database
A神经典电音之作《Waiting for Love》,歌词温暖励志,激励有梦想的人
这家伙没对象啊,哪个小姐姐行行好把他领走啊
@Li Sihan qq:1809606186
数据库总结
-
- 这家伙没对象啊,哪个小姐姐行行好把他领走啊 @Li Sihan qq:1809606186
- 简答题
-
- 三类题型
-
-
- 一 、关系代数查询和SQL查询
- 二 、关系的函数依赖-第几范式
- 三 、设计E-R模型,转换为等价关系模型
-
- FAQ
-
-
-
-
- 函数依赖:
- 平凡函数依赖与非平凡函数依赖
- 完全函数依赖与部分函数依赖
- 第一范式、第二范式、第三范式、BC范式
- 关系模式规范化的步骤
-
-
- 在这里插入图片描述 三步合为一步:对原关系进行投影,消除决定属性不是候选码的任何函数依赖。
-
- 关系代数
-
-
- 1.并(** ∪ \cup ∪**)
- 差(---)
- 3.交( ∩ \cap ∩)
- 4.笛卡尔积( × \times ×)
- 1.选择( σ \sigma σ)
- 2.投影( π \pi π)
- 3.连接运算( ⋈ \Join ⋈)(双元运算符)
- 除运算( ÷ \div ÷)
-
- SQL的数据定义与数据操纵
- SQL的数据查询
- 嵌套查询
-
简答题
1.简述文件管理数据阶段存在的问题。
- 数据冗余大;
- 相同数据重复存储,独立管理,造成数据不一致性;
- 为某个特定应用服务,系统难以扩充;
- 数据间联系弱;
- 数据独立性差;
- 缺乏对数据的统一管理
2.简述数据库管理数据阶段的特点。
- 数据整体结构化;
- 数据共享性高,冗余少,易扩充;
- 数据独立性高;
- 有统一的数据控制功能
3.试述数据库、数据库管理系统、数据库系统的概念。
- 数据:数据库中存储的基本对象。
数据库:长期存储在计算机内的,有组织的,可共享的,统一管理的数据集合。
数据库管理系统:操纵和管理数据库的软件系统,它由一组计算机程序构成,管理并控制对数据资源的使用。
数据库系统: 在计算机系统的引入数据库后的系统。
{数据库+硬件系统+软件系统+用户}
{软件系统:操作系统+数据库管理系统+应用系统}
{用户:终端用户+应用程序员+数据库管理员}
4…简述数据库系统的三级模式两级映像的体系结构。
- 外模式–外模式/模式映像–概念模式–模式/内模式映像–内模式
- 模式是数据库中数据的整体逻辑结构和特征的描述,是所有用户的公共数据视图,综合了所有用户的需求;
- 外模式是数据库用户使用的局部数据的逻辑结构和特征描述;
- 内模式是数据物理结构和存储方式的描述;
- 外模式/模式映像定义外模式与模式之间的对应关系;
- 模式/内模式映像定义数据全局逻辑结构与存储结构。

