【超详细教程】GPT-SoVITs从零开始训练声音克隆教程(主要以云端AutoDL部署为例)
目录
一、前言
二、GPT-SoVITs使用教程
2.1、Windows一键启动
2.2、AutoDL云端部署
2.3、人声伴奏分离
2.4、语音切割
2.5、打标训练数据
2.6、数据集预处理
2.7、训练音频数据
2.8、推理模型
三、总结
一、前言
近日,RVC变声器的创始人(GitHub昵称为RVC-Boss)与AI音色转换技术专家Rcell合作,共同开发并开源了一款创新的跨语言音色克隆工具——GPT-SoVITS。这个项目在互联网上迅速获得了广泛关注和好评,众多业界大佬和知名博主都对其给予了推荐。自项目上线以来,短短两天内,它在GitHub上的Star数就达到了1.4k,而现在这个数字已经飙升至6.5k。
GPT-SoVITS的开发历时半年,期间RVC-Boss和Rcell面临了诸多挑战。这款工具不仅具有低成本和易用性的特点,而且在音色克隆领域展现出了新颖的技术创新。
项目地址:https://github.com/RVC-Boss/GPT-SoVITS
二、GPT-SoVITs使用教程
2.1、Windows一键启动
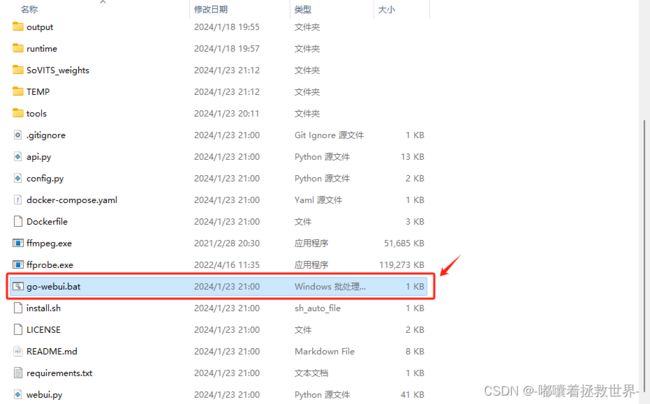
首先下载软件包,解压后双击打开“go-webui.bat”即可。
GPT-SoVITs安装包下载
2.2、AutoDL云端部署
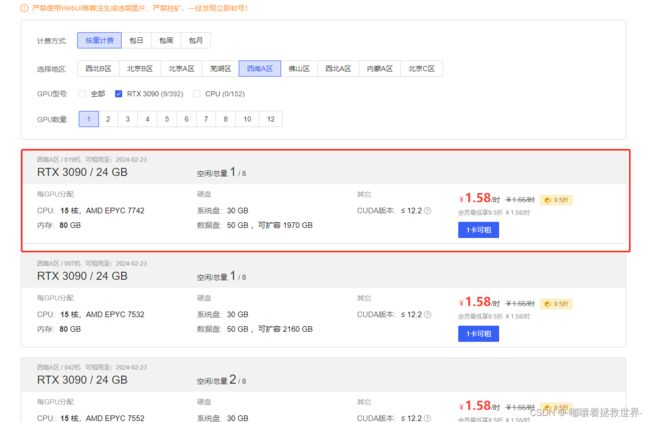
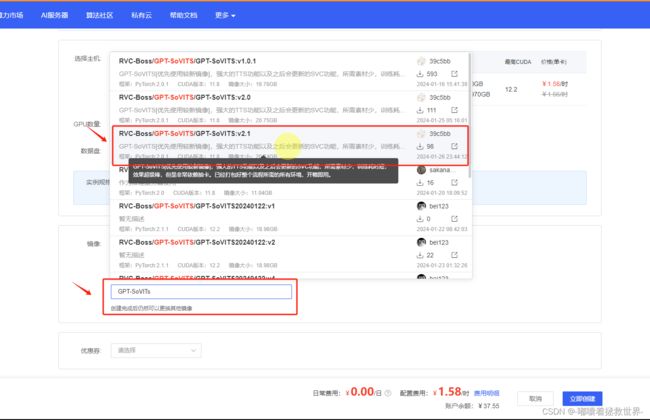
首先打开AutoDL网页,注册登录后进入到“算力市场”,选择一个性价比高的显卡,CUDA版本需要大于11.8,这里我选择RTX3090显卡为示例。
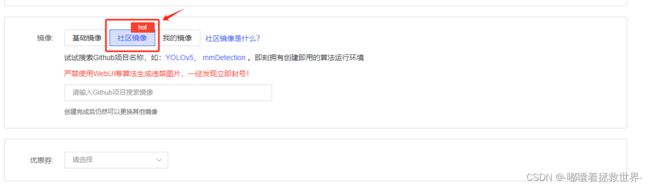
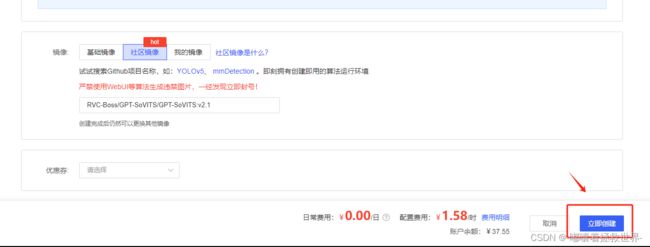
接着来到创建实例界面,点击“社区镜像”,输入“GPT-SoVITs”,选择最新的镜像文件,比如我这里的v2.1版本,然后点击“立即创建”即可。
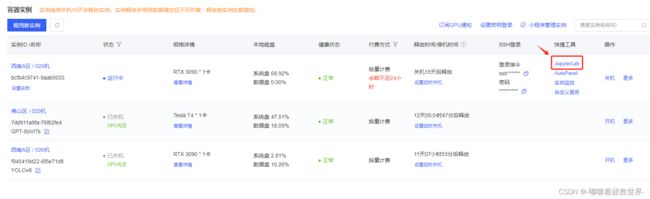
来到容器实例界面,点击刚刚创建好的容器,点击“JupyterLab”进入终端操作界面。
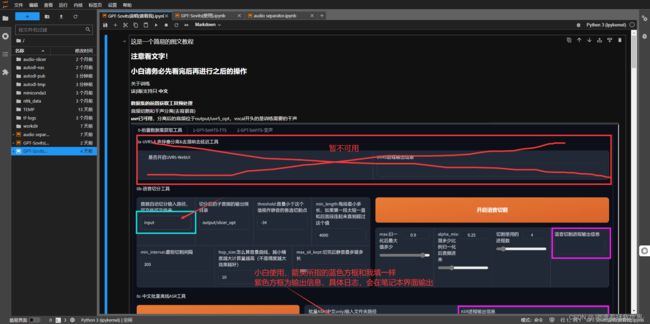
点击第二个选项框,进入使用界面,拉到最下面,运行前两个命令,选择命令框点击运行即可。

