基于paddleclas实现人类血细胞分类
基于paddleclas的人类血细胞分类
AI达人特训营第二期
一、项目介绍
智慧医疗是在医疗行业融入人工智能等高科技技术使得医疗服务走向真正的智能化,通过对人类血细胞进行无标定血液疾病诊断和质量监测,是未来的智慧医疗和护理点应用非常重要的一个部分。其中对白细胞进行种类分辨是智慧医疗的一个重要方向
本项目用来检验血细胞图像的分类,对于检测和分类血细胞亚型的自动化方法具有重要的医学应用。血液疾病的诊断通常涉及识别和表征患者血液样本,医疗图像分类识别需要大量的人力和时间成本,因此对血细胞进行分类具有重要的医学应用。血白细胞分类是在进行血液显微镜检查时,将白细胞分类计数的一种医学检测法。通过自动化分类检测,我们可以提高白细胞分类精度并降低检测成本,有利于更加精确的分析血液样本的各项指标,从而减少医疗的人力物力并且为病人提供更加精准的检测报告。
二、paddleclas介绍
飞桨图像识别套件PaddleClas是飞桨为工业界和学术界所准备的一个图像识别和图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。PaddleClas提供了基于图像分类的模型训练、评估、预测、部署全流程的服务,方便大家更加高效地学习图像分类。
本项目会从零开始带领大家使用paddleclas套件

- paddleclas中训练配置,后续yml文件配置时会详解
| 参数名称 | 具体含义 | 默认值 |
| -------- | -------- | -------- |
| checkpoints | 断点模型路径,用于恢复训练 | null |
pretrained_model|预训练模型路径|null|
output_dir|保存模型路径|“./output/” |
save_interval|每隔多少个epoch保存模型|1
eval_during_train|是否在训练时进行评估|True|
eval_interval|每隔多少个epoch进行模型评估|1|
epochs|训练总epoch数|无|
print_batch_step|每隔多少个mini-batch打印输出|10|
use_visualdl|是否是用visualdl可视化训练过程|False|
image_shape|图片大小|[3,224,224]|
save_inference_dir|inference模型的保存路径|“./inference”|
eval_mode|eval的模式|“classification”|
参考文档:https://github.com/PaddlePaddle/PaddleClas/blob/release/2.2/docs/en/tutorials/config_description_en.md
-
这里是30分钟玩转paddleclas,可以跟着学习如何对paddle进行初级使用和进阶用法https://paddleclas.readthedocs.io/zh_CN/latest/tutorials/quick_start.html
-
这是paddleclas套件的网站可以前去查看
https://gitee.com/paddlepaddle/PaddleClas
#导入paddleclas
!git clone https://gitee.com/paddlepaddle/PaddleClas.git -b release/2.2
fatal: 目标路径 'PaddleClas' 已经存在,并且不是一个空目录。
三、数据集介绍
3.1数据集介绍
该数据集包含12,500个血细胞增强图像,并带有伴随的细胞类型标签。每种4种不同的细胞类型大约有3,000张图像,这些图像分为4个不同的文件夹(根据细胞类型)。细胞类型是嗜酸性粒细胞,淋巴细胞,单核细胞和嗜中性粒细胞。文件夹“ dataset-master”包含410个带有子类型签和边界框(JPEG + XML)的血细胞图像,而文件夹“ dataset2-master”的TRAIN文件中每个种类细胞包含大约2500个增强图像。 本项目主要用到了“dataset2-master”中的TRAIN文件夹里的数据集
这是TRAIN中所含的文件,包括四种文件,各代表一种白细胞的类别

3.2数据集解压
#解压数据集
! unzip -q data/data106627/血细胞图像.zip -d data/mydata
3.3数据集查看
#利用树关系查看数据集
! tree data/mydata -d
#我们使用的是dataset2-master中的TRAIN文件夹中的数据
data/mydata
├── dataset2-master
│ └── dataset2-master
│ └── images
│ ├── TEST
│ │ ├── EOSINOPHIL
│ │ ├── LYMPHOCYTE
│ │ ├── MONOCYTE
│ │ └── NEUTROPHIL
│ ├── TEST_SIMPLE
│ │ ├── EOSINOPHIL
│ │ ├── LYMPHOCYTE
│ │ ├── MONOCYTE
│ │ └── NEUTROPHIL
│ └── TRAIN
│ ├── EOSINOPHIL
│ ├── LYMPHOCYTE
│ ├── MONOCYTE
│ └── NEUTROPHIL
└── dataset-master
└── dataset-master
├── Annotations
└── JPEGImages
22 directories
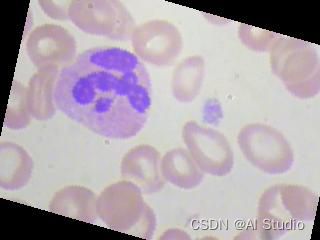
#可以根据下面代码分别查看TRAIN数据集中四种种类的图像
from PIL import Image
Image.open('/home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN/EOSINOPHIL/_0_3072.jpeg')
#Image.open('/home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN/LYMPHOCYTE/_0_2065.jpeg')
#Image.open('/home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN/MONOCYTE/_0_1173.jpeg')
#Image.open('/home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN/NEUTROPHIL/_0_9495.jpeg')
四、导入相关库
#导入可能用到的库
from sklearn.utils import shuffle
import os
import pandas as pd
import numpy as np
from PIL import Image