5.数据库系统采用三级模式两级映像的体系结构的优点是什么?
- 将外模式和模式分开,保证了数据的逻辑独立性;
- 将模式和内模式分开,保证了数据的物理独立性。
- 按照外模式编写应用程序或运行命令,而不需了解数据库内部的存储结构,方便用户使用系统。
- 多个用户在不同的外模式下共享系统中数据,减少了数据冗余。
- 在外模式下根据要求进行操作,不能对无权限的、有限定的数据操作,保证了其他数据的安全。
6.什么是数据独立性。
在不改变上层应用程序的情况下,能够修改底层数据存储结构或实现技术的能力。数据独立性分为两种主要类型:
物理数据独立性和逻辑数据独立性。
7.关系的特性。
- 不允许出现相同的元组。
- 元组的顺序无关紧要;
- 属性的顺序无关紧要;
- 同一属性名下的各个属性值必须来自同一个域,是同一类型的数据。
- 关系中各个属性必须有不同的名字,不同的属性可来自同一个域 。
- 关系中每一分量必须是不可分的数据项。
8.试述关系模型的实体完整性规则和参照完整性规则。
实体完整性规则:若属性A(一个或一组属性)是基本关系R的主码中的属性,则A不能取空值。
参照完整性规则:
如果属性组K是关系模式R1的主码,同时K也是关系模式R2的外码,那么在R2的关系中,K的取值只允许两种可能:
或者为空值,
或者等于R1关系中某个主码值。
9.试述SQL的特点。(Structured Query Language)结构化查询语言
可以独立完成数据库生命周期的全部活动。
- 定义关系模型
- 对数据进行增删改查
- 数据库重构
- 数据库安全机制
10.简述视图的作用。
- 隐藏敏感数据,提高数据安全性;
- 数据重用,简化复杂查询;
- 简化用户权限管理;
- 逻辑数据独立性。
1.一个不好的关系模式可能存在哪些问题?如何解决这些问题?在此过程中需遵循什么原则?
可能存在的问题:
- 数据冗余;
- 操作异常(包括插入异常、修改异常、删除异常)
解决方法:模式分解。
遵循的原则:分解后的关系模式原模式等价,既要“保持函数依赖性”,又要具有“无损连接性”。
2.简述函数依赖、非平凡函数依赖、完全函数依赖、部分函数依赖、传递函数依赖的概念。
函数依赖:设有关系模式 R(U),U是R的属性集合,X 和Y是U的子集。对于R(U)的任意一个可能的关系r,如果r中不存在两个元组,它们在X上的属性值相同,而在Y上的属性值不同,则称“X函数决定Y”,或“Y函数依赖于X”,记作X→Y
非平凡函数依赖:在关系模式 R(U)中,对于U的子集X和Y,如果X→Y,但Y不包含于 X,则称X → Y 是非平凡的函数依赖。
完全函数依赖:在关系模式R(U)中,XY是关系R的两个属性集合,X’是X的真子集,存在X → Y,但对每一个X’都有 X’! → Y,则称Y完全函数依赖于X。
部分函数依赖:在关系模式R(U)中,XY 是关系R的两个属性集合,存在X → Y,若X’是x的真子集,存在X '→Y,则称Y部分函数依赖于X。
传递函数依赖:在关系模式’R(U)中,XYZ是关系 R中互不相同的属性集合,存在
X→Y(Y!→X)Y→Z。则称Z传递函数依頼于X。
3.什么是关系模式的规范化?简述1NF、2NF、3NF、BCNF的定义。
- 关系模式的规范化:一个低一级范式的关系模式,通过模式分解可以转换若干个高一级范式的关系模式集合的过程。
- 1NF:关系模式R 中每个属性值都是一个不可分解的数据项
- 2NF:关系模式REINF,且它的所有非主属性都完全函数依赖于R的码
- 3NF:关系模式RE2NF,且所有非主属性都不传递函数依赖于码
- BCNF:关系模式 RE1NF,对任何非平凡的函数依赖X→Y,X 均包含码
4.什么是数据库设计?数据库设计一般分为哪几个阶段?每个阶段的主要任务是什么?
数据库设计:对于一个给定的应用环境,构造优化的数据库逻辑模式和物理结构,并据此建立数据库及其应用系统,使之能够有效地存储和管理数据,满足用户的信息管理需求和数据操作需求。
分为六个阶段:
- 需求分析:准确了解与分析用户需求(包括数据与处理)
- 概念结构设计:通过对用户需求进行综合、归纳与抽象,形成一个独立于具体 DBMS的概念模型。
- 逻辑结构设计:将概念结构转换为某个 DBMS 所支持的数据模型,并对其进行优化。
- 物理结构设计:为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构和存取方法)
- 数据库实施:设计人员运用 DBMS提供的数据语言、工具及宿主语言,根据逻辑设计和物理设计的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行。
- 数据库运行与维护:在数据库系统运行过程中对其进行评价、调整与修改。