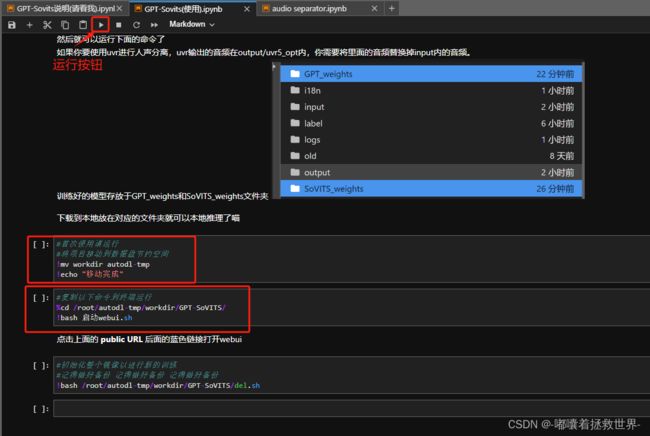
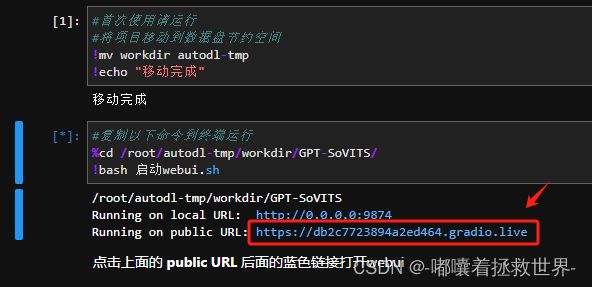
最后打开下方图片链接即可打开GPT-SoVITs界面啦~

