【李宏毅机器学习】Transformer 内容补充
视频来源:10.【李宏毅机器学习2021】自注意力机制 (Self-attention) (上)_哔哩哔哩_bilibili
发现一个奇怪的地方,如果直接看ML/DL的课程的话,有很多都是不完整的。开始思考是不是要科学上网。
本文用作Transformer - Attention is all you need 论文阅读-CSDN博客的补充内容,因为发现如果实操还是有不能理解的地方,所以准备看看宝可梦老师怎么说×
Self-attention
引入

到目前为止,我们的network的input都是一个向量,输出可能是一个数值(regression)或者类别(classification)。但是假设我们遇到更复杂的问题呢?如果输入是一排向量,并且输入向量的长度是会改变的呢?
(老师提到在做图像分类任务的时候,假设输入图像的大小是一致的,但是实际上,我们可以不指定卷积核的大小,而通过我们期待的feature map的大小和输入图片的大小来反推卷积核的大小,感兴趣的话可以参考
SPP(Spatial Pyramid Pooling)网络 - 知乎 (zhihu.com)
CNN 在分类图片时图片大小不一怎么办? - 知乎 (zhihu.com)
[1406.4729] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (arxiv.org)当然在SPP出现之前一般采用的策略是裁剪or缩放or填充padding)
假设我们每次输入sequence的数目or长度不一样,怎么办?
但是什么例子是输入的是sequence并且长度会改变呢

比如文字处理。假如我们现在要输入的是一个句子,因为每个句子的长度都不一样(句子中词汇的数目不一样),如果把句子里面的每一个词汇都描述成一个向量,那么model的输入就会是一个vector set,并且这个vector set的大小不一样。
怎么把词汇表示成一个向量呢?最简单的方法是one-hot encoding。搞一个很长很长的向量,向量的长度就是世界上所有的词的数目,每一个位置对应到一个词汇。但是,这种方法有一个问题->假设所有的词汇彼此之间是没有关系的,我们看不出来cat和dog都是动物,cat和Apple一个是动物一个是食物就不太相像->没有语义信息。
另一个方法是Word embedding,这里给每一个词汇的向量就包含了语义的信息,如果画出来的话,会看到相似的概念都团在一起。
一个句子就是一排长度不一的向量
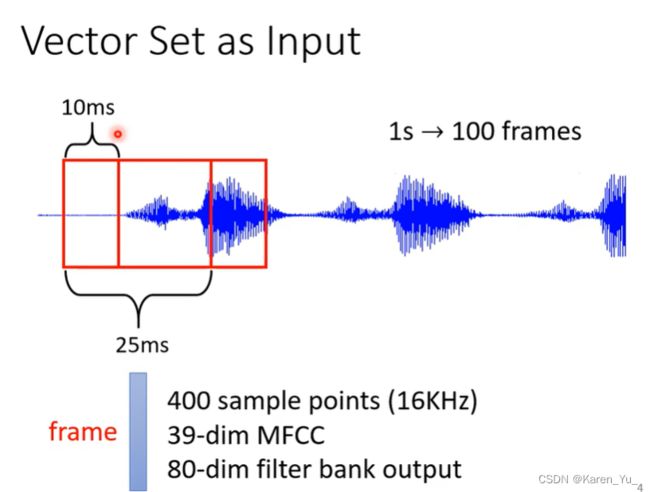
还有一个例子就是声音信号。一段声音信号,取一个范围(Window),把这个Window里面的信息描述成一个向量(frame),这个Window的长度是25ms,有各种各样的方法把声音信号转成frame,然后移动window(通常为10ms)->1s的声音信号又100个frame
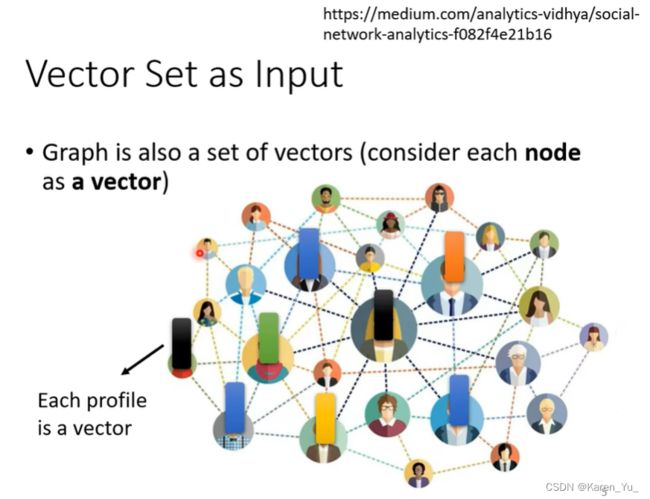
还有一个例子是,图。
比如social network就是一个graph,在social network上面每一个节点就是一个人,节点和节点之间的edge就是这两个人的关系,每一个节点都可以看做是一个向量(可以拿每个人的profile的信息用向量表示)
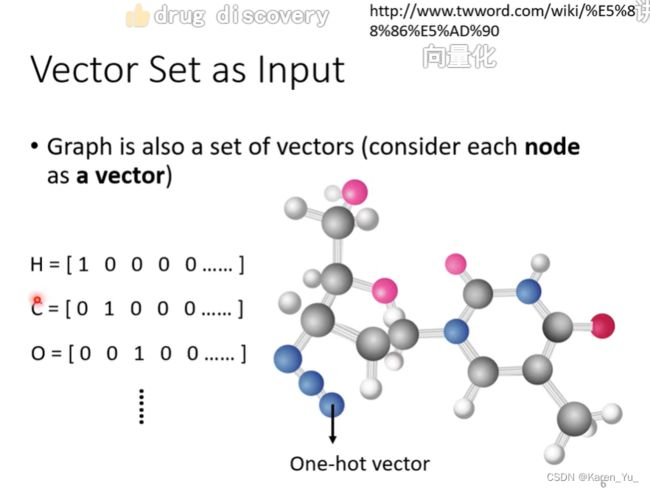
应用:drug discovery
把分子当做模型的输入,一个分子就是一个向量,用one-hot表示原子。

输出是什么?
1. 每一个向量都有一个label
当我们的模型看到输入是4个向量的时候,就要输出4个label,如果label是数值,就是regression问题,如果是class就是classification。
文字处理可能会遇到,比如词性标注,是名词、动词、形容词……
语音,每一个vector都要决定是哪一个Phoneme
给一个social network,决定每一个节点有什么特性,比如会不会买某个商品

2. 一个sequence(有很多的vector)只需要一个输出就好了
比如sentiment analysis,情感分析,即给机器看一段话,让机器判断这一段话是积极地还是消极的->一整个句子只需要一个label。
辨认说话的人
graph,预测一个分子有没有毒性?亲水性怎么样?

3. 不知道输出多少个label,机器需要自己决定要输出多少个label(称为seq2seq)
比如机器翻译,语音识别
本节只focus on 第一个类别,每个vector都输出一个label

这种输入和输出数目一样多的情况又称sequence labeling。
怎么解决这种sequence labeling的问题呢?比较直觉的方法是拿一个fully connected network,虽然输入是一个sequence,我们就直接各个击破,把每一个向量分别输入到fully connected network里面,然后产生正确的输出就OK了。
但是这么做有很大的问题。比如我们要做的是词性标注的任务,比如I saw a saw,对于fully connected network来说,两个saw完全一模一样啊,输出同样的词汇,没可能输出不同的结果啊,但是实际上第一个saw是动词,第二个saw是名词->有没有可能让fully connected network考虑更多的上下文?
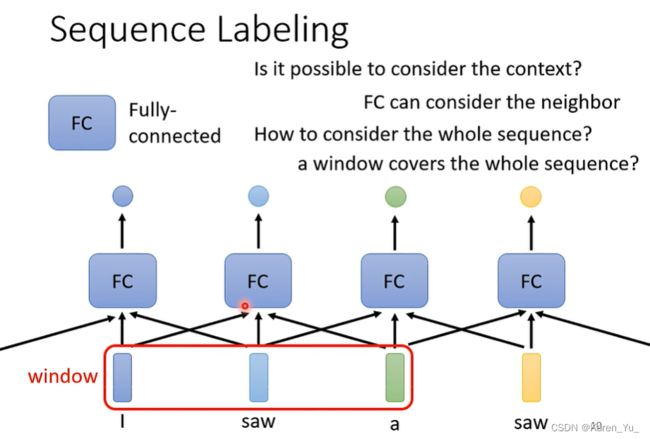
有可能的。
把当前向量和前后几个向量都串起来(window),一起丢到fully connected network里面去。
但是这个方法还是有局限,如果我们现在的任务不是考虑一个window就可以解决的,而是要考虑整个sequence呢?可以直接把window开大一点,包含整个句子吗?但是sequence的长度是不确定的,有长有短的。同时开一个超大的window意味着我们的fully connected network需要很多的参数,运算量很大,说不准还容易overfitting。
(弹幕:rnn考虑的是前一个隐藏状态,但是隐藏状态又包含之前的信息
RNN本质上只有短时的记忆,其实也就是前几个输入的信息,再往前的信息根本记不住了已经)

