大数据技术Hadoop之分布式计算框架MapReduce
1.为什么要学习MapReduce
随着互联网的发展,数据量呈现爆炸式增长,如何高效地处理海量数据成为了互联网企业和科研机构面临的重要问题。Hadoop作为一种分布式计算框架,被广泛应用于大数据处理领域。其中,MapReduce是Hadoop中最重要的组件之一。
2.什么是MapReduce
MapReduce是一种分布式计算框架,它可以将大规模的数据集分成许多小的数据块,然后在分布式计算集群中进行并行处理。MapReduce的核心思想是将数据处理过程分为两个阶段:Map和Reduce。Map阶段将输入数据映射为一系列的键值对,Reduce阶段将Map阶段输出的键值对进行合并和归约。 Map阶段的输入数据可以是任意格式的数据,例如文本、图片、音频等。Map阶段的处理过程可以是任意的计算过程,例如数据清洗、数据过滤、数据转换等。
3.Map以及Reduce阶段处理流程
Map阶段的输出数据是一系列的键值对,其中键表示数据的某个属性,值表示该属性对应的数据。 Reduce阶段的输入数据是Map阶段输出的键值对,Reduce阶段的处理过程可以是任意的计算过程,例如数据聚合、数据统计、数据排序等。Reduce阶段的输出数据是一系列的键值对,其中键表示数据的某个属性,值表示该属性对应的数据。
4.图解MapReduce
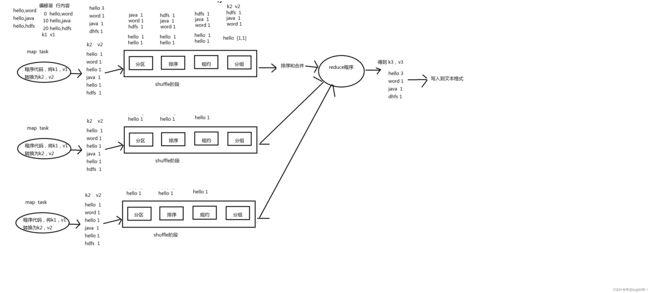
5.MapReduce的优缺点
MapReduce的优点在于它可以将大规模的数据集分成许多小的数据块,然后在分布式计算集群中进行并行处理。这样可以大大提高数据处理的效率和速度。同时,MapReduce还具有良好的可扩展性和容错性,可以在计算集群中添加或删除计算节点,以应对不同规模的数据处理任务。
MapReduce的缺点也很明显,首先不擅长实时计算,另外做不到类似于Mysql等的毫秒级数据处理
6. 大数据入门的“Hello World”
6.1 首先在pom.xml文件添加Hadoop依赖以及log4j
4.0.0
org.example
code
1.0-SNAPSHOT
8
8
org.apache.hadoop
hadoop-client
2.7.7
org.slf4j
slf4j-log4j12
1.7.30
maven-compiler-plugin
3.6.1
1.8
1.8
maven-assembly-plugin
jar-with-dependencies
make-assembly
package
single
6.2 在resources目录下创建log4j.properties文件,添加以下内容
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n添加该文件主要是在终端运行时输出MapReduce运行日志
6.3 创建Map类WordCountMapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper {
// 这里将Key转化为Hadoop的String类型Text
Text k = new Text();
// 将value默认设置为1,这样输出的格式就为
// hello 1
// hello 1
// java 1
// scala 1.......
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
//1. 获取一行数据
String line = value.toString();
//2. 切割数据
String[] words = line.split(" ");
//3.输出数据
for (String word : words){
k.set(word);
context.write(k,v);
}
}
}
![]()
这块代码继承了Mapper方法, LogWritable,Text,Text,IntWritable泛型,其中LogWritable,Text,为Map阶段的输入数据类型,Text,IntWritable为Map阶段的输出数据类型以及Reduce阶段的输入数据类型
6.4 创建Reduce类WordCountReduce
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReduse extends Reducer {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}

这块代码继承了Reducer方法,Text,IntWritable,Text,IntWritable泛型,其中Text,IntWritable为Map阶段的输出数据类型,第二个Text,IntWritable为最终的输出数据类型也就是第一列是字符串,第二列是数字
6.5 创建Driver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1 获取配置信息以及获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 关联本Driver程序的jar
job.setJarByClass(WordCountDriver.class);
// 3 关联Mapper和Reducer的jar
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
// 4 设置Mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
该类主要实现了Job对MapReduce的类绑定以及提交给Hadoop找到程序入口
验证一下,桌面新建一个文件

更改输入和输出路径,注意:要确保这个输出路径文件夹不存在,因为会自动创建
当map和reduce都100%证明成功
![]()
可以看到文件已经生成
![]()
打开下面的part-r-00000
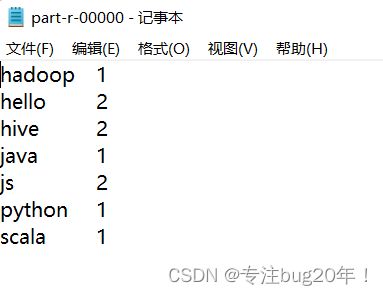
出现结果即为成功
7.总结
总之,MapReduce是Hadoop中最重要的组件之一,它可以将大规模的数据集分成许多小的数据块,然后在分布式计算集群中进行并行处理。MapReduce具有良好的可扩展性和容错性,可以在计算集群中添加或删除计算节点,以应对不同规模的数据处理任务。