如何使用YOLOv8训练自己的模型
本文介绍如何用YOLO8训练自己的模型,我们开门见山,直接步入正题。
前言:用yolo8在自己的数据集上训练模型首先需要配置好YOLO8的环境,如果不会配置YOLO8环境可以参考本人主页的另一篇文章
提醒:使用GPU训练会大幅度加快训练,有英伟达GPU的一定要配置GPU训练环境,没有英伟达显卡的只能采用CPU训练,但是一般不建议。 (GPU、CPU训练环境的配置具体见上面的文章链接)
第一章节:准备好数据集
配置好YOLO8环境之后,需要准备好YOLO格式的数据集(也称txt格式),该数据集可以通过数据集标注软件 labelme、labelimg对图片进行拉框标注得到。经过标注软件标注好的yolo数据集的格式通常为:
class_id x y w h
class_id: 类别的id编号
x: 目标的中心点x坐标(横向) /图片总宽度
y: 目标的中心的y坐标(纵向) /图片总高度
w:目标框的宽度/图片总宽度
h: 目标框的高度/图片总高度
下图为一张图片按照yolo格式进行标注的txt标注文件

在进行训练之前,还需要对数据集进行划分,一般是按照7:2:1的比例划分训练集(train)、验证集(val)、测试集(test) 或者按照8:2的比例划分训练集与验证集。
提醒:用YOLO8训练自己的模型必须至少要把数据集划分出训练集与验证集,可以不划分测试集,训练集与验证集不可或缺,否则不能数据集进行模型训练。我这里只划分训练集与验证集,并且训练集与验证集应该是下面的目录结构
train
├── images
└── labelsval
├── images
└── labels
下面以葡萄叶片病虫害数据集为例,给出训练集、验证集目录结构的参考示例



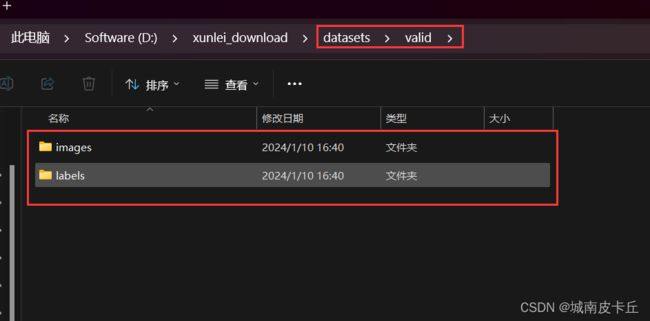
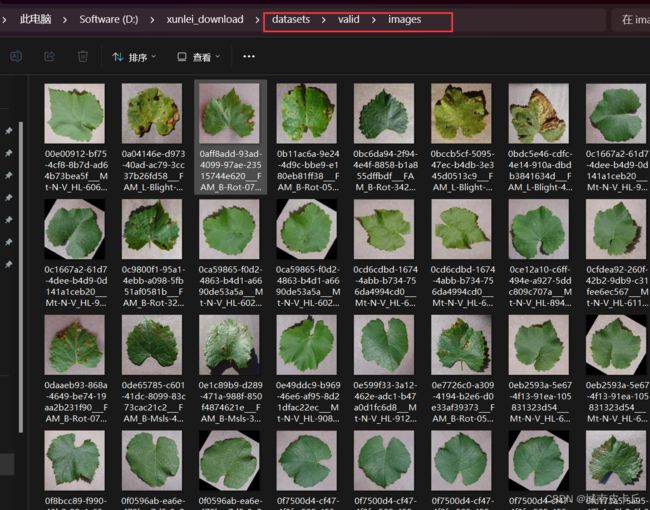

在训练之前,我们不仅要把数据集划分成训练集、验证集,还需要给出类别标签yaml文件,该文件是YOLO8在训练过程中所必须的。也就是说,一个完整的,可以直接用于模型训练的数据集应该具有以下目录结构:

data.yaml的内容如下图所示:
 其中train、val指定训练集与验证集的路径地址(最好写成绝对路径)
其中train、val指定训练集与验证集的路径地址(最好写成绝对路径)
nc代表该数据集有几个类别,我这里的葡萄叶片病虫害数据集有四个类别
names代表具体的类别名称。可以以数组的形式给出,但请注意类别名称需要以英文或数字呈现,不能含有任何特殊字符或者中文字符。
提醒:yaml文件是必须的,如果你拿到的数据集不含这个文件,那么你要按照上面的格式自己手动写了,书写时需要严格按照yaml文件的格式(冒号后面是有一个空格的)
第二章节:开始训练
搞深度学习,绝大部分都是在linux系统上进行炼丹的。考虑到有的读者可能对Linux不熟悉,本章节首先给出win系统训练教程,然后再给出linux系统训练步骤。
注意:在训练的过程中,有英伟达显卡的一定要用GPU训练,用CPU训练是特别缓慢的。
2.1 训练参数
训练方式有多种,可以通过py程序训练,也可以在命令行训练,我们这里以py程序训练为例:
无论是在win系统还是linux系统,训练的代码基本都是一致的,只有极个别参数会因为系统的不同出现差异。
from ultralytics import YOLO
# 这里有三种训练方式,三种任选其一
#第一种:根据yaml文件构建一个新模型进行训练,若对YOLO8网络进行了修改(比如添加了注意力机制)适合选用此种训练方式。但请注意这种训练方式是重头训练(一切参数都要自己训练),训练时间、资源消耗都是十分巨大的
model = YOLO('yolov8n.yaml') # build a new model from YAML
#第二种:加载一个预训练模型,在此基础之前上对参数进行调整。这种方式是深度学习界最最主流的方式。由于大部分参数已经训练好,我们仅需根据数据集对模型的部分参数进行微调,因此训练时间最短,计算资源消耗最小。
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
#第三种:根据yaml文件构建一个新模型,然后将预训练模型的参数转移到新模型中,然后进行训练,对YOLO8网络进行改进的适合选用此种训练方式,而且训练时间不至于过长
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
# Train the model
#data参数指定数据集yaml文件(我这里data.yaml与train、val文件夹同目录)
#epochs指定训练多少轮
#imgsz指定图片大小
results = model.train(data='data.yaml', epochs=100, imgsz=640)model.train()函数可以指定的训练参数有很多,如下表所示:
| Key |
Value |
Description |
| model |
None |
path to model file, i.e. yolov8n.pt, yolov8n.yaml |
| data |
None |
path to data file, i.e. coco128.yaml |
| epochs |
100 |
number of epochs to train for |
| time |
None |
number of hours to train for, overrides epochs if supplied |
| patience |
50 |
epochs to wait for no observable improvement for early stopping of training |
| batch |
16 |
number of images per batch (-1 for AutoBatch) |
| imgsz |
640 |
size of input images as integer |
| save |
True |
save train checkpoints and predict results |
| save_period |
-1 |
Save checkpoint every x epochs (disabled if < 1) |
| cache |
False |
True/ram, disk or False. Use cache for data loading |
| device |
None |
device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
| workers |
8 |
number of worker threads for data loading (per RANK if DDP) |
| project |
None |
project name |
| name |
None |
experiment name |
| exist_ok |
False |
whether to overwrite existing experiment |
| pretrained |
True |
(bool or str) whether to use a pretrained model (bool) or a model to load weights from (str) |
| optimizer |
'auto' |
optimizer to use, choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto] |
| verbose |
False |
whether to print verbose output |
| seed |
0 |
random seed for reproducibility |
| deterministic |
True |
whether to enable deterministic mode |
| single_cls |
False |
train multi-class data as single-class |
| rect |
False |
rectangular training with each batch collated for minimum padding |
| cos_lr |
False |
use cosine learning rate scheduler |
| close_mosaic |
10 |
(int) disable mosaic augmentation for final epochs (0 to disable) |
| resume |
False |
resume training from last checkpoint |
| amp |
True |
Automatic Mixed Precision (AMP) training, choices=[True, False] |
| fraction |
1.0 |
dataset fraction to train on (default is 1.0, all images in train set) |
| profile |
False |
profile ONNX and TensorRT speeds during training for loggers |
