=url, headers=headers)
content = response.text4.导包获取页面元素
from lxml import etree5.使用xpath获取隐藏域值和验证码
tree = etree.HTML(content)
viewstate = tree.xpath('//input[@id="__VIEWSTATE"]/@value')[0]
viewgenerator = tree.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value')[0]
#验证码
code = tree.xpath('//img[@id="imgCode"]/@src')[0]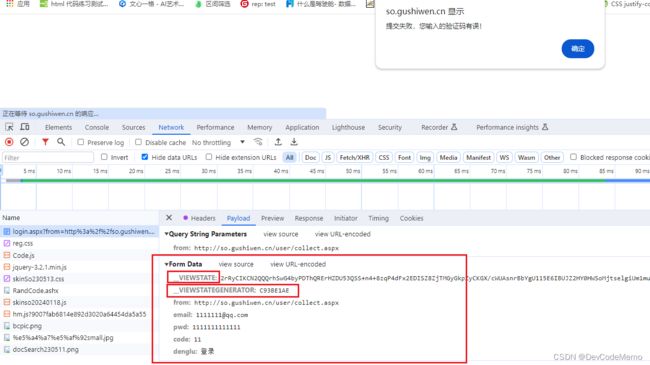 5.将获取验证码的地址拼接成完整的网址
5.将获取验证码的地址拼接成完整的网址
code_url = 'https://so.gushiwen.cn' + code6.建立会话,请求验证码
session = requests.session()
response_code = session.get(code_url)
content_code = response_code.content7.保存验证码图片
with open('code.jpg','wb') as fp:
fp.write(content_code)8.用于人工查看验证码后手动输入
code_name = input('输入验证码')9.将获取的隐藏域数据和验证码拼接到post请求的data中
post_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
post_data = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewgenerator,
'from: http': '//so.gushiwen.cn/user/collect.aspx',
'email': '123',#使用自己的账号名和密码
'pwd': '123',
'code': code_name,
'denglu': '登录',
}10.发送请求
response_post = session.post(url=post_url,data=post_data,headers=headers)11.接收响应内容
content_post = response_post.text12.将响应的内容保存为html格式,手动打开,跳过验证码登录
with open('gushiwen.html','w',encoding='utf-8') as fp:
fp.write(content_post)13.将保存的html文件使用浏览器打开

14.源码
# 导包请求
import requests
# 获取古诗文网登录接口
url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}
# 发送请求,获取登录页面源码
response = requests.get(url=url, headers=headers)
content = response.text
print(content)
# 导包获取页面元素
from lxml import etree
tree = etree.HTML(content)
# 获取隐藏域值
viewstate = tree.xpath('//input[@id="__VIEWSTATE"]/@value')[0]
print(viewstate)
viewgenerator = tree.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value')[0]
print(viewgenerator)
# 获取验证码地址
code = tree.xpath('//img[@id="imgCode"]/@src')[0]
print(code)
# 将获取验证码的地址拼接成完整的网址
code_url = 'https://so.gushiwen.cn' + code
print(code_url)
# 建立会话
session = requests.session()
# 会话请求验证码
response_code = session.get(code_url)
content_code = response_code.content
# 保存验证码
with open('code.jpg','wb') as fp:
fp.write(content_code)
# 用于人工查看验证码后手动输入
code_name = input('输入验证码')
post_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
# 将获取的隐藏域数据和验证码拼接到post请求的data中
post_data = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewgenerator,
'from: http': '//so.gushiwen.cn/user/collect.aspx',
'email': '123', #使用自己的账号名和密码
'pwd': '123',
'code': code_name,
'denglu': '登录',
}
# 发送请求
response_post = session.post(url=post_url,data=post_data,headers=headers)
# 接收响应内容
content_post = response_post.text
# 将响应的内容保存为html格式,手动打开,跳过验证码登录
with open('gushiwen.html','w',encoding='utf-8') as fp:
fp.write(content_post)