复杂SQL治理实践 | 京东物流技术团队
一、前言
软件在持续的开发和维护过程中,会不断添加新功能和修复旧的缺陷,这往往伴随着代码的快速增长和复杂性的提升。若代码库没有得到良好的管理和重构,就可能积累大量的技术债务,包括不一致的设计、冗余代码、过时的库和框架以及不再使用的功能。这些因素都会导致软件结构的脆弱,增加系统出错的可能性,我们俗称为“代码腐化”,持续性的重构是一种好的解决方案。SQL也是我们常用的代码语言,虽然SQL本身作为一种标准化的查询语言不会"腐化",但是使用SQL编写的数据库应用程序、查询和架构确实可能会因时间推移而面临类似于代码腐化的问题。
平台技术部一直坚持做稳定性建设,其中慢SQL就作为一个核心指标在治理。在治理进入深水区时,就会啃到因“SQL腐化”引入的复杂SQL治理这种硬骨头。本文以一个案例为依托来看看怎样像重构Java等高级编程语言一样来重构SQL。
二、JDL路由系统复杂SQL治理案例
路由规划是为保障客户体验,依据产品需求及时效目标,设计物流网络中每个节点的操作时长,然后通过节点互相串联保障全程链通且综合最优,同步输出规划方案并指导运营现场操作,双向校验优化,实现路由规划与实际运营的不断趋合。
简言之,路由系统支持的路由规划就是在做基于物流网络运营的运筹优化,网络是基础。而网络的基础又是线路,必然对线路的操作会“千奇百怪”。
1.问题SQL
select count(*) total_count
from (
select *
from (
select
a.line_store_goods_id as line_resource_id, a.group_num as group_num,
a.approval_erp as approval_erp, a.approval_person as approval_person,
a.approval_status as approval_status, a.approval_time as approval_time,
a.approval_remark as approval_remark, a.master_slave as master_slave,
a.parent_line_code as parent_line_code, a.remarks as remarks, a.operator_time,
a.same_stowage as same_stowage, b.start_org_id, b.start_org_name,
b.start_province_id, b.start_province_name, b.start_city_id, b.start_city_name,
b.start_node_code, b.start_node_name, b.end_org_id, b.end_org_name,
b.end_province_id, b.end_province_name, b.end_city_id, b.end_city_name,
b.end_node_code, b.end_node_name, b.depart_time, b.arrive_time, b.depart_wave_code,
b.arrive_wave_code, b.enable_time, b.disable_time, a.store_enable_time,
a.store_disable_time, a.update_name operator_name, b.line_code,
b.line_type, b.transport_type, IF(a.store_enable_time > b.enable_time,
IF(a.store_enable_time > c.enable_time, a.store_enable_time, c.enable_time),
IF(b.enable_time > c.enable_time, b.enable_time, c.enable_time))
as insect_start_time, IF(a.store_disable_time < b.disable_time,
IF(a.store_disable_time < c.disable_time, a.store_disable_time, c.disable_time),
IF(b.disable_time < c.disable_time, b.disable_time, c.disable_time))
as insect_end_time
FROM (
select * FROM line_store_goods WHERE yn = 1 and master_slave = 1) a
join (
select start_org_id, start_org_name, start_province_id, start_province_name,
start_city_id, start_city_name, start_node_code, start_node_name, end_org_id,
end_org_name, end_province_id, end_province_name, end_city_id, end_city_name,
end_node_code, end_node_name, depart_time, arrive_time, depart_wave_code,
arrive_wave_code, line_code, line_type, transport_type, min(enable_time)
as enable_time, max(disable_time) as disable_time
from line_resource where line_code in (
select line_code from line_store_goods WHERE yn = 1 )
and yn=1 group by line_code) b
ON a.line_code = b.line_code and a.start_node_code = b.start_node_code
join (
select line_code,start_node_code, min(enable_time) as enable_time,
max(disable_time) as disable_time from line_resource
WHERE yn = 1 group by line_code) c