| freeze |
None |
(int or list, optional) freeze first n layers, or freeze list of layer indices during training |
| lr0 |
0.01 |
initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |
| lrf |
0.01 |
final learning rate (lr0 * lrf) |
| momentum |
0.937 |
SGD momentum/Adam beta1 |
| weight_decay |
0.0005 |
optimizer weight decay 5e-4 |
| warmup_epochs |
3.0 |
warmup epochs (fractions ok) |
| warmup_momentum |
0.8 |
warmup initial momentum |
| warmup_bias_lr |
0.1 |
warmup initial bias lr |
| box |
7.5 |
box loss gain |
| cls |
0.5 |
cls loss gain (scale with pixels) |
| dfl |
1.5 |
dfl loss gain |
| pose |
12.0 |
pose loss gain (pose-only) |
| kobj |
2.0 |
keypoint obj loss gain (pose-only) |
| label_smoothing |
0.0 |
label smoothing (fraction) |
| nbs |
64 |
nominal batch size |
| overlap_mask |
True |
masks should overlap during training (segment train only) |
| mask_ratio |
4 |
mask downsample ratio (segment train only) |
| dropout |
0.0 |
use dropout regularization (classify train only) |
| val |
True |
validate/test during training |
| plots |
False |
save plots and images during train/val |
下面指出几个比较重要的训练参数
1. epochs
epochs: 训练的轮数。这个参数确定了模型将会被训练多少次,每一轮都遍历整个训练数据集。训练的轮数越多,模型对数据的学习就越充分,但也增加了训练时间。
选取策略
默认是100轮数。但一般对于新数据集,我们还不知道这个数据集学习的难易程度,可以加大轮数,例如300,来找到更佳性能。
2. patience
patience: 早停的等待轮数。在训练过程中,如果在一定的轮数内没有观察到模型性能的明显提升,就会停止训练。这个参数确定了等待的轮数,如果超过该轮数仍没有改进,则停止训练。
早停
早停能减少过拟合。过拟合(overfitting)指的是只能拟合训练数据, 但不能很好地拟合不包含在训练数据中的其他数据的状态。
3. batch
batch: 每个批次中的图像数量。在训练过程中,数据被分成多个批次进行处理,每个批次包含一定数量的图像。这个参数确定了每个批次中包含的图像数量。特殊的是,如果设置为**-1**,则会自动调整批次大小,至你的显卡能容纳的最多图像数量。
选取策略
一般认为batch越大越好。因为我们的batch越大我们选择的这个batch中的图片更有可能代表整个数据集的分布,从而帮助模型学习。但batch越大占用的显卡显存空间越多,所以还是有上限的。
4. imgsz
imgsz: 输入图像的尺寸。这个参数确定了输入图像的大小。可以指定一个整数值表示图像的边长,也可以指定宽度和高度的组合。例如640表示图像的宽度和高度均为640像素。
选取策略
如果数据集中存在大量小对象,增大输入图像的尺寸imgsz可以使得这些小对象从高分辨率中受益,更好的被检测出。
5. device
device: 训练运行的设备。该参数指定了模型训练所使用的设备,例如使用 GPU 运行可以指定为 cuda device=0,或者使用多个 GPU 运行可以指定为 device=0,1,2,3,如果没有可用的 GPU,可以指定为 device=cpu 使用 CPU 进行训练。
6. workers
workers: 数据加载时的工作线程数。在数据加载过程中,可以使用多个线程并行地加载数据,以提高数据读取速度。这个参数确定了加载数据时使用的线程数,具体的最佳值取决于硬件和数据集的大小。
windows系统注意设置为0!!!windows系统下需设置为0,否则会报错!!!
RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase。
这是因为在linux系统中可以使用多个子进程加载数据,而在windows系统中不能。
7. optimizer
optimizer: 选择要使用的优化器。优化器是深度学习中用于调整模型参数以最小化损失函数的算法。可以选择不同的优化器,如 ‘SGD’、‘Adam’、‘AdamW’、‘RMSProp’,根据任务需求选择适合的优化器。
2.2 在win系统中进行训练
在开始训练之前,文件参考目录如下:
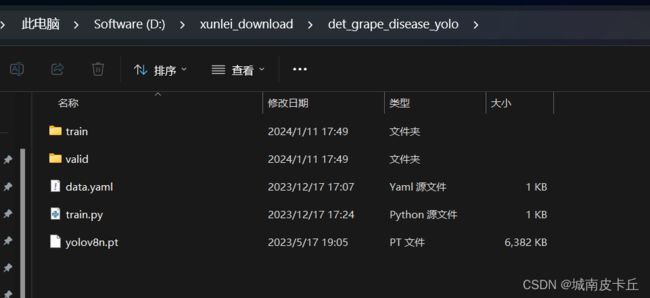
我这里直接加载yolovn8预训练模型进行训练,训练代码train.py内容如下:
from ultralytics import YOLO
model=YOLO('yolov8n.pt')
model.train(data='./data.yaml',imgsz=(640,640),workers=0,batch=32,epochs=60)需要注意的是,目录下最好提前下载好预训练模型(我这里是yolov8n.pt),如果没有提前下载好,运行train.py还是会ultralytics官网下载,由于外网的缘故,此时可能会出现网络问题。
紧接着,我们在anaconda中切换到提前已经配置好的yolo8环境,然后python命令运行train.py

之后,控制台窗口会有一系列的日志输出


此时,训练成功。经过一段时间等待之后,在目录下的runs文件夹下会自动生成训练过程记录,包含模型权重、混淆矩阵、PR曲线、loss曲线等

2.3 在linux系统中进行训练
在linux系统中我们可以加大workers(数据加载时的工作线程数),从而加快训练速度,代码跟win系统基本保持一致:
from ultralytics import YOLO
model=YOLO('yolov8n.pt')
model.train(data='./data.yaml',imgsz=(640,640),workers=16,batch=32,epochs=60)值得注意的是,无论是在win系统中还是linux系统中,都要根据自己电脑、服务器的算力去选择合适的workers和batch,设置过小训练速度慢,设置过大,会out of memory.