import paddle
import random
import glob
import tqdm
import cv2
#消除一些没必要的警告
import warnings
warnings.filterwarnings("ignore")
五、数据集的处理
5.1计算图像的均值和方差
def get_mean_std(image_path_list):
#打印出所有图片的数量
print('Total images size:', len(image_path_list))
# 结果向量的初始化,三个维度,和图像一样
max_val, min_val = np.zeros(3), np.ones(3) * 255
mean, std = np.zeros(3), np.zeros(3)
#利用tqdm模块,可以加载进度条
for image_path in tqdm.tqdm(image_path_list):#tqdm用于加载进度条
#读取TRAIN中的每一张图片
image = cv2.imread(image_path)
#分别处理三通道
for c in range(3):
# 计算每个通道的均值和方差
mean[c] += image[:, :, c].mean()
std[c] += image[:, :, c].std()
max_val[c] = max(max_val[c], image[:, :, c].max())
min_val[c] = min(min_val[c], image[:, :, c].min())
# 所有图像的均值和方差
mean /= len(image_path_list)
std /= len(image_path_list)
#归一化,将值滑到0-1之间
mean /= max_val - min_val
std /= max_val - min_val
# print(max_val - min_val)
return mean, std
#列表加载储存所有的图片的路径
image_path_list = []
#TRAIN中所有的文件
image_path_list.extend(glob.glob('/home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN/*/*.jpeg'))#glob.glob用来返回改路径下所有符合格式要求的所有文件
#获得图像的均值和方差
mean, std = get_mean_std(image_path_list)
print('mean:', mean)
print('std:', std)
Total images size: 9957
100%|██████████| 9957/9957 [00:26<00:00, 372.43it/s]
mean: [0.66049439 0.64131681 0.67861641]
std: [0.25679078 0.25947123 0.25992564]
5.2处理所有用到的图片和txt文件
# 官方的paddleclas中,要生成train.txt和test.txt两个文本来储存照片路径和分类
# 我们将TRAIN图片按照经典的划分方式0.8:0.2训练集和测试集
# train_list.txt(训练集)
# val_list.txt(验证集)
# 先把路径搞定 比如:/home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN/MONOCYTE/_10_8335.jpeg 2
# /home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN/MONOCYTE/_6_6086.jpeg 2
#图片所在的路径
dirpath = "/home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN/"
# 先得到总的txt后续再进行划分,因为要划分出验证集,所以要先打乱,因为原本是有序的
def get_all_txt():
all_list = []
i = 0
for root,dirs,files in os.walk(dirpath): # 分别代表根目录、文件夹、文件
for file in files:
i = i + 1
# 文件中每行格式: 图像相对路径 图像的label_id(注意:中间有空格)。
# /home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN/MONOCYTE/_10_8335.jpeg 2
# /home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN/MONOCYTE/_6_6086.jpeg 2\n
#4种图片的分类
if("EOSINOPHIL" in root):
all_list.append(os.path.join(root,file)+" 0\n")
if("LYMPHOCYTE" in root):
all_list.append(os.path.join(root,file)+" 1\n")
if("MONOCYTE" in root):
all_list.append(os.path.join(root,file)+" 2\n")
if("NEUTROPHIL" in root):
all_list.append(os.path.join(root,file)+" 3\n")
#将所有的图片写入txt文件中
allstr = ''.join(all_list)
f = open('all_list.txt','w',encoding='utf-8')
f.write(allstr)
return all_list , i
all_list,all_lenth = get_all_txt()
print(all_lenth)
#将图片乱序
random.shuffle(all_list)
9957
5.3划分训练集和测试集
#按照0.8:0.2划分
train_size = int(len(all_list) * 0.8)
train_list = all_list[:train_size]
val_list = all_list[train_size:]
print(len(train_list))
print(len(val_list))
7965
1992
# 运行cell,生成txt
train_txt = ''.join(train_list)
f_train = open('train_list.txt','w',encoding='utf-8')
f_train.write(train_txt)
f_train.close()
print("train_list.txt 生成成功!")
