Hive基于MR/Tez/本地模式的对比
实验环境
内存:16GB
CPU:i5 4590
Centos:6.8
Hive:2.3.6
实验数据
数据量:1138526
字段:3个
实验目的
对比Hive on MR 与 Hive on Tez 以及Hive本地模式在不同语句下的执行效率对比
实验结论
省去看实验过程的麻烦
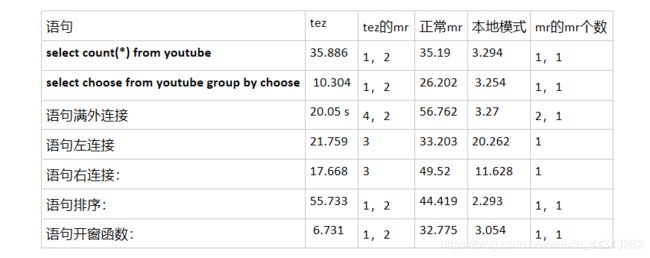
- 本地模式肉眼可见,效果极佳,但是对硬件和内存有一定要求,无法处理大数据量
- Tez优势是将具有依赖的多个作业转换成一个作业,从而减少与HDFS的交互,达到提升效率的目的。
- count和排序优化效果不好的原因是什么——尚未找到合理的解释
- 最初猜想是Tez是将多个作业转换为1个作业,但原本mr的个数就是1效果就没有提高,但表中group by效果是有提高的
- 随后猜想是tez中map和reduce个数明显增加导致的,但是在其他查询语句中都有增加
实验过程
count(*)
语句:select count(*) from youtube
MR:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.27 sec HDFS Read: 33613985 HDFS Write: 8 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 270 msec
OK
_c0
1138562
Time taken: 35.19 seconds, Fetched: 1 row(s)
Local:
Stage-Stage-1: HDFS Read: 67225364 HDFS Write: 146047738 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
1138562
Time taken: 3.294 seconds, Fetched: 1 row(s)
Tez:
Map 1 … SUCCEEDED 1 1 0 0 0 0
Reducer 2 … SUCCEEDED 1 1 0 0 0 0
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 35.11 s
Time taken: 35.886 seconds, Fetched: 1 row(s)
MR与Tez执行时间相差无几
group by
语句:select choose from youtube group by choose
MR:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.74 sec HDFS Read: 33613913 HDFS Write: 11 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 740 msec
OK
choose
left
right
Time taken: 26.202 seconds, Fetched: 2 row(s)
Local:
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 134440078 HDFS Write: 146047757 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
choose
left
right
Time taken: 3.254 seconds, Fetched: 2 row(s)
Tez:
Map 1 … SUCCEEDED 1 1 0 0 0 0
Reducer 2 … SUCCEEDED 1 1 0 0 0 0
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 7.51 s
Time taken: 10.304 seconds, Fetched: 2 row(s)
Tez优于MR
满外连接
语句满外连接:select e.empno, e.ename, d.deptno from emp e full join dept d on e.deptno = d.deptno;
MR:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 14.68 sec HDFS Read: 13418 HDFS Write: 205 SUCCESS
Total MapReduce CPU Time Spent: 14 seconds 680 msec
OK
Time taken: 56.762 seconds, Fetched: 15 row(s)
Local:
Stage-Stage-1: HDFS Read: 5631 HDFS Write: 219066472 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 3.27 seconds, Fetched: 15 row(s)
Tez:
VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
Map 1 … SUCCEEDED 1 1 0 0 0 0
Map 3 … SUCCEEDED 1 1 0 0 0 0
Reducer 2 … SUCCEEDED 1 1 0 0 0 0
VERTICES: 03/03 [==========================>>] 100% ELAPSED TIME: 20.05 s
左连接
语句左连接:select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno = d.deptno;
MR:
Stage-Stage-3: Map: 1 Cumulative CPU: 2.42 sec HDFS Read: 7375 HDFS Write: 196 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 420 msec
OK
Time taken: 33.203 seconds, Fetched: 14 row(s)
Local:
Stage-Stage-3: HDFS Read: 2766 HDFS Write: 73022490 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 20.262 seconds, Fetched: 14 row(s)
Tez:
Map 1 … SUCCEEDED 1 1 0 0 0 0
Map 2 … SUCCEEDED 1 1 0 0 0 0
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 14.87 s
Time taken: 21.759 seconds, Fetched: 14 row(s)
右连接
语句右连接:select e.empno, e.ename, d.deptno from emp e right join dept d on e.deptno = d.deptno;
MR:
Stage-Stage-3: Map: 1 Cumulative CPU: 4.73 sec HDFS Read: 6603 HDFS Write: 205 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 730 msec
OK
Time taken: 49.52 seconds, Fetched: 15 row(s)
Local:
Stage-Stage-3: HDFS Read: 3031 HDFS Write: 73022695 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 11.628 seconds, Fetched: 15 row(s)
Tez:
Map 1 … SUCCEEDED 1 1 0 0 0 0
Map 2 … SUCCEEDED 1 1 0 0 0 0
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 16.91 s
Time taken: 17.668 seconds, Fetched: 15 row(s)
排序
语句排序:select * from emp order by sal desc;
MR:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 11.23 sec HDFS Read: 8516 HDFS Write: 660 SUCCESS
Total MapReduce CPU Time Spent: 11 seconds 230 msec
OK
Time taken: 44.419 seconds, Fetched: 14 row(s)
Local:
Stage-Stage-1: HDFS Read: 7794 HDFS Write: 146046050 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken:2.293 seconds, Fetched: 14 row(s)
Tez:
Map 1 … SUCCEEDED 1 1 0 0 0 0
Reducer 2 … SUCCEEDED 1 1 0 0 0 0
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 54.83 s
Time taken: 55.733 seconds, Fetched: 14 row(s)
开窗函数
语句开窗函数:
select name,orderdate,cost,
lag(orderdate,1,‘1900-01-01’) over(partition by name order by orderdate ) as time1, lag(orderdate,2) over (partition by name order by orderdate) as time2
from business;
MR:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.39 sec HDFS Read: 9333 HDFS Write: 510 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 390 msec
OK
Time taken: 32.775 seconds, Fetched: 14 row(s)
Local:
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 9646 HDFS Write: 146047220 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 3.054 seconds, Fetched: 14 row(s)
Tez:
Map 1 … SUCCEEDED 1 1 0 0 0 0
Reducer 2 … SUCCEEDED 1 1 0 0 0 0
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 6.14 s
Time taken: 6.731 seconds, Fetched: 14 row(s)