ON a.parent_line_code = c.line_code and a.start_node_code = c.start_node_code) temp
WHERE start_node_code = '311F001' and disable_time > '2023-11-15 00:00:00'
and enable_time < disable_time) t_total;
这是一段运行在生产上的复杂SQL案例,通过慢SQL指标统计识别出来。一眼看过去毫无头绪(说明不仅性能差,而且可读性差,那么必然可维护性差),非功能性指标总是存在很强的关联性。
2.开始治理
step1.格式化
对工程人员而言:要重构,格式化很重要,保证一定的可读性
select count(*) total_count from
(select * from
(select a.line_store_goods_id as line_resource_id, a.group_num as group_num, a.approval_erp as approval_erp, a.approval_person as approval_person, a.approval_status as approval_status, a.approval_time as approval_time, a.approval_remark as approval_remark, a.master_slave as master_slave, a.parent_line_code as parent_line_code, a.remarks as remarks, a.operator_time, a.same_stowage as same_stowage, b.start_org_id, b.start_org_name, b.start_province_id, b.start_province_name, b.start_city_id, b.start_city_name, b.start_node_code, b.start_node_name, b.end_org_id, b.end_org_name, b.end_province_id, b.end_province_name, b.end_city_id, b.end_city_name, b.end_node_code, b.end_node_name, b.depart_time, b.arrive_time, b.depart_wave_code, b.arrive_wave_code, b.enable_time, b.disable_time, a.store_enable_time, a.store_disable_time, a.update_name operator_name, b.line_code, b.line_type, b.transport_type, IF(a.store_enable_time > b.enable_time, IF(a.store_enable_time > c.enable_time, a.store_enable_time, c.enable_time), IF(b.enable_time > c.enable_time, b.enable_time, c.enable_time)) as insect_start_time, IF(a.store_disable_time < b.disable_time, IF(a.store_disable_time < c.disable_time, a.store_disable_time, c.disable_time), IF(b.disable_time < c.disable_time, b.disable_time, c.disable_time)) as insect_end_time
FROM (select *
FROM line_store_goods WHERE yn = 1 and master_slave = 1) a
join (select start_org_id, start_org_name, start_province_id, start_province_name, start_city_id, start_city_name, start_node_code, start_node_name, end_org_id, end_org_name, end_province_id, end_province_name, end_city_id, end_city_name, end_node_code, end_node_name, depart_time, arrive_time, depart_wave_code, arrive_wave_code, line_code, line_type, transport_type, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource where line_code in (select line_code from line_store_goods WHERE yn = 1 ) and yn=1 group by line_code) b
ON a.line_code = b.line_code and a.start_node_code = b.start_node_code
join (select line_code,start_node_code, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource WHERE yn = 1 group by line_code) c
ON a.parent_line_code = c.line_code and a.start_node_code = c.start_node_code) temp
WHERE start_node_code = '311F001' and disable_time > '2023-11-15 00:00:00' and enable_time < disable_time) t_total;
经过格式化之后,能简单判断出SQL的功能是检索满足某条件的线路数量统计。
注意:格式化作为一个重要的工具可以在任意阶段发生作用。
step2.分层拆解
·level0