train_list.txt 生成成功!
# 运行cell,生成txt
val_txt = ''.join(val_list)
f_val = open('val_list.txt','w',encoding='utf-8')
f_val.write(val_txt)
f_val.close()
print("val_list.txt 生成成功!")
val_list.txt 生成成功!
成成功!")
val_list.txt 生成成功!
* 计算出图像的均值和方差可以用于后续yml文件的配置中去,后续将会提到
## 六、开启训练
### 6.1 设置GPU
```python
#设置GPU装置为1个
!export CUDA_VISIBLE_DEVICES=0
6.2详解配置yaml文件及其相关参数
以/home/aistudio/PaddleClas/ppcls/configs/quick_start/new_user/ShuffleNetV2_x0_25.yaml为例,讲解一下如何具体配置yml文件
-
修改epoch可以修改训练的轮数,同时可以修改output和infer的路径等
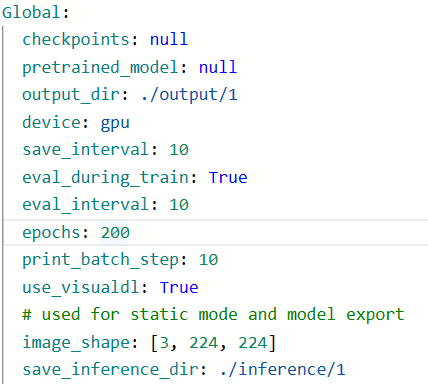
-
可以修改优化器、学习率、损失函数等,具体如何修改可查看paddleclas在Gitee和GitHub中的套件
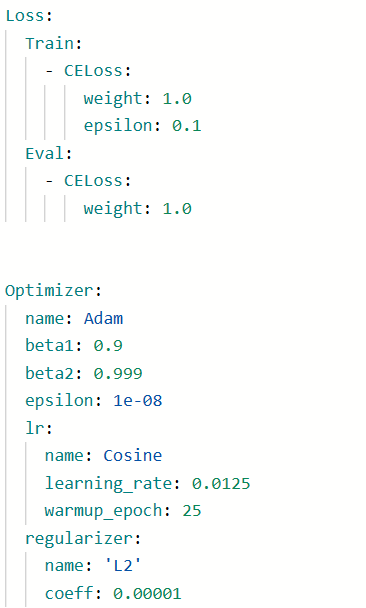
-
对训练和预测修改
- 要修改你所要训练的图片的路径和标签的路径
- 可以在此处进行图像增强的措施,具体如何使用可查看paddleclas在Gitee和GitHub中的套件
- 可以修改均值和方差,可以采用上面我们已经训练出来的均值与方差
- 下面为Train的修改,Eval修改与Train同理
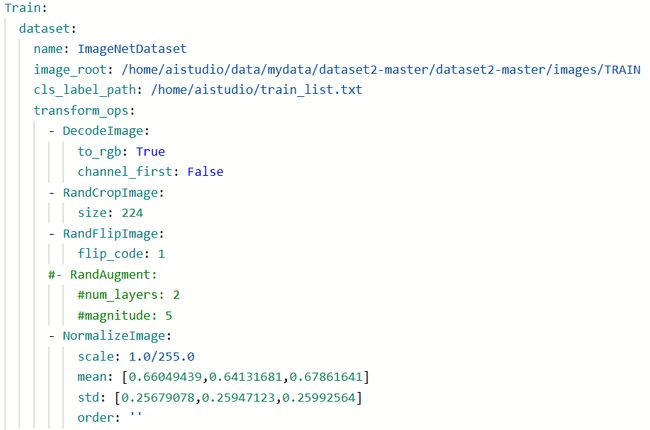
6.3 可以直接使用的配置好的yml文件
- 本人配置的ymal文件,可直接使用
路径:/home/aistudio/PaddleClas/ppcls/configs/quick_start/new_user/ShuffleNetV2_x0_25.yaml
# global configs
Global:
checkpoints: null
pretrained_model: null
output_dir: ./output/
device: gpu
save_interval: 10
eval_during_train: True
eval_interval: 10
epochs: 200
print_batch_step: 10
use_visualdl: True
# used for static mode and model export
image_shape: [3, 224, 224]
save_inference_dir: ./inference/
# model architecture
Arch:
name: ShuffleNetV2_x0_25
class_num: 4
# loss function config for traing/eval process
Loss:
Train:
- CELoss:
weight: 1.0
epsilon: 0.1
Eval:
- CELoss:
weight: 1.0
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
epsilon: 1e-08
lr:
name: Cosine
learning_rate: 0.0125
warmup_epoch: 25
regularizer:
name: 'L2'
coeff: 0.00001
# data loader for train and eval
DataLoader:
Train:
dataset:
name: ImageNetDataset
image_root: /home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN
cls_label_path: /home/aistudio/train_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 224
- RandFlipImage:
flip_code: 1
#- RandAugment:
#num_layers: 2
#magnitude: 5
- NormalizeImage:
scale: 1.0/255.0
mean: [0.66049439,0.64131681,0.67861641]
std: [0.25679078,0.25947123,0.25992564]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 256