更好的方法->self-attention
self-attention的运作方式是,会吃一整个sequence的信息,然后input几个vector就输出几个vector。比如图中input4个vector就output4个vector。输出的4个vector有什么特别的地方呢?这4个vector都是考虑整个sequence之后才得到的,再把这些考虑了整个sequence的向量丢到fully connected network,再决定最后的output。
现在fully connected network就不是只考虑一个非常小的范围,而是考虑整个sequence的信息再决定输出什么样的结果。
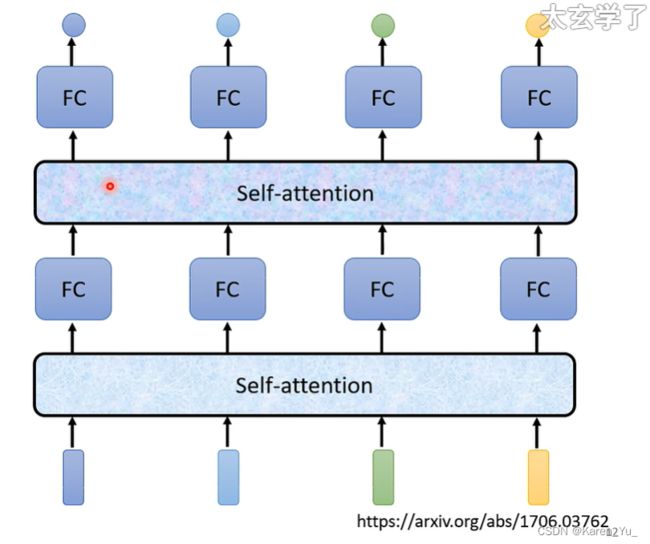
self-attention不是只能用一次,可以叠加很多次。比如之前self-attention的输出经过fully connected network之后的输出再当做输入给另一个self-attention吃,最后再丢给另一个fully connected network,得到输出。
->可以把fully connected network(FC)和self-attention交替使用。self-attention处理整个sequence的信息,FC专注于处理某一个位置的信息