5.什么是事务?简述事务的特性。
事务是DBMS的基本工作单位,是用户定义的一组逻辑一致的程序序列。是一个不可分劇的工作单位,包含的所有操作,要么都执行,要么都不执行。
事务具有4个特性:原子性(Atomicity )一致性(consistency )隔离性(Isolation)和持续性(Durability )。这4个特性也简称为ACID 特性。
- 原子性:事务是数据库的逻辑工作单位,事务中包括的操作要么都做,要么都不做。
- 一致性:事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。
- 隔离性:一个事务的执行不能被其他事务干扰。 ⌈ \lceil ⌈即一个事务内部的操作及使用的数据对其他并发事务是隔离的,并发执行的各个事务之间不能互相干扰。 ⌋ \rfloor ⌋
- 持续性:(也称永久性)指一个事务一旦提交,它对数据库中的数据改变就应该是永久性的,接下来的其它操作或故障不应该对其执行结果有任何影响。
6.什么是数据库恢复?数据库恢复的基本原理是什么?
数据库恢复:故障发生后,把数据库中的数据从错误状态恢复到某种逻辑一致的状态
基本原理:冗余
7.为什么设置检查点?简述具有检查点的恢复技术的基本策略。
系统故障恢复时的问题:搜索整个日志将耗费大量的时间;很多需要 REDO处理的事务实际上已经将它们的更新操作结果写到数据库中了,然而恢复子系统又重新执行了这些操作,浪费了大量时间。因此,DBMS 定时设置检查点,在检查点时刻才真正做到把对数据库的修改写到磁盘。当数据库需要恢复时,只有检查点后面的事务需要恢复。
最后一个检查点之前结束的事务,什么都不做;
最后一个检查点之前开始,故障之前结束的事务,重做最后一个检查点之后的操作;
最后一个检查点之前开始,故障发生时未结束的事务,撤销己做操作;
最后一个检查点之后开始,故障之前结束的事务,重做事务的全部操作
最后一个检查点之后开始,故障发生时未结束的事务,撤销已做操作
8.什么是日志文件?其作用是什么?登记日志文件遵循什么原则?
- 日志文件:记录事务对数据库中数据的每一次更新操作的文件
- 作用: DBMS 可以根据日志文件进行事务故障的恢复和系统故障的恢复,并可结合后援副本进行介质故障的恢复。
- 登记日志文件遵循的原则:
- 登记的次序严格按并发事务执行的时间次序。
- 必须先写日志文件,后写数据库。
9.什么是并发控制?并发操作可能带来哪些问题?如何解决这些问题?
并发控制:用正确的方式调度并发操作,使一个事务的执行不受其他事务的干扰,从而避免造成数据的不一致性,保证事务的隔离性。
带来的问题:数据不一致性:丢失修改、不可重复读、读“脏”数据
解决:封锁:在事务并发操作对数据对象加锁时,还需要约定一些规则,称这些规则为封锁协议。
- 一级封锁协议可以防止丢失修改;
- 二级封锁协议除了防止丢失修改,还可以进一步防止读“脏数据”,
- 三级封锁协议除了防止了丢失修改和不读“脏”数据外,还进一步防止了不可重复读。
10.什么是封锁?简述基本的封锁类型的含义。
封锁:事务T在对某个数据对象操作之前,先向系统发出请求,对其加锁。在事务T释放它的锁之前,其他的事务不能更新此数据对象。
基本的两种封锁类型:排它锁("x"锁) 和共享锁("S"锁)
排它锁又称写锁(Exclusive lock,简记为X锁):若事务T对数据对象A加上X锁,则只允许T读取和修改A,其它任何事务都不能再对 A加任何类型的锁,直到T释放A上的锁。
共享锁又称为读锁(Sharelock,简记为S锁):若事务T对数据对象A加上S锁,则事务
T可以读A但不能修改A,其它事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。
11.什么是活锁?什么是死锁?简述相应的解决策略。
活锁:某个事务由于请求封锁但总也得不到锁而处于长时间的等待状态。
死锁:在同时处于等待状态的两个或多个事务中,每个事务封锁一部分数据资源,同时等待其他事务释放数据资源。
活锁解决办法:先来先服务;
死锁解决办法:
采取一定措施来预防死锁的发生;
- 一次封锁法;
- 顺序封锁法。
采用一定手段定期诊断系统中有无死锁,若有则解除之
- 诊断方法(超时法或等待图法),
- 解除方法(牺牲法)
12.什么是并发调度的可串行性?如何保证并发调度的可串行性?
- 可串行性的调度:多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行地执行这些事务时的结果相同
- 如何保证:如果并发执行的所有事务均遵守两段锁协议,则对这些事务的所有并发调度策略都是可串行化的。
三类题型
一 、关系代数查询和SQL查询
(注意是关系代数还是SQL)

