人工智能之优化器算法|最优化问题是计算数学中最为重要的研究方向之一。而在深度学习领域,优化算法的选择也是一个模型的重中之重。
一、优化算法
最优化问题是计算数学中最为重要的研究方向之一。而在深度学习领域,优化算法的选择也是一个模型的重中之重。即使在数据集和模型架构完全相同的情况下,采用不同的优化算法,也很可能导致截然不同的训练效果。优化算法可以分成一阶优化和二阶优化算法,其中一阶优化就是指的梯度算法及其变种。
二、优化算法通用框架
优化算法通用框架:
首先定义待优化参数 W,目标函数 Loss(W),初始学习率 α,每次迭代一个 batcℎ。
然后开始进行迭代优化。对训练数据每个批次:
(1)计算 t 时刻损失函数关于当前参数的梯度:

(2)根据历史梯度计算 t 时刻一阶动量和二阶动量:
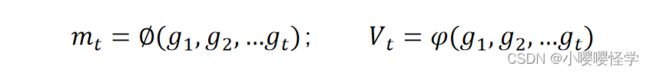
(3)计算 t 时刻的下降梯度:

(4)根据下降梯度进行参数更新(计算 +1 时刻的参数) :
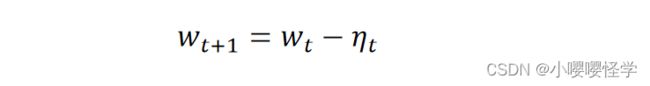
掌握了这个框架,可以设计自己的优化算法了
三、一阶动量和二阶动量
动量是物理学中的概念,一般指物体在它运动方向上保持运动的趋势,是该物体质量和速度的乘积。
动量法是用之前累积动量来代替真正的梯度,这样,每个参数实际更新差值取决于最近一段时间内梯度的加权平均值。一阶动量和二阶动量分别是历史梯度的一阶函数和二阶函数。
四、几中主流优化算法的原理
深度学习优化算法主要有 SGD 、Momentum、AdaGrad、Adam 等。其中随机梯度下降(SGD)算法是基础
1.随机梯度下降(SGD)
SGD 每一次迭代计算 mini-batch 的梯度,然后对参数进行更新,是最常见的优化方法
SGD 中不含动量,也可以认为一阶动量就是梯度,二阶动量为 1,则:
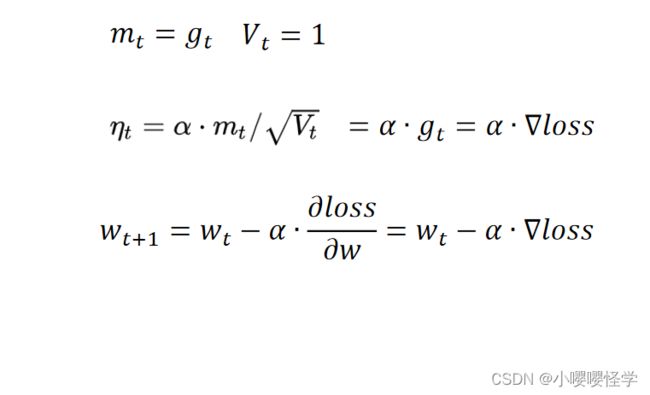
SGD 每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。每次更新可能并不会按照正确的方向进行,因此可能带来优化波动(扰动)。
SGD 最大的缺点是下降速度慢,而且可能会在沟壑的两边持续震荡,停留在一个局部最优点。为了克服震荡,能否加一个惯性,有了惯性以后就会减少震荡。惯性(质量)越大越稳定。

动量(SGD with Momentum)
引入物理动量的概念,加入惯性,减少震荡,最终实现加速收敛的方法。为了抑制 SGD 的震荡, Momentum 认为梯度下降过程可以加入惯性。下坡的时候,如果发现是陡坡,那就利用惯性跑的快一些。给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡,即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。
在 SGD 基础上引入了一阶动量(指数加权平均):

这意味着 t 时刻的下降方向,不仅由当前点的梯度方向决定,而且由此前累积的下降方向决定。
在一些经典卷积深度学习网络结构中(AlexNet、VGG等)都采用了带动量的随机梯度下降法
指数加权平均
假设有 100 天的温度值 v_i ,求出 100天 的平均温度值 v_aver :
24,25,24,26,34,28,33,33,34,35........12,8

所谓的指数平均加权就是:
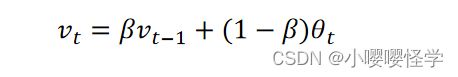
v_t 代表到第 t 天的平均温度值, θ_t 代表第 t 天的温度值,β 代表可调节的超参数值
假如 β=0.9,可以得到指数加权平均如下:
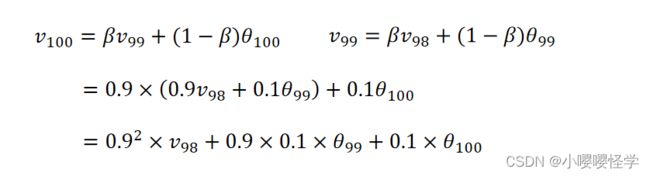
指数加权平均的求解过程实际上是一个递推的过程,当要求从 0 到某一时刻 n 的平均值的时候,不需要保留所有的时刻值,累加然后除以 n。
只需要保留 0 -- (n-1) 时刻的平均值和 n 时刻的温度值即可。这对于深度学习中的海量数据来说,是一个很好的减少内存和空间的做法。
自适应梯度下降(AdaGrad:Adaptive Gradient)
AdaGrad:在 SGD 的基础上增加了二阶动量,可以对模型中的每个参数分配自适应学习率。根据不同参数距离最优解的远近,动态调整学习率大小(不同参数不同)。
当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),期望参数更新的步长大一些,以便更快收敛到最优解。反之步长减小。Ada 是 Adaptive 的缩写,表示“适应环境而变化”的意思。
SGD 算法一直存在一个超参数,即学习率。学习率可以理解为参数 w 沿着梯度 g反方向变化的步长。SGD对所有的参数使用统一的、固定的学习率。一个自然的想法是对每个参数设置不同的学习率,然而在大型网络中这是不切实际的。因此,为解决此问题,AdaGrad 算法应运而生。
其思想是:对于频繁更新的参数,不希望被单个样本影响太大,给它们很小的学习率;对于偶尔出现的参数,希望能多得到一些信息,就给它较大的学习率。
在 SGD 基础上增加二阶动量。二阶动量的出现,意味着“自适应学习率”优化算法时代的到来。可以对模型中的每个参数分配自适应学习率。根据不同参数距离最优解的远近,动态调整学习率大小(不同参数不同)。

可以看出,此时实质上的学习率由 α 变成了α/√V_t ,即对学习率进行缩放
自适应运动估计(Adam:adaptive moment estimation)
Adam:融合 Momentum 和 AdaGrad 的思想优化算法,即同时结合了一阶动量和二阶动量的优势。广泛用于深度学习应用中,尤其是计算机视觉和自然语言处理等任务。
Adam 实现简单,计算高效,对内存需求少,参数的更新不受梯度的伸缩变换影响,更新的步长能够被限制在大致的范围内等等。
【代码示例】