有关self-attention最知名的文章《变形金刚》(×)
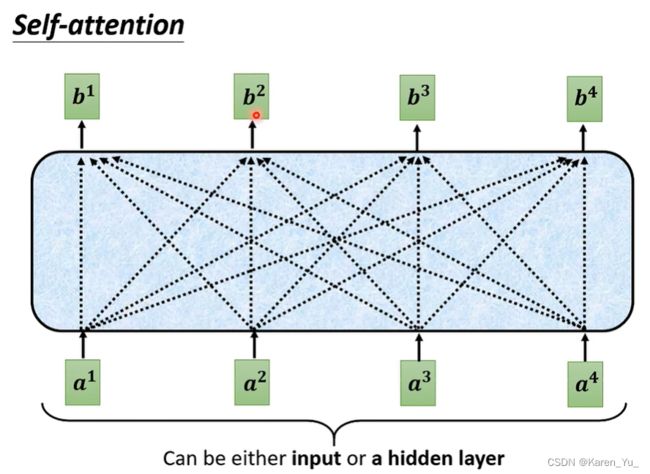
self-attention是如何运作的呢?
self-attention的input是一串的vector,这个vector可能是整个network的input,也可能是某个hidden layer的output(所以这里用a表示->表示前面可能已经做过一些处理了)
input一排a向量之后,self-attention要output一排b向量,每一个b都是考虑了所有的a以后才生成出来的。
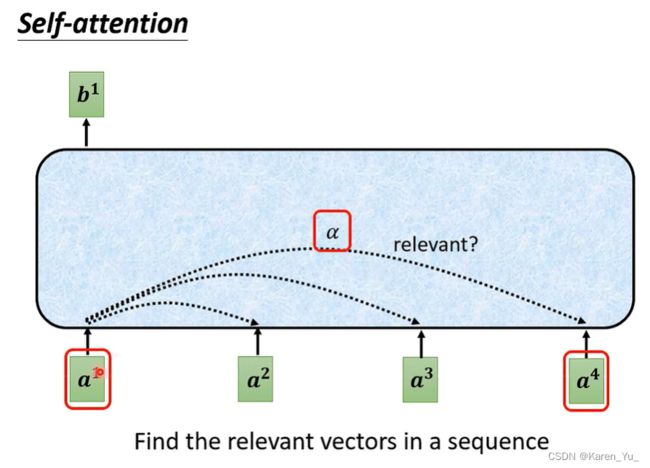
举例说明,怎么产生b^1向量。
第一个步骤是,根据a^1找出这个sequence里面其他和a^1相关的向量(我们做self-attention的目的是为了考虑整个sequence,但是我们又不想把整个sequence的信息都包在一个window里面)->找出哪些部分对a^1是重要的。
每一个向量和a^1关联的程度,用一个数值α表示。现在给两个向量,比如a^1和a^4,怎么计算这两个有多相关?
(弹幕:注意力就是权重)
怎么计算attention
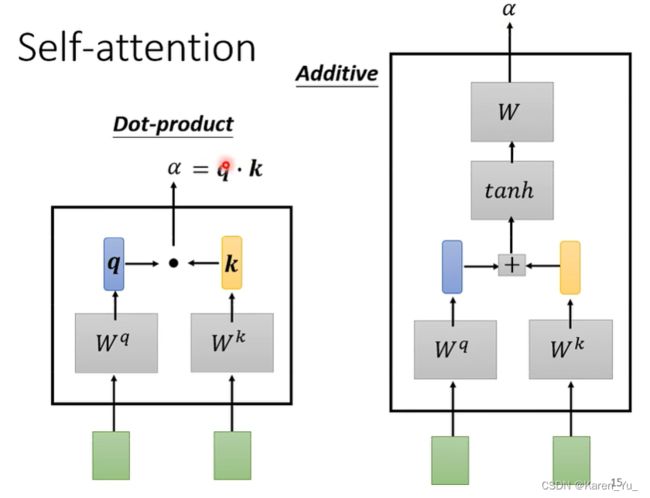
用两个向量当做输入,直接输出α。那么怎么计算α的数值呢?比较常见的做法是dot-product。
把输入的两个向量分别乘上两个不同的矩阵,图中就是左侧的向量乘以W^q这个矩阵,右侧的向量乘以W^k这个向量。
带入一下刚刚的例子就是:
![]()
![]()
得到q和k两个向量:
![]()
![]()
再把q和k两个向量做点乘(element)得到一个scalar,这个scalar就是α
![]()
除此之外,还有其他的方式,比如右侧的additive方法,这里是把q和k加起来,过一个activation function,再过一个transform得到α
后续的讨论都focus on dot-product方法(常用)了。
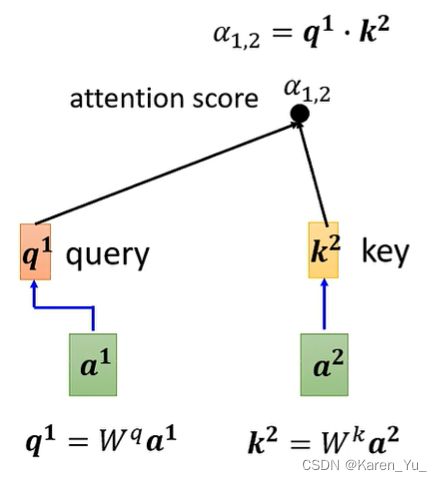
知道单个的计算方法之后,我们就要拿a^1和后面的a^2 a^3 a^4都分别计算关联性(α)。
也就是我们先把W^q乘上a^1得到q^1,这个q^1我们叫做query,就像是我们使用搜索引擎的时候,用来搜的关键字。
![]()
剩下a^2 a^3 a^4都要给乘上W^k,得到key。
![]()
把q^1和k^2算inner product得到alpha
![]()
这里用1,2表示query是1提供的,key是2提供的,这个α称为attention score。
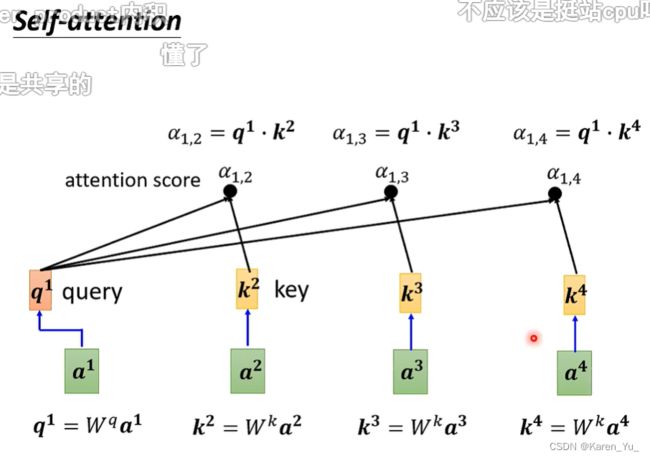
同样的方法我们也要对a^3 a^4做,得到相应的key
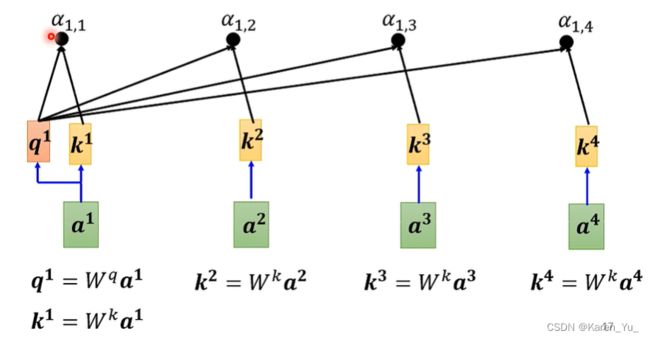
在实际操作的时候a^1也会算和自己的关联性(还有k^1)
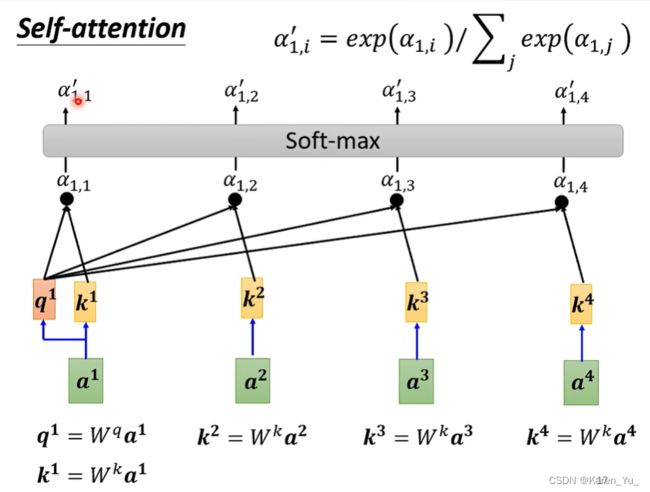
我们计算出a^1和每一个向量的关联性之后,会做一个softmax(这个softmax和分类的时候用的softmax是一模一样的)exp(α),然后在normalize(除以所有exp的和)
softmax的输出就是一排α'
为什么用softmax呢?
不一定要用softmax,用别的激活函数也完全没问题,只是softmax很常用(常用就说明softmax肯定打败了其他的)
怎么抽取信息
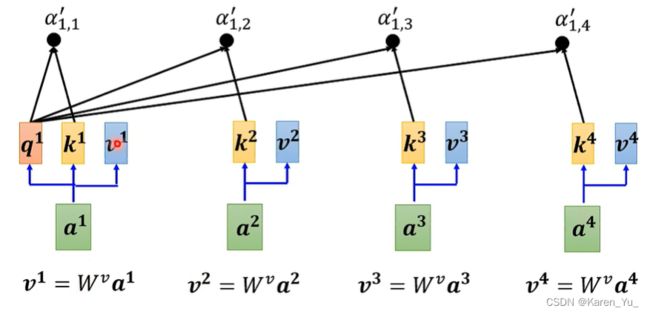
得到α'以后就要根据α'去抽取sequence里面重要的信息。根据α,我们已经知道哪些向量和a^1是最相关的,接下来我们要根据关联性(根据attention的分数),来抽取重要的信息。
那么怎么抽取信息呢?
把a^1 a^2 a^3 a^4每一个向量乘上W^v,得到新的向量,即v^1 v^2 v^3 v^4
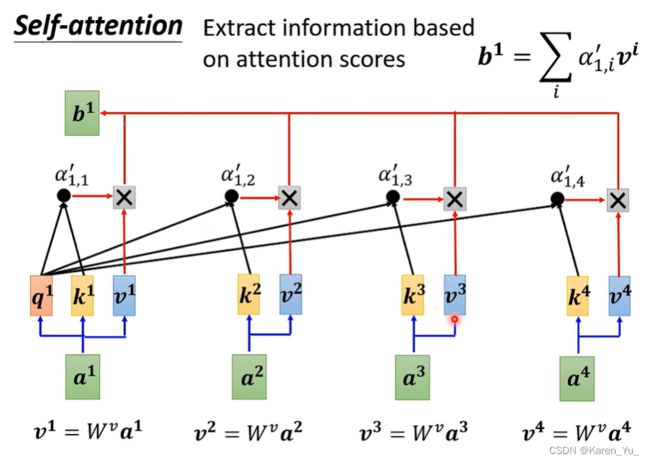
接下来,把得到的v^1 v^2 v^3 v^4每一个都分别乘对应的α值(attention的分数),然后再加起来
(弹幕:这不就解释了为啥用softmax了 比例均匀 好加权
所以是因为QVK都是来自自己,所以叫自注意力吗
基于注意力分数获取信息
之前Q,K是经过非线性变换的,主要为了学习不同位置下的关系)
可以想象到,如果某一个向量(比如a^2)得到的分数越高(与a^1关联性很大),那么我们在做weighted sum之后得到的结果就可能比较接近v^2
->谁的attention分数越高,谁的v就会dominate抽出来的结果
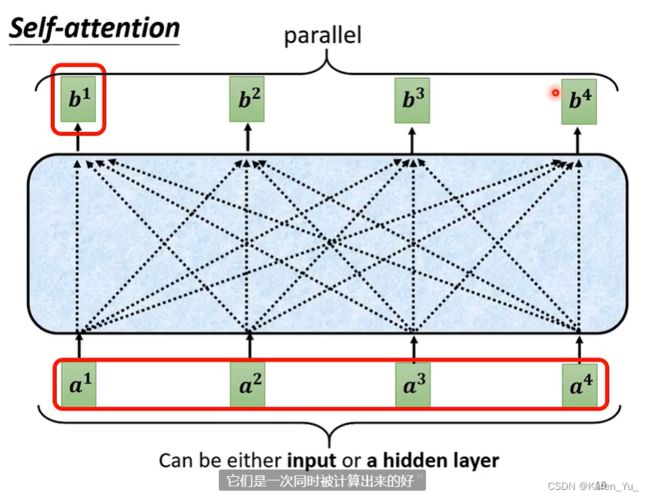
现在我们就从一排vector得到了b^1
注意b^1 b^2 b^3 b^4的计算并没有先后关系,是同时被计算出来的
完整的计算流程

现在以a^2为例。
a^2会乘上一个matrix变成q^2
接下来会根据q^2对a^1 a^2 a^3 a^4四个位置计算attention的score(方法,拿q^2和k^i做dot-product),得到四个分数α。
得到四个分数之后,做一个normalization(比如softmax),得到最后的attention score α'
得到attention score α'四个数值之后,分别乘上v^1 v^2 v^3 v^4
全部加起来得到b^2
(弹幕:qkv的值是乘上qkv分别对应的权重矩阵得到的,这些权重矩阵就是神经网络要训练的参数)
_______________________________________
以上是dot-product运算的过程
以下是从矩阵乘法的角度看dot-product
——————————————————————
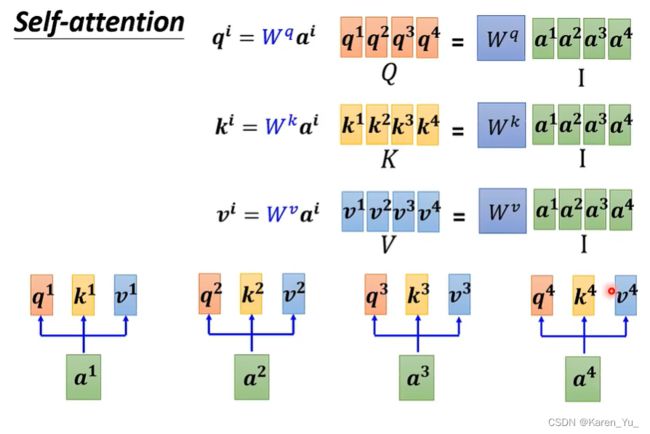
现在我们已经知道a^1 a^2 a^3 a^4每个都要分别产生q k v,如果用矩阵运算表示这个操作:
![]()
![]()
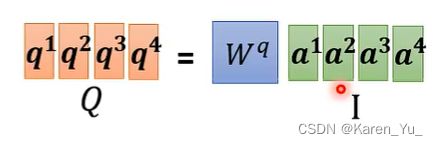
这里W^q是矩阵的参数,等下会learn出来的
同理,我们就会得到K和 V