select count(*) total_count from t_total
·level1 - t_total
select * from temp
WHERE start_node_code = '311F001'
and disable_time > '2023-11-15 00:00:00'
and enable_time < disable_time
·level2 - temp
select
a.line_store_goods_id as line_resource_id, a.group_num as group_num, a.approval_erp as approval_erp, a.approval_person as approval_person, a.approval_status as approval_status, a.approval_time as approval_time, a.approval_remark as approval_remark, a.master_slave as master_slave, a.parent_line_code as parent_line_code, a.remarks as remarks, a.operator_time, a.same_stowage as same_stowage, b.start_org_id, b.start_org_name, b.start_province_id, b.start_province_name, b.start_city_id, b.start_city_name, b.start_node_code, b.start_node_name, b.end_org_id, b.end_org_name, b.end_province_id, b.end_province_name, b.end_city_id, b.end_city_name, b.end_node_code, b.end_node_name, b.depart_time, b.arrive_time, b.depart_wave_code, b.arrive_wave_code, b.enable_time, b.disable_time, a.store_enable_time, a.store_disable_time, a.update_name operator_name, b.line_code, b.line_type, b.transport_type, IF(a.store_enable_time > b.enable_time, IF(a.store_enable_time > c.enable_time, a.store_enable_time, c.enable_time), IF(b.enable_time > c.enable_time, b.enable_time, c.enable_time)) as insect_start_time, IF(a.store_disable_time < b.disable_time, IF(a.store_disable_time < c.disable_time, a.store_disable_time, c.disable_time), IF(b.disable_time < c.disable_time, b.disable_time, c.disable_time)) as insect_end_time
FROM join_table
·level3 - join_table
(select * FROM line_store_goods WHERE yn = 1 and master_slave = 1) a
join (select start_org_id, start_org_name, start_province_id, start_province_name, start_city_id, start_city_name, start_node_code, start_node_name, end_org_id, end_org_name, end_province_id, end_province_name, end_city_id, end_city_name, end_node_code, end_node_name, depart_time, arrive_time, depart_wave_code, arrive_wave_code, line_code, line_type, transport_type, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource where line_code in (select line_code from line_store_goods WHERE yn = 1 ) and yn=1 group by line_code) b
ON a.line_code = b.line_code and a.start_node_code = b.start_node_code
join (select line_code,start_node_code, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource WHERE yn = 1 group by line_code) c
ON a.parent_line_code = c.line_code and a.start_node_code = c.start_node_code
·level4 - a,b,c
select * FROM
line_store_goods
WHERE yn = 1
and master_slave = 1
select start_org_id, start_org_name, start_province_id, start_province_name, start_city_id, start_city_name, start_node_code, start_node_name, end_org_id, end_org_name, end_province_id, end_province_name, end_city_id, end_city_name, end_node_code, end_node_name, depart_time, arrive_time, depart_wave_code, arrive_wave_code, line_code, line_type, transport_type, min(enable_time) as enable_time, max(disable_time) as disable_time
