大数据 - Spark系列《一》- 分区 partition数目设置详解
目录
3.2.1 分区过程
3.2.2 SplitSize计算和分区个数计算
3.2.3 Partition的数目设置
1. 对于数据读入阶段,输入文件被划分为多少个InputSplit就会需要多少初始task.
2. 对于转换算子产生的RDD的分区数
3. repartition和coalesce操作会聚合成指定分区数。
3.2.4 groupBy不一定会Shuffle
3.2.1 分区过程
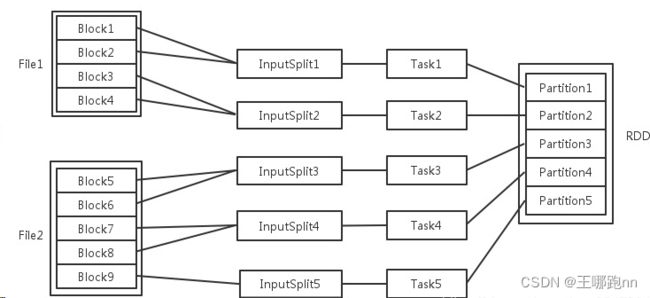
每一个过程的任务数,对应一个InputSplit,Paritition 输入可能以多个文件的形式存储在HDFS上面,,每个File都包含了很多块(128切分),称为block。
当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,按照SplitSize切成一个个输入分片。随后将为这些输入分片生成具体的task. InputSplit与Task是一一对应的关系。
注意:InputSplit不能跨越文件。
随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
-
每个节点可以起一个或多个Executor.
-
每个Executor由若干core组成,每个Executor的每个core一次只能执行一个task.
-
每个task执行的结果就就是生成了目标rdd的一个partition.
注意:这里的core是虚拟的core而不是机器的物理CPU核,可以理解为Executor的一个工作线程。Task被执行的并发度=Executor数目*每个Executor核数(=core总个数)
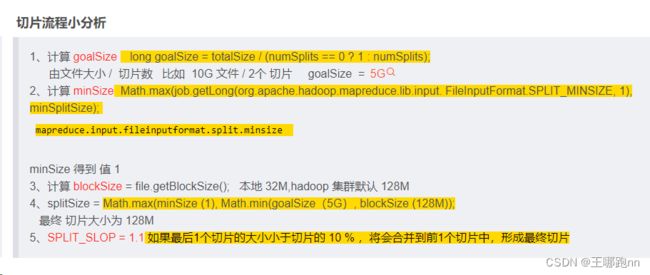
3.2.2 SplitSize计算和分区个数计算
3.2.3 Partition的数目设置
1. 对于数据读入阶段,输入文件被划分为多少个InputSplit就会需要多少初始task.
1)集合
-
默认所有资源(LocalSchedulerBackend: scheduler.conf.getInt("spark.default.parallelism", totalCores))
-
通过参数指定
2)文件
根据计算来的任务切片大小和输入路径下的文件大小 ,至少2并行度
3)数据库
指定的
2. 对于转换算子产生的RDD的分区数
-
原则上分区个数是不变的
-
有些算子可以调用的时候指定分区个数 distinct join groupBy groupByKey
-
特殊的算子 有特殊规定 union(和) join
-
spark.default.parallelism
-
分区数多的哪个rdd的分区数
-
val rdd3 = rdd1.intersection(rdd2) // 取大的
val rdd4 = rdd1.subtract(rdd2) // 前面的RDD分区数
println(rdd1.cartesian(rdd2).getNumPartitions) // 两个分区个数乘积注意: 可能产生Shuffle的算子可以指定分区个数的
//可能产生shuffle的操作
distinct(p) 减少
groupBy(_._1 , p) Shuffle
groupByKey( p) Shuffle
groupByKey(_+_, p) Shuffle
join( , p)3. repartition和coalesce操作会聚合成指定分区数。
println(rdd1.repartition(3).getNumPartitions) // 增加
println(rdd1.repartition(1).getNumPartitions) //减少
println(rdd1.coalesce(1, true).getNumPartitions) //减少
println(rdd1.coalesce(3, true).getNumPartitions) //增加
// 不允许Shuffle就不能增加分区
println(rdd1.coalesce(3, false).getNumPartitions) //增加失败
println(rdd1.coalesce(1, false).getNumPartitions) //减少 不会Shuffle3.2.4 groupBy不一定会Shuffle
Shuffle:上游一个分区的数据可能被下游所有分区引用

package com.doit.com.doit.day0128
import org.apache.spark.SparkContext.jarOfObject
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* @日期: 2024/1/29
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 我是技术大牛
* @Description:
*/
object Test03 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("doe").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List("a b c d e f g"), 2)
val rdd2: RDD[String] = rdd1.flatMap(_.split("\\s+"))
val wordOne = rdd2.map(line=>{
println("aaaaaa")
(line,1)
}) //2
//对数据使用HashPartitioner在分区 2
val rdd3 = wordOne.partitionBy(new HashPartitioner(3))
rdd3.mapPartitionsWithIndex((p,iter)=>{
iter.map(e=>(p,e))
}).foreach(println)
//底层默认是HashPartition分区 2
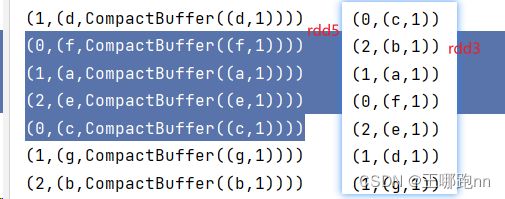
val rdd4: RDD[(String, Iterable[(String, Int)])] = rdd3.groupBy(_._1, 3)
val rdd5: RDD[(Int, (String, Iterable[(String, Int)]))] = rdd4.mapPartitionsWithIndex((p, iter) => {
iter.map(e => (p, e))
})
rdd5.foreach(println)
sc.stop()
}
}结果