drop_last: False
shuffle: True
loader:
num_workers: 1
use_shared_memory: True
Eval:
dataset:
name: ImageNetDataset
image_root: /home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN
cls_label_path: /home/aistudio/val_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.66049439,0.64131681,0.67861641]
std: [0.25679078,0.25947123,0.25992564]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 64
drop_last: False
shuffle: False
loader:
num_workers: 1
use_shared_memory: True
Infer:
infer_imgs: /home/aistudio/BloodImage_00001.jpg
batch_size: 10
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.66049439 0.64131681 0.67861641]
std: [0.25679078 0.25947123 0.25992564]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
topk: 4
Metric:
Train:
- TopkAcc:
topk: [1, 4]
Eval:
- TopkAcc:
topk: [1, 4]
**
- 本人也修改了/home/aistudio/PaddleClas/ppcls/configs/ImageNet/ResNet/ResNet50_vd.yaml,可用作用来帮助,可二选其一用来进行配置yaml文件
# global configs
Global:
checkpoints: null
pretrained_model: null
output_dir: ./output/
device: gpu
save_interval: 1
eval_during_train: True
eval_interval: 1
epochs: 200
print_batch_step: 20
use_visualdl: True
# used for static mode and model export
image_shape: [3, 224, 224]
save_inference_dir: ./inference
# model architecture
Arch:
name: ResNet50_vd
class_num: 4
# loss function config for traing/eval process
Loss:
Train:
- MixCELoss:
weight: 1.0
epsilon: 0.1
Eval:
- CELoss:
weight: 1.0
Optimizer:
name: Momentum
momentum: 0.9
lr:
name: Cosine
learning_rate: 0.1
regularizer:
name: 'L2'
coeff: 0.00007
# data loader for train and eval
DataLoader:
Train:
dataset:
name: ImageNetDataset
image_root: /home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN
cls_label_path: /home/aistudio/train_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 224
- RandFlipImage:
flip_code: 1
- NormalizeImage:
scale: 1.0/255.0
mean: [0.66049439,0.64131681,0.67861641]
std: [0.25679078,0.25947123,0.25992564]
order: ''
batch_transform_ops:
- MixupOperator:
alpha: 0.2
sampler:
name: DistributedBatchSampler
batch_size: 256
drop_last: False
shuffle: True
loader:
num_workers: 1