from line_resource
where line_code in (select line_code from line_store_goods WHERE yn = 1 )
and yn=1
group by line_code
select line_code,start_node_code, min(enable_time) as enable_time, max(disable_time) as disable_time
from line_resource
WHERE yn = 1
group by line_code
step3.重构
对于Java程序员而言,《重构 - 改善既有代码的设计》一书应该不陌生。重构的核心在设计原则(“道”&“法”);但是工具包(“术”)同样重要,指导具体落地。
工具包准备:
•层级合并 减少临时表个数
•条件下推 减少检索行数&临时表大小
•join优化 减少检索行数&临时表大小
•子查询删除 减少临时表个数
•子查询与join的相互转换 减少检索行数
重构1 - 层级合并
level0 & level1
如下两个SQL执行效果一致,但是性能表现会有很大差异。
select count(*) total_count from (select * from temp where a = "1")
select count(*) from temp where a = "1"
第二种方式的性能表现会更好一些。原因如下:
1.减少查询计算开销: 在第二种方式中,直接对表进行 count(*) 统计,不需要额外的子查询和临时表操作,可以减少计算的开销。
2.减少内存占用: 第一种方式需要在内存中创建一个临时表来存储子查询的结果,而第二种方式直接对原表进行统计,不需要额外的内存占用。
3.减少磁盘 IO: 第二种方式可以直接利用表的索引进行 count(*) 统计,而第一种方式可能需要额外的磁盘 IO 来处理子查询和临时表的操作。
因此,一般情况下,推荐使用第二种方式来进行 count()统计,以获得更好的性能表现。当然,在实际情况中,也需要根据具体的业务场景和数据量来综合考虑,有时候使用子查询的方式也是必要的,但总体来说,直接对原表进行 count() 统计会更高效。
重构2 - 条件下推
start_node_code = ‘311F001’ 直接下推至level4
SQL的执行是流程化的,从执行层视角看,涉及时空资源消耗最关键的有两类:1-时间(行记录扫描)、2-空间(临时表)。
简化来看,问题SQL的执行过程是子查询形成临时表,而后基于临时表做各种形式的计算(过滤、联合)。
通过条件下推,可以将过滤动作尽可能前置,减少后续过程临时表的大小。
重构3 - join优化
按个人喜好进行格式化

条件下推
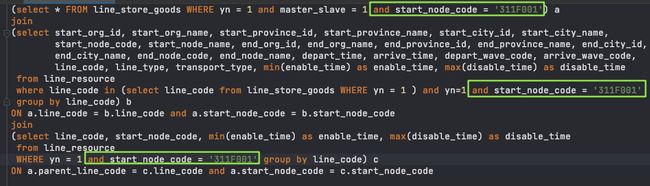
剥离冗余字段,冗余字段在SQL优化过程中是一个影响易读性的干扰信息,剥离冗余字段给工程人员一个干净的画板来尽情施为
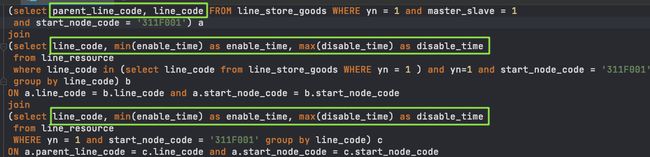
删除无效条件。join的on条件中start_node_code条件因为条件下推已经不再是有效条件。注意,此处为了行文方便做了一定的简化,理论上之前的剥离冗余字段理论上需要包含start_node_code字段查询,在此步骤之后变为冗余字段后被剥离

删除无效子查询。此时从上往下看,表a和表b存在一个奇怪的现象 - 使用了两个类似功能(子查询和join),两者的功能完全一致。题外话:此案例作为反面教材真心不错。 涉及两者的优劣决策,个人做取舍的两个点是性能和可读性。在此案例中功能实现场景特别简单,join的可读性明显更好,在条件限定后扫描行数基本一致,但子查询多一个临时表;综合考量会删除子查询。
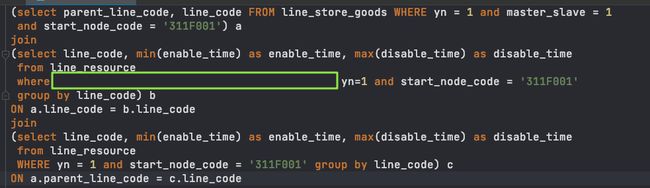
合并冗余join。继续从上往下看,表b和表c看起来一模一样。再次重复题外话:此案例作为反面教材真心不错。
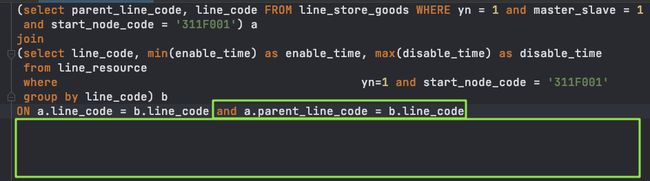
等价条件替换,再次删除冗余字段

经过优化后的join语句,可读性发生了很大的变化 - 简单的双表关联查询。
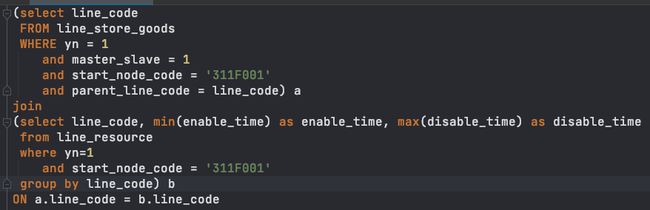
step4.结果的理论验证
select count(*) from (
(select line_code FROM line_store_goods WHERE yn = 1 and parent_line_code = line_code and master_slave = 1 and start_node_code = '311F001') a
join
(select line_code, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource where yn=1 and start_node_code = '311F001' group by line_code) b
ON a.line_code = b.line_code
) where disable_time > '2023-11-15 00:00:00' and enable_time < disable_time
重构后的SQL具备良好的可读性,基于此很容易反推出SQL的业务功能。基于此与其理论应用场景做是否匹配的理论判断很重要。有的时候生产上的SQL不一定是正确的,因为部分场景下可用性并不完全等价于正确性。
step5.索引优化
大量索引优化的文章可参考,此处不再赘述。
step6.结果的测试验证
与代码重构一样,测试通过永远是变更的正确性保证。较为特殊的是SQL改造后功能测试和性能测试都是必要的。
3.效果对比
| | 优化前 | 优化后 |
| 嵌套层级 | 4 | 1 |
| 多表join | 3 | 2 |
| 子查询 | 7 | 2 |
| 耗时 | 4.75s | 0.6s |
三、写在最后
重构的原则具备普适性,但是工具包每个人都有自己用的顺手的一套,没必要完全趋同。
另外,上面的技术能不用就不用,好的前置设计胜过事后的十八般武艺。
作者:京东物流 崔立群
来源:京东云开发者社区 自猿其说 Tech 转载请注明来源