得到Q K V之后,就是每一个Q都会和每一个K去dot-product,计算attention的分数。
所以就是k^1和q^1做inner product得到α_{1,1}

(介绍一下annotation,这里:
 :表示的是a^1的query和a^1的key算出来的attention score
:表示的是a^1的query和a^1的key算出来的attention score![]() :表示的是这是k^1向量中的第一个数字
:表示的是这是k^1向量中的第一个数字![]() :表示的是这是k^1向量中 到最后一个数字,并且指明k^1向量的长度为n
:表示的是这是k^1向量中 到最后一个数字,并且指明k^1向量的长度为n![]() :表示的是这是q^1向量中的第一个数字
:表示的是这是q^1向量中的第一个数字![]() :表示的是这是q^1向量中 到最后一个数字,并且指明q^1向量的长度为n)
:表示的是这是q^1向量中 到最后一个数字,并且指明q^1向量的长度为n)

类似的,我们可以把四个分数都表示出来

因此就可以看做是把k^1 k^2 k^3 k^4拼起来和q^1相乘
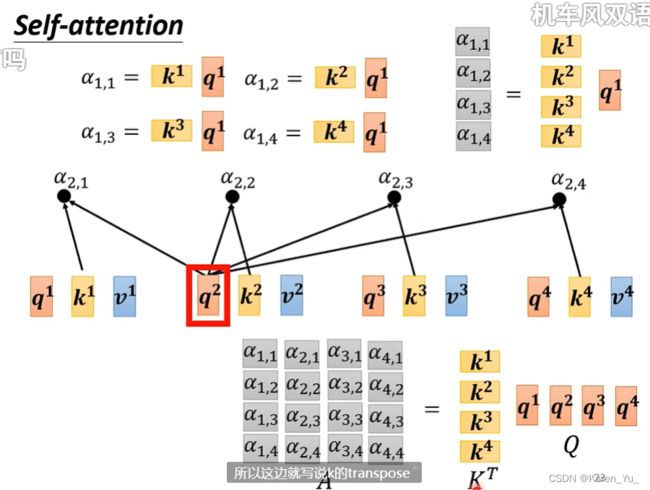
同理,其他也要算attention
(弹幕:本质上是将所有过程转换成矩阵乘法,然后通过比如动态规划等算法进行加速,实现中通常是由gpu负责)
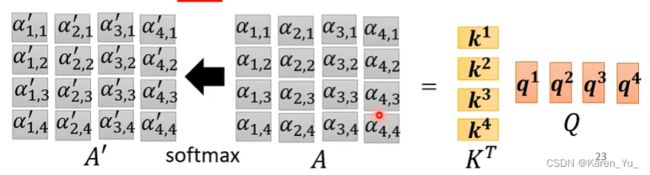
然后对分数做normalization
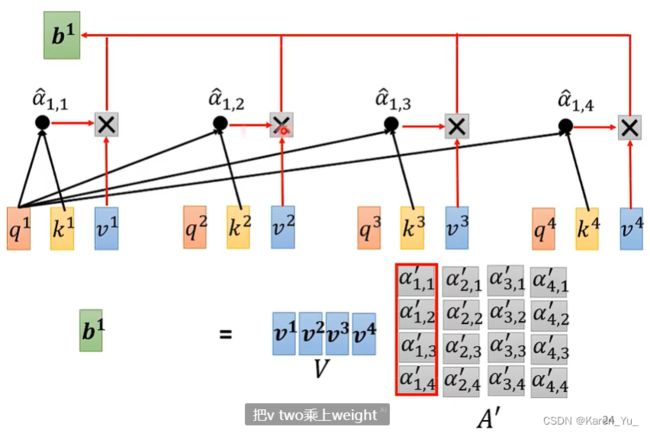
下一步就是得到b^1,就是拿出每个a对应的分数,乘以v的值

同理,得到所有的vector b
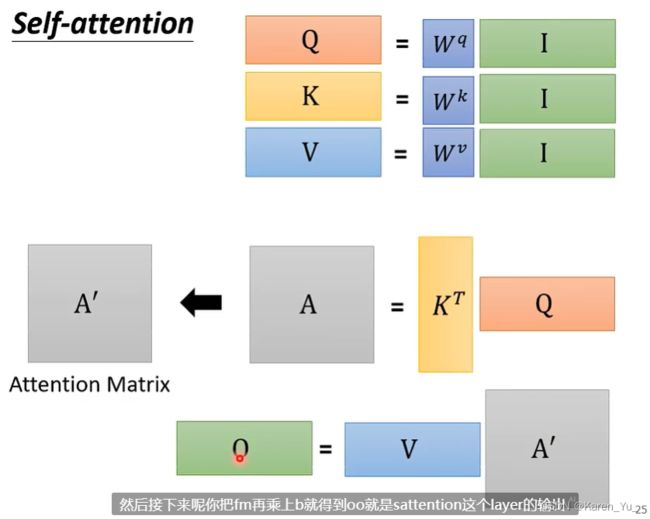
->其实一连串的操作就是一连串的矩阵乘法而已

只要learn三个矩阵就好啦
Multi-head Self-attention
例子

self-attention有一个进阶的版本叫做multi-head self-attention。有的时候多一点head能得到更好的结果(但是具体用几个head,这又是另外一个hyperparameter了,需要咱们自己调啦)
为什么需要比较多的head呢?
我们在做self-attention的时候,我们就是用q去找相关的k,但是相关有很多不同的定义。所以……也许我们不能只有一个q,用不同的q去负责不同种类的相关性。
所以在做multi-head的时候,我们先把a乘上一个矩阵得到q,接下来再把q成上另外两个矩阵,分别得到q^1和q^2(图中采用的是q^{i,1},这里i代表位置,1和2代表是这个位置的第几个q)。代表有两个head->认为这个问题里面有两种不同的相关性,来找两种不同的相关性。
同理,k和v也有两个(方法就是得到k v之后再分别乘以两个矩阵,得到k^{i,1} k^{i,2} v^{i,1} v^{i,2})
同理对另一个位置j我们也做相同的操作。

下一步是做self-attention。
现在的idea是属于类别1的一起做,属于类别2的一起做(看上标是1还是2)。比如q^{i,1}在计算的时候就只关注k^{i,1} k^{j,1},做dot-product,得到分数。
之后也不用管2,只看1类的v
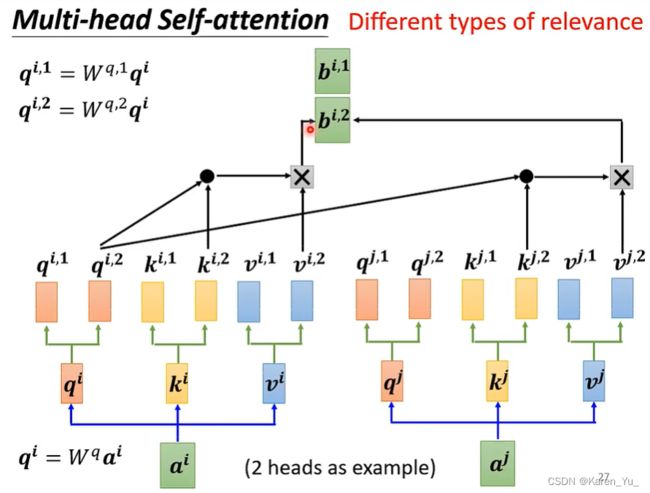
同理对第2类也做相同的操作
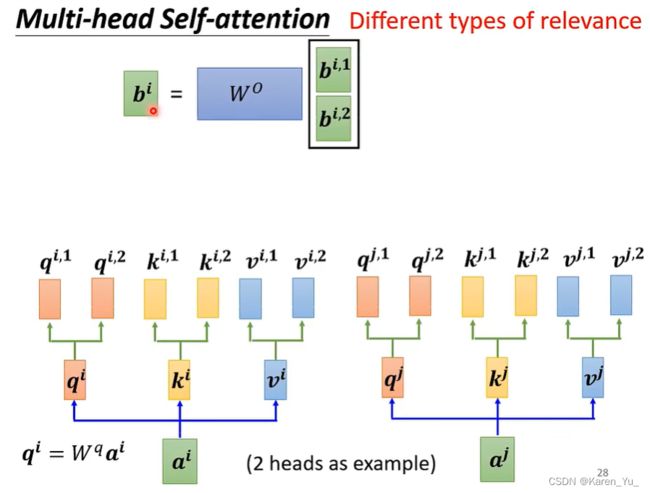
接下来,我们可能会把b^{i,1} b^{i,2}接起来,乘上一个矩阵得到b^i,再送到下一层去
Positional encoding

