文件上传之秒传功能
秒传是一种文件的传输机制,用于在文件已经存在于目标服务器上时,通过校验文件的唯一标识,实现快速而无需从新上传整个文件,它解决了重复上传相同文件的问题,提高了文件传输的效率和节省了带宽资源。
技术阐述:
那么,我们需要对文件上传的需求原理实现方式以及优势与不足进行对应的理解。
需求:避免重复上传操作是一个非常重要的问题,当用户需要上传一个以及存在于服务器上的文件时,需要去避免重复上传,因为可以节省时间和资源带宽。这样的目的是可以进行更高效率的提升,减少用户的等待时间。并且秒传功能减少了不必要的网络传输操作,节省了带宽的资源,提升了整体的网络性能。
实现原理:秒传的实现原理是基于文件的唯一标识进行校验,文件的唯一标识通常使用文件的哈希值,例如MD5或SHA来进行展示。在文件上传之前,客户端先进行文件的哈希值计算,然后将其发送到服务器端。而服务器端接收到哈希值以后,检查是否以及存在该哈希值对应的文件内容,如果已经存在,则不需要进行文件的上传操作,可以直接中断上传,实现秒传的功能。如果不存在,我们则需要进行文件的上传处理。
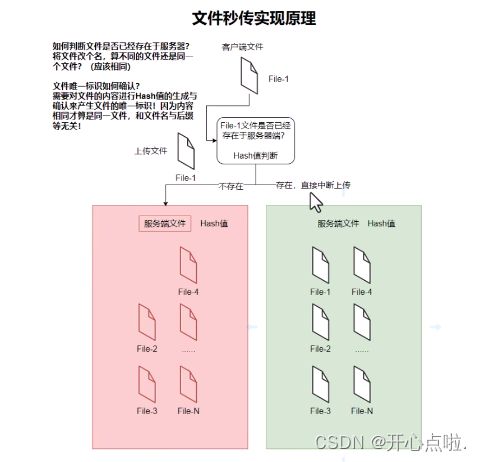
如何去实现秒传操作,首先需要去注意几个核心的关键技术点:
(1)哈希值的计算:客户端需要先计算出文件的哈希值,那么我们需要去思考,是对什么内容进行哈希值的计算。是对文件名还是文件后缀。如果说文件名修改以后,这个文件是否还是我们同一个需要上传的文件。所有,哈希值的计算是根据文件的内容进行计算处理,因为即便对文件名进行了修改,但是文件内容本质没有发生任何的改变,所以文件还应该是相同的文件。所以哈希值的计算是秒传实现原理的根本。
那么我们通常使用的是MD5或SHA等算法来进行哈希值的计算,这是因为它会产生一个唯一标识。那么客户端将这个哈希值发送到服务器端以后,服务器端则进行存储与检测操作。
事实上,实现秒传功能是为了避免上传相同的文件节省传输的时间和资源。不光是客户端的时间资源进行了节省,更重要的是服务器端的时间和资源也得到了最大的利用。其实是可以给服务器进行了费用的节省。
那么用户的友好性,体验也会得以更好的提升。
当然,在秒传的过程当中,还会存在一些不足点,因为唯一标识可能会产生冲突的问题。不同的文件得到的哈希值是相同的,可能会导致唯一标识产生冲突。需要额外的校验机制来去解决这个问题。当然,这种情况应该是发生几率是非常少的,但是不能够进行排除。
而且服务器端也必须要支持秒传的功能,因为,服务器端和客户端的哈希值进行校验的话,是对应的一个关系。
总而言之,秒传是一种通过校验文件唯一标识实现快速传输已经存在文件而无需重新上传的机制。它提高了文件的传输效率,节省了时间和带宽,提供了更好的用户体验,所以,我们需要去尝试进行文件秒传的功能实现。
如何实现:
文件上传之大文件分块上传-CSDN博客
大文件分块上传进度控制处理-CSDN博客
大文件分块上传之断点续传-CSDN博客
在以上三个博客的基础上进行实现的
第一步:定义一个计算哈希值函数
需要引入第三方库
const computeFileHash = (file) => { //传入文件内容 对文件内容进行哈希值的计算
return new Promise((resolve, reject) => {
const chunkSize = 1 * 1024 * 1024; // 1MB
const fileReader = new FileReader() // 创建一个FileReader对象,用于读取文件内容
const spark = new SparkMD5.ArrayBuffer(); // 创建一个SparkMD5对象,用于计算文件哈希值
let currentChunk = 0; // 当前处理的分片索引
// 文件读取成功时的回调函数
fileReader.onload = function(e) {
spark.append(e.target.result); //将文件块的数据添加到哈希计算中
currentChunk++;
if(currentChunk < totalChunks){
loadNextChunk(); //继续加载下一个文件块
}else{
const hash = spark.end(); //完成哈希值计算
resolve(hash); //返回计算得到的哈希值
}
};
// 文件读取失败时的回调函数
fileReader.onerror = function (e) {
reject(e.target.error); // 返回读取错误
};
// 加载下一个文件块
function loadNextChunk() {
const start = currentChunk * chunkSize; //当前文件块的起始位置
const end = Math.min(start + chunkSize, file.size); //当前文件块的结束位置
const chunk = file.slice(start, end); // 提取当前文件块的数据
fileReader.readAsArrayBuffer(chunk); // 以ArrayBuffer形式读取文件块的数据
}
const totalChunks = Math.ceil(file.size / chunkSize); // 总的文件块数量
loadNextChunk(); // 开始加载第一个块
})
}第二步:如何使用这个方法
在while循环前调用这个方法,将文件的哈希值传递到服务器
// 计算文件哈希值
const fileHash = await computeFileHash(file);
// 检查服务器是否已存在相同的文件
try{
const response = await axios.head(
'http://localhost:3000/check-file?filehash=' + fileHash
);
if(response.status === 200){
// 文件已存在,直接完成上传
console.log('文件已存在,秒传成功');
return;
}
}catch(error){
console.log('检查文件失败',error)
}第三步:在文件合并的时候去确认这个文件信息是否应该包含fileHash值。
这样可以确认文件是否已经在服务器中存在
try{
const postData = { filename:file.name,totalChunks:totalChunks,fileHash:fileHash }; //构造合并请求的数据
await http.post('http://localhost:3000/merge', postData,{
headers: {
'Content-Type': 'application/json'
}
}); //发送合并请求
}catch(error){
console.error(error);
}以上则是客户端的代码。
第四步:在服务器端定义一个存放哈希值的对象
// 存储文件哈希值的对象
const fileHashes = {};第五步:在merge接口中进行一些修改 用来存储哈希值

第六步:检查文件是否已存在
前端check-file接口
// 检查文件是否已存在
app.head('/check-file',(req,res) => {
const fileHash = req.query.filehash;
console.log(fileHash,fileHashes);
if(fileHashes[fileHash]){
res.sendStatus(200); //文件已存在
}else{
res.sendStatus(404); //文件不存在
}
})执行代码:
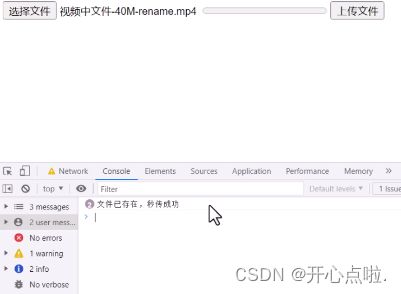
秒传功能就已经实现了,无论是我们修改文件名称,也会进行一个秒传的效果,因为我们是对块进行哈希值的一个计算。
那么以上就是秒传内容,希望对您有所帮助。