-
用关系代数查询北京供应商的编号和姓名;
π S N O , S N A M E ( σ C I T Y = ′ 北 京 ′ ( S ) ) \pi_{SNO,SNAME}(\sigma_{CITY='北京'}(S)) πSNO,SNAME(σCITY=′北京′(S))
-
用关系代数查询使用了北京供应商供应的零件的项目名;
π J N A M E ( σ C I T Y = ′ 北 京 ′ ( S ⋈ S P J ⋈ J ) ) \pi_{JNAME}(\sigma_{CITY='北京'}(S \Join SPJ \Join J)) πJNAME(σCITY=′北京′(S⋈SPJ⋈J))
-
用关系代数查询没有使用天津供应商生产的红色零件的工程号;
π J N O ( σ C I T Y < > ′ 天 津 ′ a n d C O L O R = ′ 红 色 ′ ( S ⋈ S P J ⋈ P ⋈ J ) ) \pi_{JNO}(\sigma_{CITY<>'天津'and COLOR='红色'}(S \Join SPJ \Join P \Join J)) πJNO(σCITY<>′天津′andCOLOR=′红色′(S⋈SPJ⋈P⋈J))
-
用关系代数查询至少使用了供应商S1所供应的全部零件的工程号JNO;
π J N O ( σ S N O = ′ S 1 ′ ( S P J ) ) − π J N O ( ( π P N O , J N O ( S P J ) − π P N O , J N O ( σ S N O = ′ S 1 ′ ( S P J ) ) ) ) \pi_{JNO}(\sigma_{SNO='S1'}(SPJ))-\pi_{JNO}((\pi_{PNO,JNO}(SPJ)-\pi_{PNO,JNO}(\sigma_{SNO='S1'}(SPJ)))) πJNO(σSNO=′S1′(SPJ))−πJNO((πPNO,JNO(SPJ)−πPNO,JNO(σSNO=′S1′(SPJ))))
-
用SQL查询红色零件的名称;
select PNAME from P where COLOR = '红色'; -
用SQL查询供应工程J1零件为红色的供应商号SNO;
select distinct SNO from SPJ where JNO = 'J1' and PNO in (select PNO from P where COLOR = '红色' ); -
用SQL查询没有使用天津供应商生产的零件的工程号;
select distinct JNO from SPJ where SNO not in (select SNO from S where CITY = '天津'); -
用SQL查询提供全部零件的供应商名;
select S.NAME from S where not exists (select PNO from P where not exists (select * from SPJ where SPJ.PNO=P.PNO and SPJ.SNO=S.SNO)); -
用SQL语句将全部红色零件改为蓝色;
update P set COLOR = '蓝色' where COLOR = '红色'; -
用SQL语句将(S2,P4,J6,400)插入供应情况关系SPJ。
insert into SPJ (SNO, PNO, JNO, QTY) values ('S2', 'P4', 'J6', 400);
二 、关系的函数依赖-第几范式