到目前为止,这个self-attention的layer少了一个可能很重要的信息,位置信息。对一个self-attention layer而言,每一个input是出现在sequence的哪个位置是不知道的。对于self-attention layer来说它并不觉得a^1和a^4就差很远,a^2和a^3就挨着,对它来说所有位置之间的距离都是一样的。
但是位置信息也许很重要啊,比如在做词性标记的时候,可能动词不太容易出现在句首。
所以在做self-attention的时候,如果觉得位置的信息是有用的,可以把位置的信息塞进去。
这里采用的技术称为positional encoding。为每一个位置设定一个vector(称为positional vector,用 e^i表示,i代表位置),每一个不同的位置就有不同的vector。把这个e加到a^i上就可以了
这个positional vector是人设的,所以可能有问题,比如我只设定到128,但是新进来的sequence的长度是129。不过在attention is all you need里面已经没有这个问题了,因为其vector是通过一个规则产生的(是一个sin cos的function)
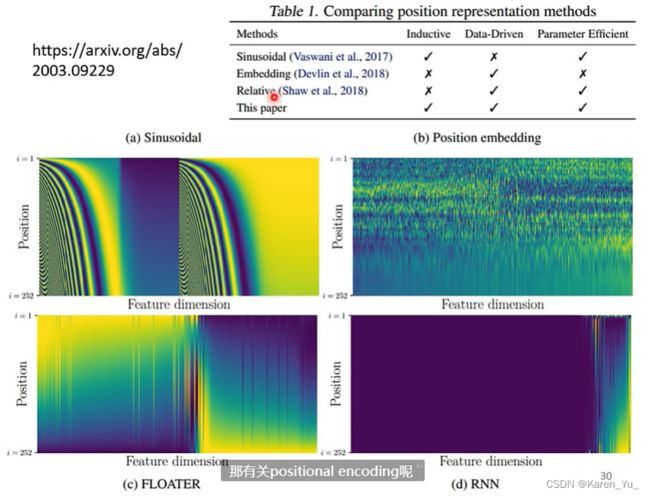
不过具体怎么做好,还尚待研究(到课程的时间)
应用


也可以用在语音上,如果想把语音信号表示成一个向量,那么这个向量可能非常的长(指向量个数很多),可能会带来计算上的困难(矩阵太大啦)
所以可能需要改改。
这里采用的是truncated self-attention,就是说我们现在不看一整句话,而是看一个范围,具体范围多大,这个是人设定的

还可以被用在图像上。
把每一个位置上的pixel看成是一个三维的向量,所以这里,整个图片就是5×10个向量。
比如:
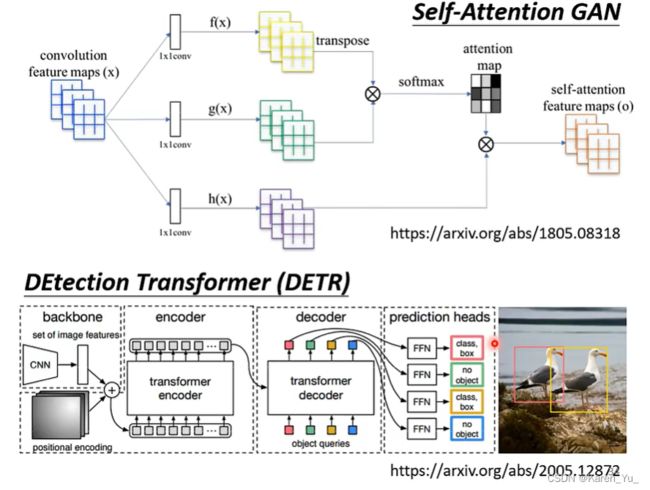
self-attention v.s. CNN

假设现在我们用self-attention来处理一张图片,假设现在上面的红框框的地方是我们要考虑pixel,那么这个红框产生query,其他(包括其本身)产生key,在做inner product的时候,考虑的就是整张图片。
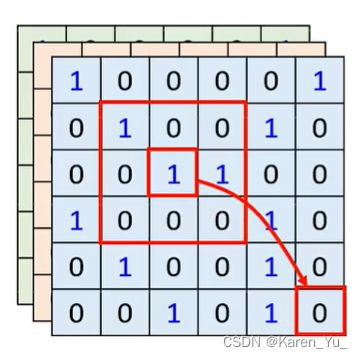
但是我们在做CNN的时候,会画出一个receptive field,每一个neuron只考虑这个receptive field里面的信息。

->CNN可以看做是一个简化版本的self-attention,只考虑receptive field里面的信息
self-attention可以看做是复杂化的CNN,CNN中receptive field的范围和大小是人决定的,attention就像是receptive field是自己学出来的

CNN其实是self-attention的特例,只要设定合适的参数,self-attention就可以做到和CNN一样的事情(具体数学推理参考图片中的论文)
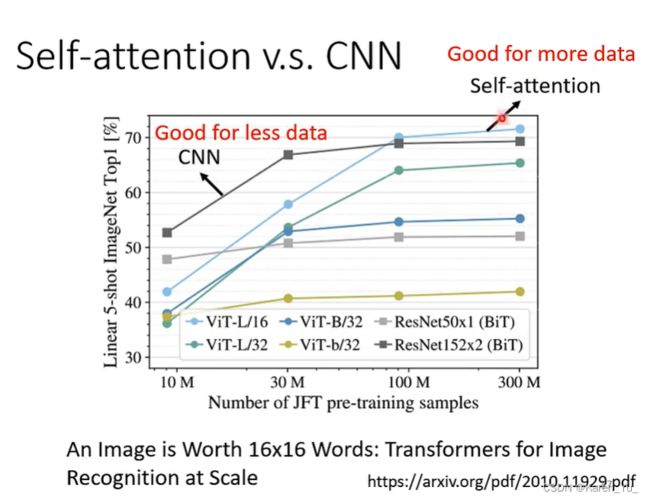
越flexible的model比较需要更多的data,如果data不够就容易造成overfitting。比较小的/有限制的model就比较适合在data少的时候,如果限制设置的好也会有不错的结果。
self-attention v.s. RNN
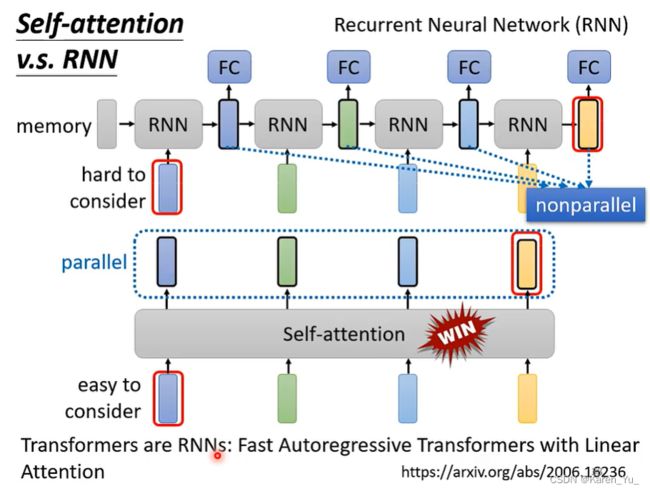
RNN基本可以被self-attention取代(什么前浪死在沙滩上的悲惨故事)
https://leemeng.tw/neural-machine-translation-with-transformer-and-tensorflow2.html
提供了一些很好的动图
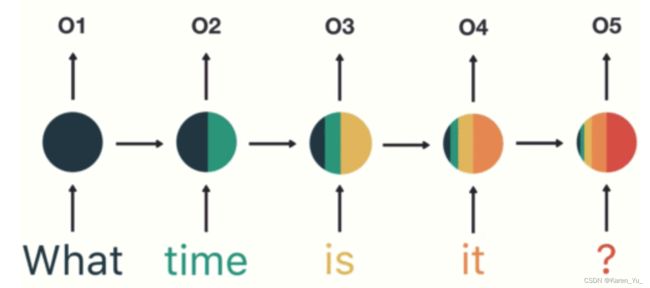
一个非常显而易见的区别是RNN只考虑了左边的vector,没有看到右边的vector,但是实际上RNN也可以用双向的,这样RNN也可以看到右边的情况
但是对于RNN来说,如果想要最后一个vector还记得第一个输入的vector的信息,就要把这个输入的信息存在memory里面。但是self-attention就完全不需要,它可以自己抽取信息。
另外RNN是没办法平行处理所有的output的。想输出最后一个vector,就要等前面的vector都运算完。
self-attention for Graph
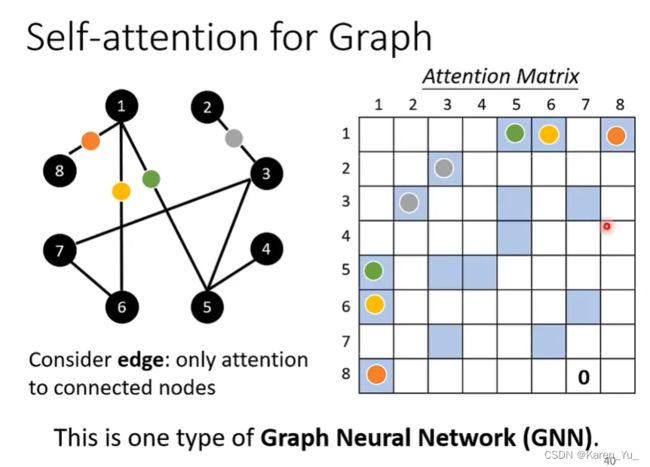
graph也可以看做是一堆vector。
在graph中,我们不止有node(每一个node都可以表示成一个向量),还有edge的信息,需要知道哪些向量是相连的。之前在做self-attention的时候,关联是network自己找出来的,那么这里可能就不需要自己去找。(什么邻接矩阵?)
所以现在完全可以只计算有相连的node的分数。
如果没有向量,就意味着没有关系,没有关系就不用算score了,直接设为0就好了。
self-attention的变形
Transformer
引入