2.3、人声伴奏分离
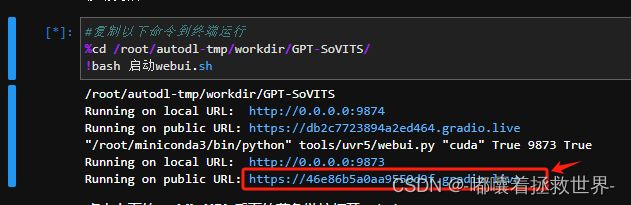
首先准备一段1分钟以上的音频文件,必须是同一个人说话的声音喔,点击开启UVR5-WebUI,回到AutoDL的终端操作界面,查看命令行中的链接,点击进入WebUI界面。

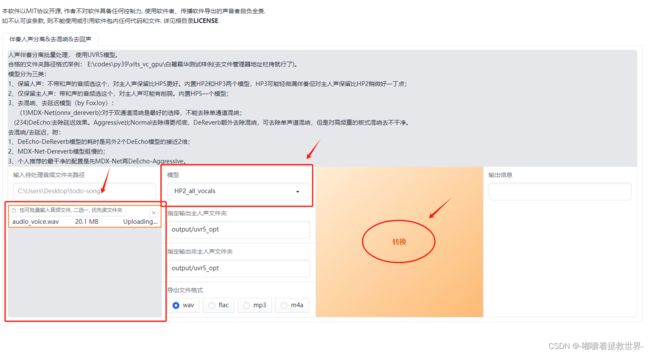
来到人声分离WebUI界面,上传1分钟以上的音频文件进行声音分离,选择好模型,选择好导出的文件格式,点击“转换”即可,转换好的文件位于output/uvr5_opt。
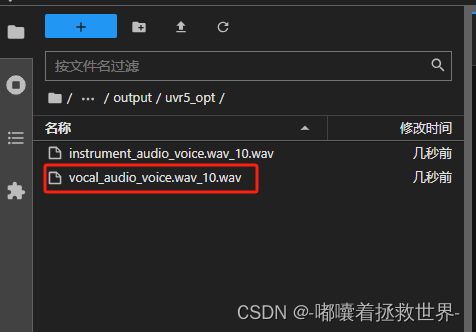
转换好后,记得关闭UVR5-WebUI,这样可释放一些内存。

2.4、语音切割
第一步,上传刚刚分离好的音频文件,填写好音频输入文件路径,这里跟着我填写input就可以了,点击开启语音切割。

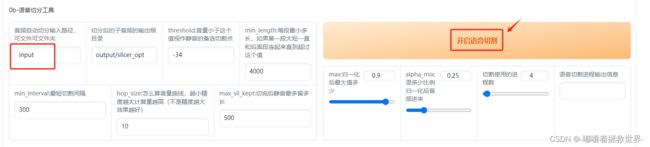
接着进行开启离线批量ASR,填写好输出文件夹的路径,然后点击左边的“开启离线批量ASR”按钮。

然后填写好打标数据文件路径,点击开启打标WebUI,返回到AutoDL终端操作界面,查看命令行输出,点击下方链接即可进入到打标数据界面。

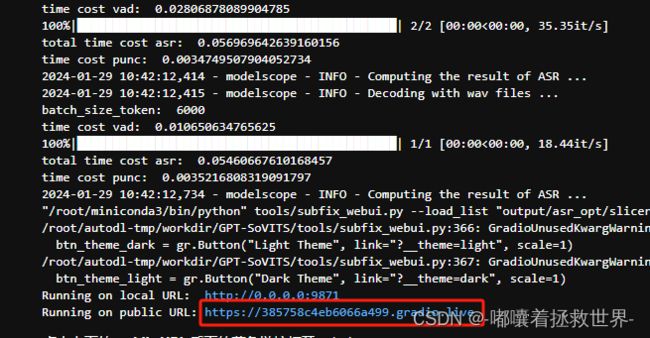
2.5、打标训练数据
点击播放▶️按钮,试听一下对应文本是否正确,如果不正确进行文本的修改,这一页整理好数据后,点击“Save File”和“Submit Text”这两个按钮,接着点击“Next Index”下一页,重复以上的步骤进行校对。
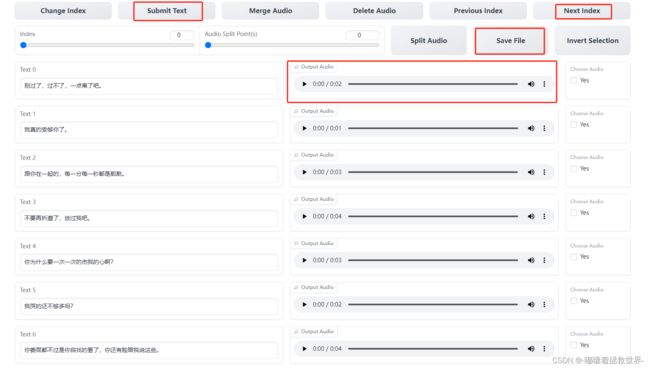
全部校对完毕后,返回WebUI界面,关闭打标WebUI