-
关系R的候选码是(A,B,C),REINF,因为R中存在非主属性D,E对候选码 (A,B,C)的部分函数依赖。
-
首先消除部分函数依赖
将关系分解为:
R1(A, B, C)(A, B, C) 为候选码,R1 中不存在非平凡的函数依赖
R2(B,C, D, E),(B,C)为候选码,
R2 的函数依頼集为:F2={(B,C)→D,D→E}
在关系R2 中存在非主属性E对候选码(B,C)的传递函数依赖,所以将 R2进一步分解:
R21(B,C, D),(B, C) 为候选码,R21 的函数依赖集为:F21={(B,C)→ D}
R22(D, E),D为候选码,R22 的函数依赖集为:F22={D→E}
在R1中已不存在非平凡的函数依赖,在R21、R22 关系模式中函数依赖的决定因素均为候选码,所以上述三个关系模式均是 BCNF。
三 、设计E-R模型,转换为等价关系模型
(主码属性下添加下划线)


学院(学院编号,学院名称),主码:学院编号.
课程(课程编号,课程名称,学院编号),主码:课程编号,外码:学院编号
学生(学号,姓名,性别,出生日期,学院编号),主码:学号,外码:学院编号
教师(教师编号,姓名,性别,职称,学院编号),主码:教师编号,外码:学院编号
讲授(教师编号,课程编号),主码:(教师编号,课程编号),外码:教师编号,课程编号
选修(学号,课程编号,成绩),主码:(学号,课程编号),外码:学号,课程编号
FAQ
- 数据模型:{数据结构+数据操作+完整性约束}
- 完整性约束:{实体完整性+参照完整性+用户自定义的完整性}
一个关系对应一张表;
元组:表中的一行;
属性:表中的一列;
- 属性名:每列名称
- 域:具有相同数据类型的值的集合 | 属性的取值范围
- 分量:元组的一个属性值
超码:在一个关系中,能唯一标识元组的属性或属性集
候选码:一个属性集能唯一标识元组,且又不含有多余的
属性,包含在任何一个候选码之中的属性称为主属性,不包
含在任何一个候选码之中的属性称为非主属性。主码:表中某个属性组,它们的值唯一标识一个元组,并且没有多余属性。一个关系有一个或多个候选码,则选定其中一个
外码:设F是基本关系R的一个或一组属性,但不是关系R的
主码。如果F与基本关系S的主码Ks相对应,则称F是
基本关系R的外码。主码必定为候选码,候选码必定为超码,反之不一定。
一个关系的主码只有一个。 候选码、超码可能有多个。关系模式:对关系数据结构的描述
关系:笛卡尔积的有意义的有限子集。元组的集合,是某一时刻关系模式的状态或内容。
函数依赖:
设有关系模式R(U),U是R的属性集合,X和Y是U的子集。对于R(U)的任意一个可能的关系r,如果r中不存在两个元组,它们在X上的属性值相同,而在Y上的属性值不同,则称“X函数决定Y”或“Y函数依赖于X”,记做: X→Y
平凡函数依赖与非平凡函数依赖
在关系模式R(U)中,对于U的子集X和Y,如果X→Y,但Y 不是X的子集,则称X→Y是非平凡的函数依赖。 若X→Y,且Y 是X的子集, 则称X→Y是平凡的函数依赖。
完全函数依赖与部分函数依赖
在关系模式R(U)中,如果X→Y,并且对于X的任何一个真子集X ,都有X→ Y,则称Y完全函数依赖于X;若X→Y,但Y不完全函数依赖于X,则称Y部分函数依赖于X。
第一范式、第二范式、第三范式、BC范式
1NF:关系模式R 中每个属性值都是一个不可分解的数据项
2NF:关系模式REINF,且它的所有非主属性都完全函数依赖于R的码
3NF:关系模式RE2NF,且所有非主属性都不传递函数依赖于码
BCNF:关系模式 RE1NF,对任何非平凡的函数依赖X→Y,X 均包含码
关系模式规范化的步骤
三步合为一步:对原关系进行投影,消除决定属性不是候选码的任何函数依赖。
关系代数
(一种抽象的查询语言,用于对关系的运算来表达查询)