Transformer就是一个seq2seq(input是一个sequence,output也是一个sequence,但是我们不知道output的长度->output的长度由model自己决定)的model
有哪些应用?
语音识别。输入是声音信号,输出是语音识别的结果(输入的声音信号所对应的文字)
机器翻译。读入一个语言的句子,输出另一种语言的句子
语音翻译。输入一段声音信号,直接输出另一种语言的文字
为什么要做语音翻译呢?直接吧上面的语音识别接上机器翻译不可以吗?实际上有很多语言是没有文字的,对于这些没有文字的语言根本没办法做语音识别。
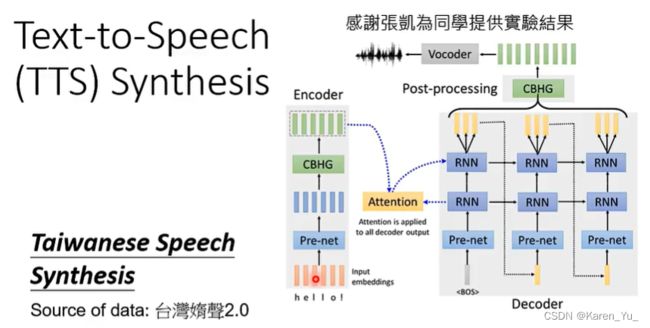
语音合成(语音识别的反面)

聊天机器人(Chatbox)

事实上,seq2seq的model在NLP领域的应用十分广泛。其实很多NLP领域的任务都可以想想成是QA的任务(Question Answering)。所谓QA的任务就是给机器度一段文字,然后问机器一个问题,期待机器给一个正确的答案。比如如果是机器翻译任务,给机器读一篇英语文章,要翻译成德语,这个时候的问题就是这篇文章的德语翻译是什么?或者让机器自动做摘要,这个时候问题就是这篇文章的摘要是什么?或者想让机器做sentiment analysis,这个时候的问题就是这篇文章是正面还是负面的?
输入是问题和文章,输出是答案。
但是对多数NLP的任务而言,为这些任务量身定做的模型会得到更好的结果,不见得非要单独用seq2seq。


用seq2seq硬解的举例。
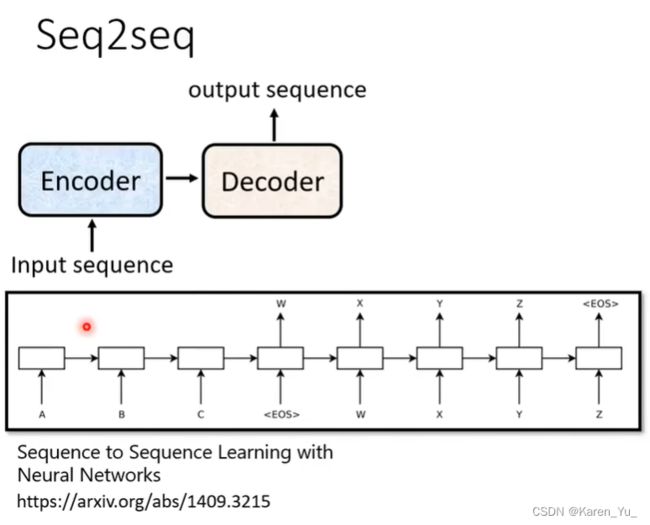
input 一个sequence,由encoder处理这个sequence,再把处理好的sequence丢给decoder,让decoder决定要输出什么样的sequence。
很早就有应用。

只是现在提到seq2seq基本上都想到的是Transformer
encoder
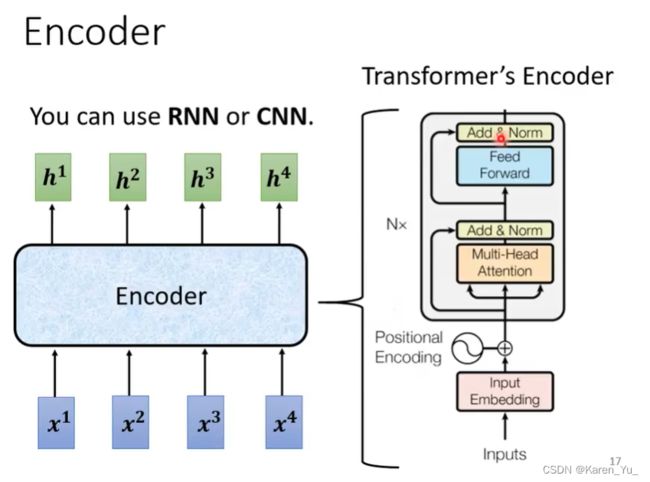
seq2seq中encoder要做的事情是:给一排向量,输出另一排向量。给一排向量输出另一排向量有很多模型都可以做到。比如前面提到的self-attention,比如RNN、CNN(都能够做到input一排向量,output另外一排同样长度的向量)
在Transformer里面,Transformer的encoder用的就是self-attention。

现在encoder里面会分成很多个block。每一个block都是输入一排向量输出一排向量,最后的一排向量会输出最终的vector sequence。这里每一个block并不是neural network的一层,每一个block在做的事情是好几个layer在做的事情。
在Transformer的encoder里面,每一个block做的事情大概是:先做一个self-attention,得到一排vector(考虑整个sequence的信息)之后,把这些vector丢到FC里,再output另外一排vector,这里output的vector才是block的输出。
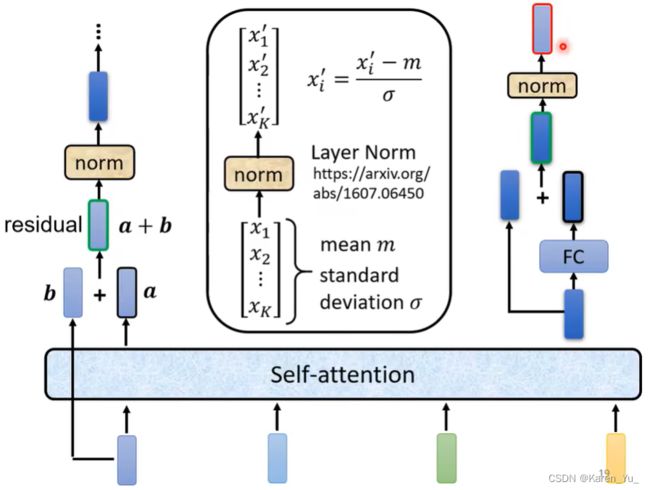
实际上,做的事情更复杂。
在Transformer里面加入了一个设计,self-attention的输出是考虑所有input的结果,除了这样输出的vector,额外添加了input(input+self-attention的output得到新的输出)->residual链接
(很好,又是残差)
做了residual之后,再做normalization,这里使用的不是batch normalization(猜测老师提到的原因是因为resnet用的是batch normalization),而是layer normalization。
layer normalization在做的事情是:输入一个向量,输出另一个向量,不用考虑batch。计算输入向量的mean和standard deviation。注意batch normalization是对不同的example的不同的feature的同一个dimension去计算mean和standard deviation,而layer normalization是对同一个feature的同一个example的不同的dimension计算mean和variance
(弹幕:batch norm 是在nbatch降维,而layer norm在seq上)
纠错,这里的![]() 把上标prime拿掉->
把上标prime拿掉->
得到layer normalization的输出之后,才算得到FC的输入(见右下角)
在FC这边也有residual的架构
再把residual的结果再做一次layer normalization
这个normalization的结果才是这个block的输出

