Dataloader加载数据集
文章目录
- 回顾
- Epoch, Batch-Size, Iterations
- 糖尿病 Dataset 构建
-
- 数据集实现代码
- DataLoader使用
- 糖尿病分类预测代码
- torchvision.datasets
-
- 练习
- 练习
回顾
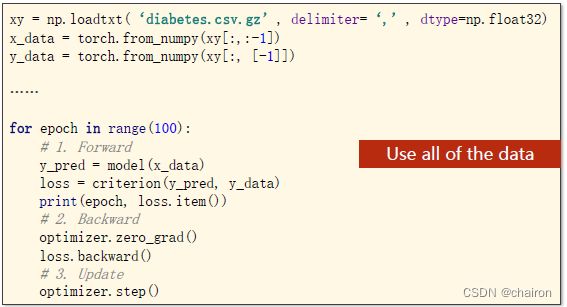
上节课使用全部数据进行训练。

Epoch, Batch-Size, Iterations
- epoch:训练的总轮次,指所有的训练样本都进行一次训练。
- batch-size:在一次训练中的训练样本数目。
- iteration:1个epoch需要进行的训练次数。
- epoch=batch-size*iteration

- shuffle:打乱数据
- 先对数据进行乱序,然后进行分组为可迭代的loader,每一次迭代就是一个batch。

糖尿病 Dataset 构建
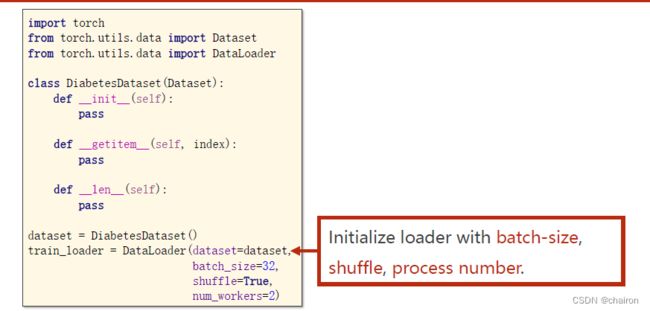
- 需要导入Dataset、DataLoader两个类,Dataset是个抽象类不能实例化,只能被继承。
- 定义了一个数据集继承Dataset类,需要重写__init__、getitem、__len__三个魔法函数,分布是进行初始化,获取索引、获取列表长度的作用。
- 加载数据集需要用到DataLoader,number workers是指加载数据集时是否使用多线程(1是单线程)
- 另外,如果数据量比较小我们可以直接加载数据到内存;但是如果数据量比较大,比如说数据是图片,那么我们会新建一个txt文档保存数据集的路径、文件名、标签等信息。dataloader从txt文本中加载数据(YOLO系列)。
注意!!!由于windows系统和Linux系统的差异,直接使用num_workers相关设置会报错,RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase.最好加一个if语句:if __name__ == '__main__':。

数据集实现代码
# prepare dataset
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)#导入数据集
self.len = xy.shape[0] # shape(行,列)shape[0]:获取行数
self.x_data = torch.from_numpy(xy[:, :-1])#获取前8列数据x
self.y_data = torch.from_numpy(xy[:, [-1]])#获取最后一列数据y
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]#返回索引
def __len__(self):
return self.len#返回数据长度
dataset = DiabetesDataset('diabetes.csv')#读取数据
#加载数据
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=4) # num_workers 多线程
DataLoader使用
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0): # train_loader 是先shuffle后mini_batch
inputs, labels = data
#每次获取一个(x[i],y[i]),然后拼接成一个矩阵X,Y,DataLoader会自动把数据转化为Tensor
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
糖尿病分类预测代码
同样是四步走:
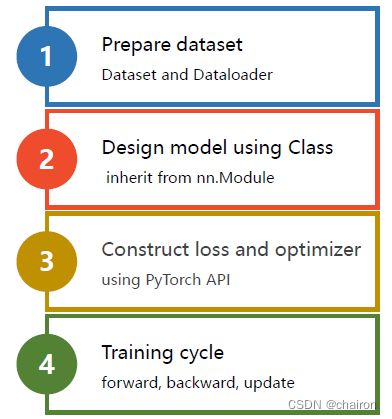
请先尝试自己写!(其实就是第一步、第四步有所改动)
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# prepare dataset
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)#导入数据集
self.len = xy.shape[0] # shape(行,列)shape[0]:获取行数
self.x_data = torch.from_numpy(xy[:, :-1])#获取前8列数据x
self.y_data = torch.from_numpy(xy[:, [-1]])#获取最后一列数据y
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]#返回索引
def __len__(self):
return self.len#返回数据长度
dataset = DiabetesDataset('diabetes.csv')#读取数据
#加载数据
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=4) # num_workers 多线程
# design model using class
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
# construct loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# training cycle forward, backward, update
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0): # train_loader 是先shuffle后mini_batch
inputs, labels = data
#每次获取一个(x[i],y[i]),然后拼接成一个矩阵X,Y,DataLoader会自动把数据转化为Tensor
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
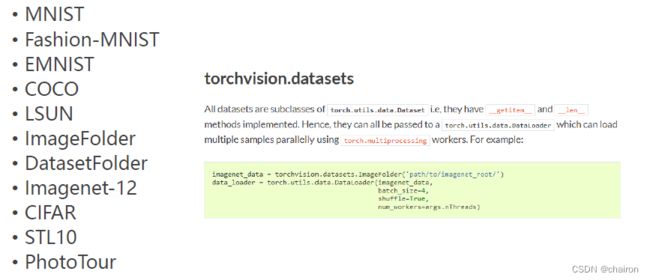
torchvision.datasets
torchvision.datasets提供了许多数据集。
练习
请使用MNIST数据集构建一个线性模型分类器
MNIST数据集的使用
- 加载数据集时,transform=transforms.ToTensor():将数据转化为Tensor。
- download=True:路径没有数据集时会自动下载。
- 训练时,DataLoader:shuffle=True:乱序;测试时不需要设置。
- inputs,target:读取数据集中的X、Y。

练习
kaggle是一个数据竞赛网站,提供了很多数据集和解决方案,可以在上面提交代码。
- 泰坦尼克号数据集地址:https://www.kaggle.com/c/titanic/data
- 请使用DataKLoader构建一个泰坦尼克号分类器。
- 训练目标:乘客是否存活(Survived 为y,其余特征列可以有所选择作为x)
- 做好了可以在网站上提交结果,查看评分。