完备的操作集并不只有这一个。
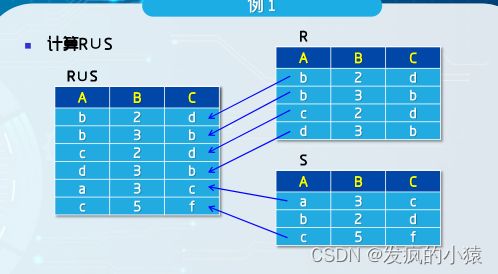
1.并( ∪ \cup ∪)
设R和S是相容的,则R和S的并运算是由属于R和S的元组组成
的新的关系,其结果仍为n元的关系,记为R∪S。 一个元组在并集中只出现一次。
差(—)
设R和S是相容的,则R和S的差是由属于R而不属于S的所有元组组成
的新关系,其结果仍为n元的关系,记为 R-S。

3.交( ∩ \cap ∩)
设R和S是相容的,关系R和S的交是由属于R又属于S的元组组
成的新关系,结果仍为n元的关系,记为 R∩S 。

4.笛卡尔积( × \times ×)
关系 R 和关系 S 的元数分别为 r 和 s。定义 R 和 S 的笛卡尔积
R×S是一个 ( r+s ) 元的元组集合,每个元组的前 r 个分量 (
属性值 ) 来自 R 的一个元组,后 s 个分量来自 S 的一个元组,
记为 R×S。

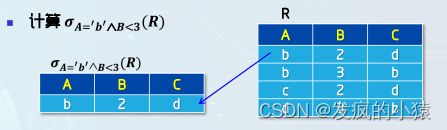
1.选择( σ \sigma σ)
选择运算是从关系R中选取使逻辑表达式F为真的元组,是从
行的角度进行的运算。
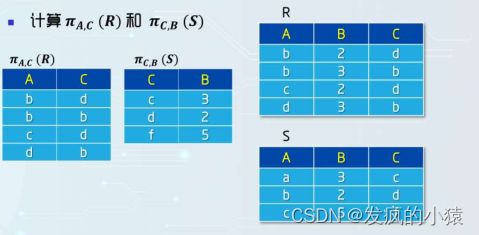
2.投影( π \pi π)
投影操作是从列的角度进行运算。
3.连接运算( ⋈ \Join ⋈)(双元运算符)

等值连接:θ为“=”的连接运算称为等值连接。
自然连接:一种特殊的等值连接;两个关系中进行比较的分量必须是相同的属性组
在结果中把重复的属性列去掉。

自然连接与等值连接的不同
等值连接中做相等比较的属性可以是相同属性,也可以是不同属
性。自然连接中做相等比较的属性必须是相同的属性。自然连接结果必须去掉重复的属性,而等值连接结果不必。
自然连接用于有公共属性的情况。如果两个关系没有公共属性,
那么它们不能进行自然连接。而等值连接无此要求。什么时候可能会用到自然连接?
多表检索
除运算( ÷ \div ÷)
什么时候可能用到除法?
问题中出现‘至少’、‘全部’、‘所有’等类似的集合包含
的概念时,可能会用到除法。
使用除法时,关键的问题是正确构造除关系和被除关系。
除关系S,必须要包含条件列,无关列也可以有,它不会影响
除法运算的结果。
被除关系R,由结果列加上条件列构成,不能有无关的列,无
关的列会影响到运算的结果。

SQL的数据定义与数据操纵
SQL可以独立完成数据库生命周期中的全部活动
- 定义关系模型
- 输入、修改和删除数据
- 查询数据
- 数据库重构
- 数据库安全控制

<!--数据库的定义-->
create database <数据库名> <其他参数>
> create database SaleProduct
<!--数据库的删除-->
drop database <数据库名>
> drop database SaleProduct
> 如果数据库在使用,则无法删除

<!--基本表的定义-->
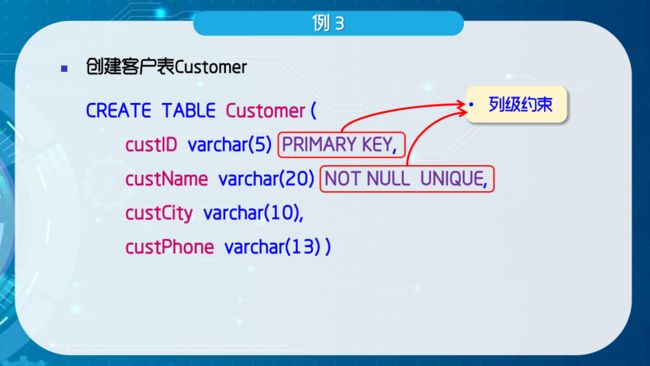
create table <基本表名>
(<列名> <列数据类型> [列完整性约束]
,<列名> <列数据类型> [列完整性约束]
,<列名> <列数据类型> [列完整性约束]
....]
[,表级完整性约束])