图中的Add & Norm就是residual+layer normalization的意思啦

为什么Transformer的encoder要这样设计,不这样设计可以吗?可以,不一定非要按照原始的Transformer的架构(顺序)。
decoder
autoregressive
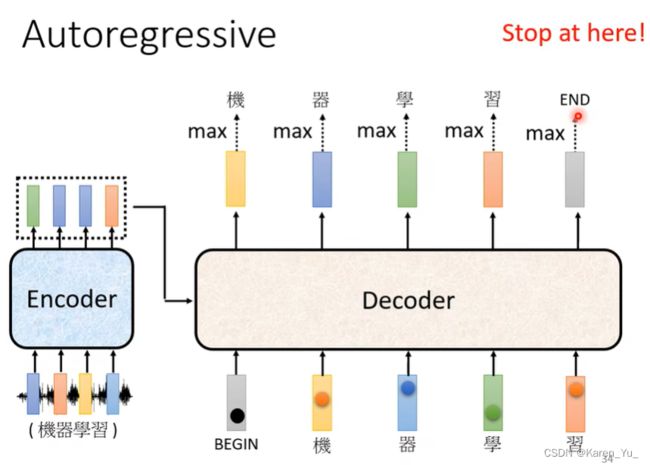
decoder其实有两种,这里主要介绍autoregressive(AT)

autoregressive的decoder是怎么运作的呢?
以语音识别为例(什么是语音识别?输入一段声音,输出一串文字。所以这里encoder在做的就是输入一段声音,输出一排vector)。
接下来就轮到decoder出场了。decoder要做的事情就是产生输出。那么decoder怎么产生语音识别的结果呢?decoder就是先把encoder的输出读进去。
decoder怎么产生一段文字呢?首先要给decoder一个符号,代表开始(
这里解释一下vocabulary。我们首先要想好decoder输出的单位是什么,假设现在做的是中文的语音识别,输出的是中文,那么这里的vocabulary的size可能就是中文的方块字的数目。常用的中文的方块字的数量大概是2000-3000个。不同的语言的vocabulary的size可能是不同的,比如如果是英语,我们可以用字母,也可以用词汇etc。
那么带入到例子里面,这个vector的长度就和我们希望中文可以输出的方块字的数目相等。这样,每一个方块字都会对应一个数值。在产生这个向量之前,通常都会跑一个softmax->这时这个向量其实就是一个distribution(sum=1)。也就是每一个方块字都有一个分数,分数最高的那个字就是最终的输出。

接下来,我们把“机”当做decoder新的input(开始decoder只有一个input
接下来把“器”也当做decoder的输入,现在decoder有三个输入啦:
……
这里encoder也有输入,这个稍后讨论
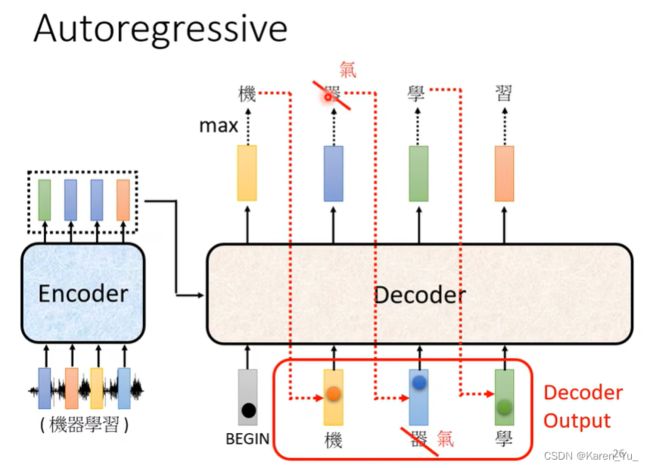
注意这里,decoder看到的输入其实是decoder在前一个时间点自己的输出,decoder会把自己的输出当做接下来的输入。所以当decoder在产生一个句子的时候,有可能看到错误的东西。
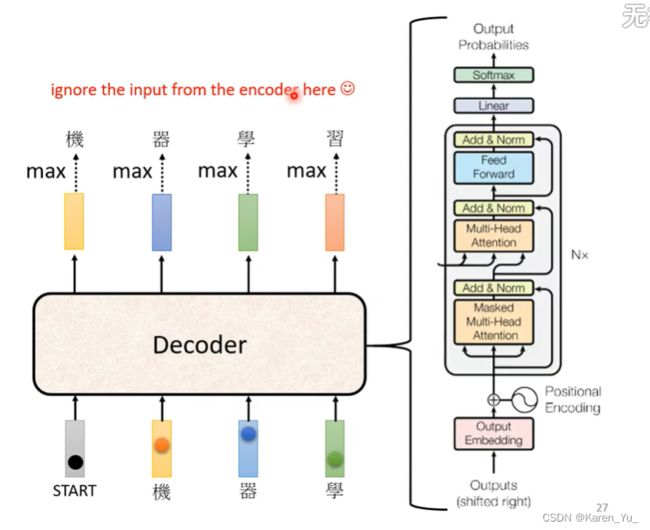
decoder内部的结构。先忽略encoder那边。
在Transformer中decoder的结构如上图所示。

看起来比encoder要复杂一点。如果我们把decoder中间的部分盖上,看起来encoder和decoder两遍的结构差不多哎。->除了中间被遮住的部分,并没有太大的差异哎
还有一个区别是在decoder这边的multi-head attention这里还加了一个masked
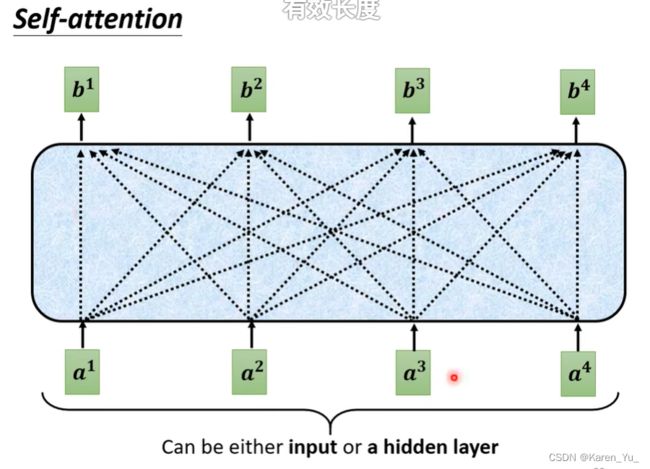
我们原来的self-attention如上图。input一排vector,output一排vector。output的每一个vector都是看过完整的input以后才做决定的。所以输出b^1的时候实际上是看过a^1到a^4所有的信息才输出的b^1。
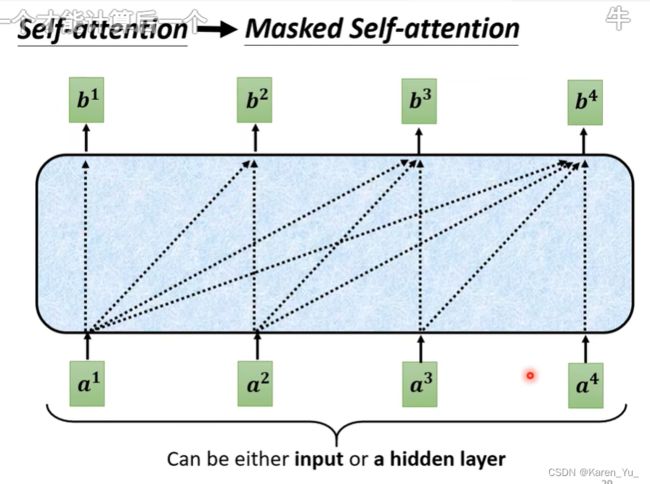
在masked attention的时候,我们不能再看全部的的信息啦。在产生b^1的时候只能考虑a^1的信息(不看a^2 a^3 a^4),在产生b^2的时候只能看a^1 a^2的信息
(弹幕:不完全是RNN,这个masked可以主动掩码,可以支持并行计算,RNN必须先计算出前一个才能计算后一个)
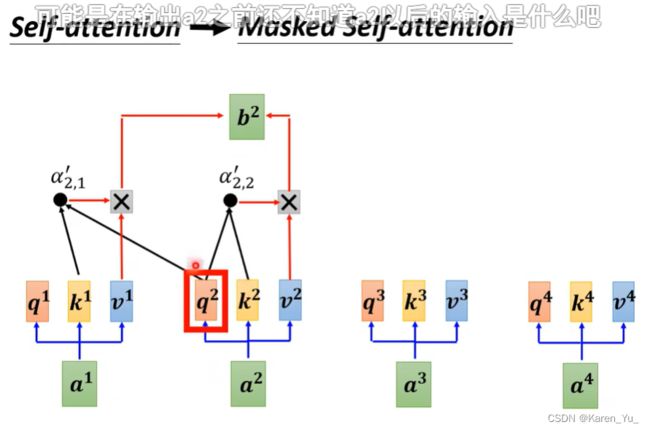
讲的更具体一点:
当我们要产生b^2的时候,只拿第二个位置的query去和第一个位置的key和第二个位置的key去计算attention,第三个位置和第四个位置就不去管了(不计算attention)。
(弹幕:因为bert就做了两件事,分别是mask和NSP,mask也就是类似于完形填空
因为后面的结果还没翻译出来啊,怎么计算和后面的相似度)
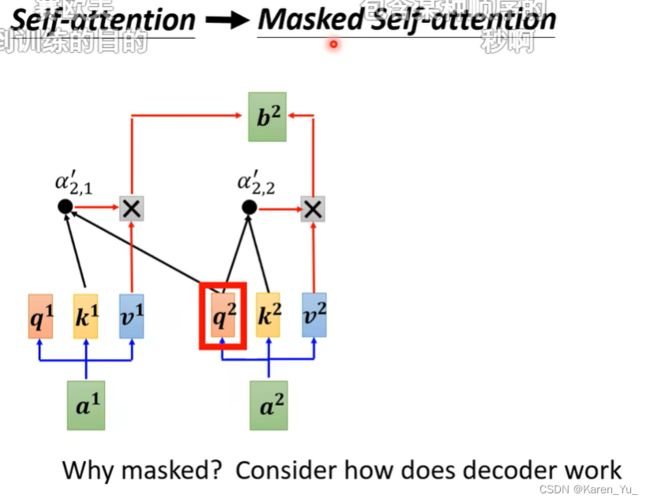
为什么要加masked呢?
回忆一下decoder的运作方式,输出是一个一个产生的,是先有a^1再有a^2再有a^3再有a^4,这和之前的self-attention是不一样的,之前的self-attention是a^1到a^4一起输进去的。但是在decoder这边,当我们要计算b^2的时候,我们是没有后面的a^3 a^4的,所以也没办法把a^3 a^4考虑进去
(弹幕:因为decoder是RNN模式,分步进行
mask的引入说白了就是避免数据泄露~也就是说,不能使用未来的数据进行预测
相当于 你能一眼看到一个句子的所有词汇,但是写的时候只能从前往后一个一个的写
被翻译可以一次获取所有,而翻译成功的要一点点的出
训练的时候你知道后面的a,但你预测的时候后面的a都还没有,你怎么计算?
这个网络的训练方法就是预测下一个会出现的词,如果网络本身就可以获得下一个词的话,那么就只会获得一个一一映射,无法得到训练的目的)
这相当于是告诉我们decoder输出的token是一个一个产生的。所以只能考虑左边的东西而不能考虑右边的东西。
(弹幕:训练的时候decoder的输入是完整的输入,测试的时候才是autoregressive的输入,训练时加了mask为了模拟测试的情况)