2.6、数据集预处理
点击“1-GPT-SoVITS-TTS”,来到训练操作界面,更改实验名字,可随意命名,然后填写好文本标注文件和训练集音频文件路径,这里跟我的一模一样就可以了。
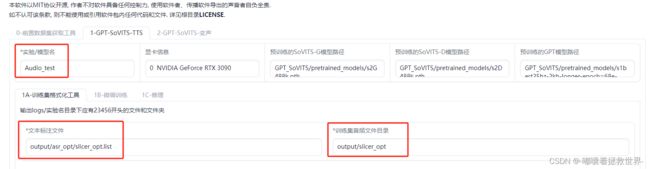
接着分别点击这四个按钮即可。

2.7、训练音频数据
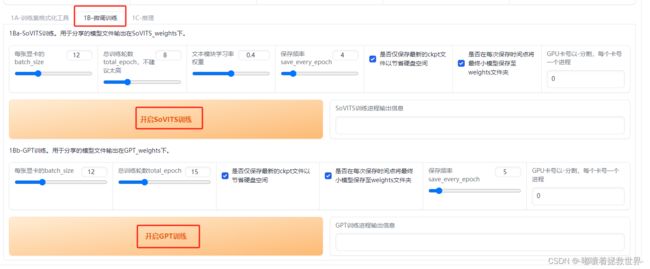
然后来到了微调训练数据这个界面,保持默认参数不变,也可以自行调整参数的,点击开启SOVITS训练和开启GPT训练。
2.8、推理模型
来到1C-推理,首先点击刷新模型路径,才能出现刚刚训练好的模型。
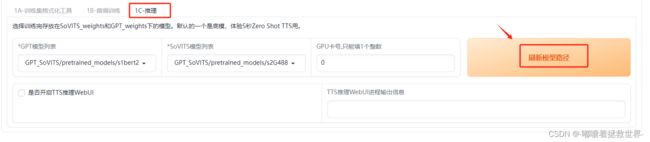
接下来选择刚刚训练好的模型文件,然后开启TTS推理WebUI

查看AutoDL的终端界面,找到最后一行的网页链接,点击这个链接即可到TTS推理的界面。
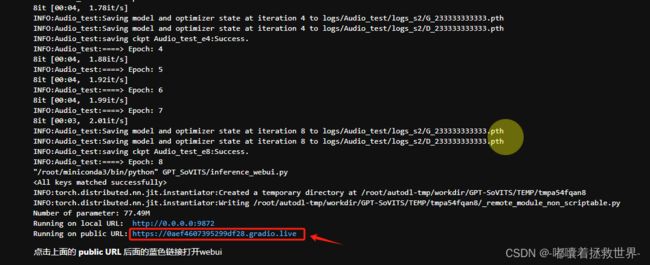
首先上传一段几秒的参考音频,填写参考音频的所输出的语音文本,然后再填写需要合成的文本,点击合成语音,一会儿就会出现了输出的语音音频文件了,点击试听,效果确实很惊艳!!!

三、总结
GPT-SoVITS是一款支持多语言的先进技术,融合了声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)以及文本标注等多种辅助工具。令人印象深刻的是,它仅需一分钟的训练数据,就能对模型进行微调,显著提升语音的相似度和真实感。整体而言,GPT-SoVITS提供了一种极为出色的体验。期待其在未来的应用范围能不断扩大,而且在更新迭代过程中能实现更加完善和优化。