<!--基本表的删除-->
drop table <基本表名1> [,......]
> drop table OrderDetail
> 只有在没有视图或约束引用该基本表时,才能删除
<!--插入数据-->
insert into <基本表名> [(<列名1>,<列名2>,<列名3>,...,<列名n>)]
values(<列值1>,<列值2>,...,<列值n>)
> 新元组属性列个数、顺序、数据类型和基本表名后面的属性列表一一匹配。
新插入的元组,没有给定的列值,系统会自动填充为空值。
表名后如果有属性名列表,必须包含该关系的所有非空属性
属性名列表的顺序,不是必须与表定义的顺序相同。
<!--删除数据-->
delete from <表名> [where <条件>]
> 有where子句,删除符合条件的元组
> 没有where子句,删除全部元组。
<!--修改数据-->
> 用来对表中一行或多行中的某些值进行修改
update <表名>
set <列名> = <表达式>[,<列名>=<表达式>]
[where <表达式>]
插入、删除、修改语句,一次只能操作一个数据表。
关系模型的三类完整性约束
- 实体完整性
- 参照完整性
- 用户定义的完整性
SQL的数据查询
select [all|distinct] [top 表达式1 [percent]] [with TIES] <列名或表达式>[列别名1] [,<列名或表达式>[列别名2]...]
-- with ties返回与规定的最后一个元组具有相同排序值的其它所有行
[into 新基本表]
from <表名或视图名> [表别名1] [,<表名或视图名> [表别名2]...]
[where <条件表达式1>]
[group by <列名1> [having <条件表达式2>]]
[order by <列名2> [ASC|DESC]]
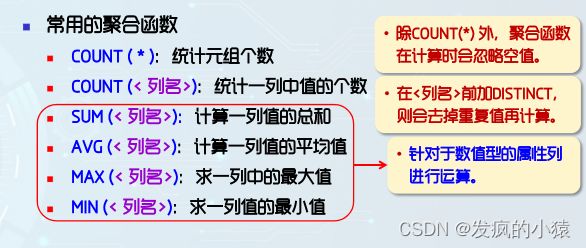
- select子句用于指定要查询的结果列,结果列之间用逗号隔开,结果列可以是属性列、常量值、聚合函数或表达式。必要时可以为结果列重新命名。
- into 子句用于将查询的结果列插入到指定的新的基本表中。
- from 子句用于指定查询结果的数据来源,即查询所涉及的基本表或视图。可以是一个表或多个表,多个表时中间用逗号隔开。
- where 子句用于指定从数据源获取元组需满足的条件。条件表达式可以包含算数运算符、逻辑运算符、关系比较运算符以及SQL特有的运算符。针对某一个元组,条件表达式的值为逻辑值“真”或“假”。
- group by 和 having 子句用于分组和分组过滤处理。它能把在指定属性列中有相同值的记录合并成一条记录。一般情况下,如果select子句中结果列用了聚合函数,则会用到group by子句。having子句可以用来过滤不符合条件的分组.
- order by子句决定查找出的元组的排列顺序。在order by子句中,可以指定一个或多个属性列作为排序依据,ASC升序,DESC降序 默认为ASC。
语句的执行过程:
从FROM子句指定的基本表或视图中,
选取符合WHERE子句中指定的<条件表达式1>的元组。
如果没有GROUP BY子句,则按SELECT子句中的目标列表,选出元组中的分量值形成结果表。
如果有GROUP BY子句,则将符合<条件表达式1>的元组,按照指定的列名1
的值分组,值相同的元组分在一组,每个组产生结果表中的一个元组。
如果有HAVING子句,则在分组结果中去掉不满足HAVING子句<条件表达式2>
的分组。
如果有ORDER BY子句,则结果表根据指定的列名2的值按升序或降序排序。
如果有INTO子句,则创建新的基本表,并将查询结果存入新建的基本表中。