use_shared_memory: True
Eval:
dataset:
name: ImageNetDataset
image_root: /home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TRAIN
cls_label_path: /home/aistudio/val_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.66049439,0.64131681,0.67861641]
std: [0.25679078,0.25947123,0.25992564]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 64
drop_last: False
shuffle: False
loader:
num_workers: 1
use_shared_memory: True
Infer:
infer_imgs: /home/aistudio/data/mydata/dataset2-master/dataset2-master/images/TEST/EOSINOPHIL/_0_3083.jpeg
batch_size: 10
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
topk: 4
Metric:
Train:
Eval:
- TopkAcc:
topk: [1, 4]
6.4 开启训练
#训练,配置yaml文件
!python /home/aistudio/PaddleClas/tools/train.py \
-c /home/aistudio/PaddleClas/ppcls/configs/quick_start/new_user/ShuffleNetV2_x0_25.yaml
训练过程中指令解释:
- –c:指定配置文件。
- –eval:边训练边验证。
- –use_vdl True:使用VisualDL记录数据,进而在VisualDL面板中显示。
- !python + 某路径下的python文件:执行某python文件。
训练中出现的问题解决方法: - 断次问题
如果你的模型训练不小心断在了某个轮次,没训练完,可以使用 -r output/模型的yml文件/停在的轮次数(如果你一共要训练200轮次,却停在第20轮次,用的是ppyolo_r18vd_coco模型,你可以使用 -r output/ShuffleNetV2_x0_25/20继续进行训练)。 - 指令多的问题
只要后面有指令,可以在每个指令最末尾后加\(\前不能加空格,最后一个指令末尾不用加\)。
6.5 过程可视化
yaml文件中选择:use_visualdl: True
点击右侧可视化
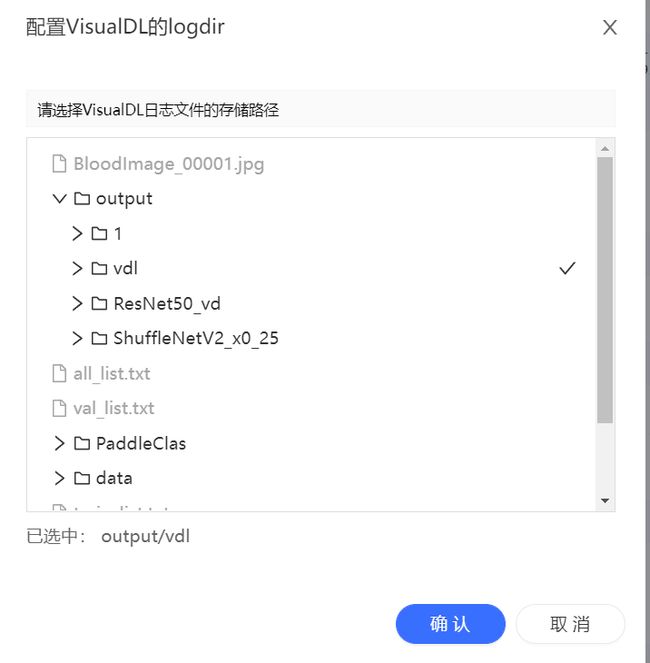
插入output文件中的vdl文件
点击启动VisualDL服务,进入即可
七、预测
#预测
!python /home/aistudio/PaddleClas/tools/infer.py \
-c /home/aistudio/PaddleClas/ppcls/configs/quick_start/new_user/ShuffleNetV2_x0_25.yaml \
-o Infer.infer_imgs=/home/aistudio/data/mydata/dataset-master/dataset-master/JPEGImages \
-o Global.pretrained_model=/home/aistudio/output/ShuffleNetV2_x0_25/best_model
-o:设置或更改配置文件里的参数内容
–infer_dir:用于预测的图片文件夹路径
–output_dir:预测后结果或导出模型保存路径
将你所想要预测的图像放进一个文件夹中,利用-o Infer.infer_imgs进行预测即可
–draw_threshold:可视化时分数阈值
–save_txt:是否在文件夹下将图片的预测结果保存到文本文件中
八、模型导出
#导出模型
!python3 /home/aistudio/PaddleClas/tools/export_model.py \
-c /home/aistudio/PaddleClas/ppcls/configs/quick_start/new_user/ShuffleNetV2_x0_25.yaml \
-o Global.pretrained_model=/home/aistudio/output/ShuffleNetV2_x0_25/best_model
相关信息
导师:张一乔 学员:杜海诚
参考:基于PaddleClas2.2的从零到落地安卓部署的奥特曼分类实战
此文章为搬运
原项目链接