注意:
- where所设置的查询条件针对每个元组;having设置的查询条件针对每个分组( by).
2. 使用distinct保留字可以消除重复元组,默认是不消除重复元组,ALL
3. 字符串匹配查询:like | not like
4. 空值查询: is null | is not null
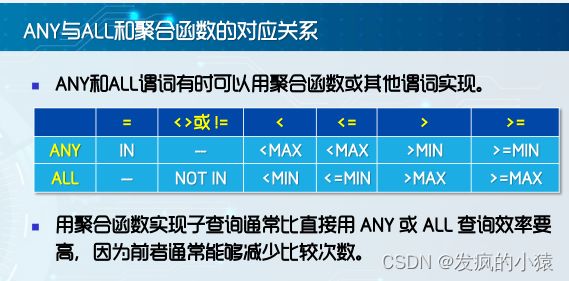
使用 in 的查询 (IN 等价于用多个 OR 连接起来的复合条件)
-- 查询北京和广州客户的基本情况 select * from Customer where custcity in ('北京','广州') -- where custcity='北京' or custcity='广州'TOP短语指定返回查询结果的“前"一组结果,该短语必须和order by一起使用。
-- 查询所有商品中库存数量最少的两种商品的基本信息。 select top 2 * from product order by pdsize属性列是聚合函数时,没有列名可以为其命名。
集合操作:并操作UNION,交操作INTERSECT,差操作EXCEPT参与集合操作的各查询结果必须是相容的列数必须相同,对应属性列的数据类型必须相同。UNION、INTERSECT会把查询结果的去掉重复元组。
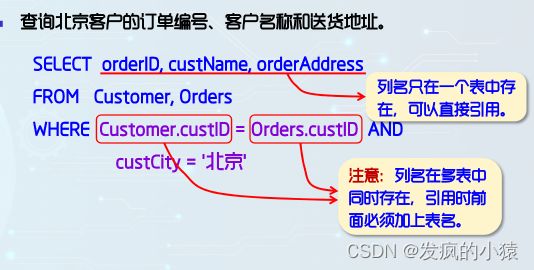
连接查询:select和where后面引用的属性列在两个或多个表同时存在,为了避免产生二义性,在列名前加上表名及一个小圆点。
inner join…on 形式的自然连接查询(内连接)
-- 查询北京客户的订单编号、客户名称、商品编号、商品名称和订购数量 -- select Orders.orderID,custName,Product.pdID,pdName,quantity -- from Customer,Orders,Product,OrderDetail -- where Customer.custID=Orders.custID AND -- Orders.orderID=orderDetail.orderID AND -- OrderDetail.pdID=Product.pdID AND -- custCity='北京' select Orders.orderID,custName,Product.pdID,pdName,quantity from Customer inner join Orders on Customer.custID=Orders.custID inner join OrderDetail on Orders.orderID=orderDetail.orderID inner join Product on OrderDetail.pdID=Product.pdID别名和子连接查询:可以对同一个表取两个别名
外连接查询:左外连接(left join…on…) 右外连接(right join…on…) 全连接(full join…on…) 外连接操作以指定表为连接主体,将主体表中不满足连接条件
的元组一并输出 。






嵌套查询
一个select-from-where语句结构称为一个查询块。
将一个查询块嵌套在另一个查询块的where子句或having短语的条件表达式中的查询,称为嵌套查询。
子查询中不能使用 order by 子句
-
内外层不相关的嵌套查询
子查询的查询条件不依赖于父查询
way: 由里向外逐层处理。即每个子查询在上一级查询处理之前求解,子查询的结果用于建立其父查询的查询条件。


-
内外层相关的嵌套查询
子查询的查询条件依赖于父查询
使用[ not ] exits (子查询)
结果只与子查询的结果是否为空有关。