到目前为止,还有一个问题,decoder要自己决定输出的sequence的长度
但是到底输出的长度是多少呢?我们没办法轻易的从输入的长度知道输出的长度是多少。并不一定输入是4个向量输出就是4个向量。decoder运作的机制导致decoder并不清楚什么时候应该停下来,比如这里产生“习”之后,还可以继续重复同样的process,比如这里进来一个“习”,下面可能输出一个“惯”。
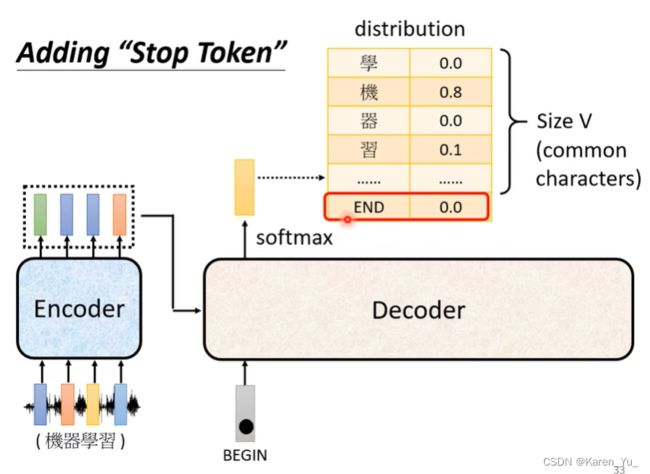
所以我们需要一个特别的标识符,来断开(END)也就是说除了所有的中文的方块字之外还要有
所以我们期待着这样就可以在decoder吃进“习”之后,能够吐出来END,换言之,当把“习”当做输入以后,decoder看到encoder输出的embedding还有
(弹幕:训练的时候加end,预测的时候由模型决定,感觉是这样
就是说某一次迭代softmax 输出的分布里 end 对应的概率分数为最大值的时候)
Non-autoregressive(NAT)

NAT不同于AT(一个字一个字往外蹦),是一次把整个句子产生出来
吃一整排BEGIN的token,让一次产生一排token,接结束了
但是不是不知道应该输出多长吗?是的,确实没办法很直接的知道。idea1:另外learn一个classifier,吃encoder的input,输出数字,代表输出的长度,这样decoder就吃这个数字个数的BEGIN。idea2:不在乎。随便输入,但是忽略END之后的输出。
(弹幕:4个begin其实是不同的东西,比如不同的语音片段)
NAT的好处:
1. 平行化(如果想输出100个token的句子,AT就需要做100次的decode,但是NAT不care句子的长度是多少,都是一下出来)
2. 比较能控制输出的长度。比如语音合成,比如现在想讲快一点,就把classifier的output除以2(假设用的是idea1的方法),那么这个时候的语速就是2倍快了,如果想讲慢一点就可以把classifier的output乘以2。
Encoder-Decoder

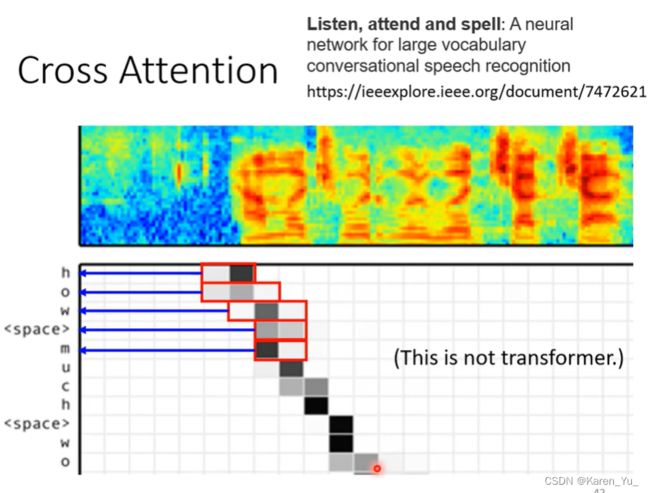
如图,红框框那里。这里叫做cross attention,是链接encoder和decoder之间的桥梁
从图中可以发现,encoder提供两个输入(来自encoder的那边有两个箭头,蓝色圈圈),decoder提供一个箭头(绿色圈圈)

decoder会先吃BEGIN(

(弹幕:decoder以某种形式和注意力转移,不断的观察原文,输出翻译后的)
后面也一样,假设现在已经产生了第一个中文的字“机”,现在decoder输入BEGIN “机”,产生一个向量q',一样和k^1 k^2 k^3计算分数,和v^1 v^2 v^3做weighted sum,得到v',交给后面的FC
Training

仍然以语音识别为例。做语音识别需要收集什么样的数据?要手机大量的声音信号,每一句声音信号都要找人给打标签(对应的词汇是什么)。那么,怎么让机器学到这件事呢?我们已经知道输入这一段声音信号,输出的第一个字应该是“机”,所以当我们把BEGIN丢给decoder之后得到的第一个输出应该和“机”越接近越好。什么叫和“机”越接近越好?“机”会被表示成一个one-hot vector,只有“机”对应的维度是1,其他都是0(见左上角),我们decoder的输出是一个distribution,是一个概率分布,我们会希望这个输出的概率分布和这个one-hot vector越接近越好。所以我们会去计算这个groundtruth和这个distribution的cross entropy,我们希望这个cross entropy的值越小越好->和分类很像。

所以实际上训练的时候,我们已经知道输出应该是“机器学习”这四个字。现在我们就告诉decoder说,每一次的输出分别应该是“机”“器”“学”“习”这四个字的one-hot vector。所以我们就希望输出和这四个字的one-hot vector越接近越好。
在训练的时候,每一个输出的one-hot vector和它对应的正确答案都会有一个cross entropy,我们希望所有的cross entropy的总和越小越好。
不要忘了这里还有END,假设现在中文的字是4个,但是学的时候,要decoder输出的并不是只有这四个中文的方块字,还要叫decoder记住,输完这四个中文字之后,还要输出END这个特殊符号。->也就是说最终第五个位置输出的向量应该和END的one-hot vector的cross entropy越小越好。
(弹幕:一种损失函数,代表预测值和真实结果的差距。所以越小预测越准【这里在回答前面有人在弹幕中提问为什么要cross entropy越小越好,这里提一句题外话,为什么要用cross entropy我最近才get到一点intuition所以在下面大概写一下】)

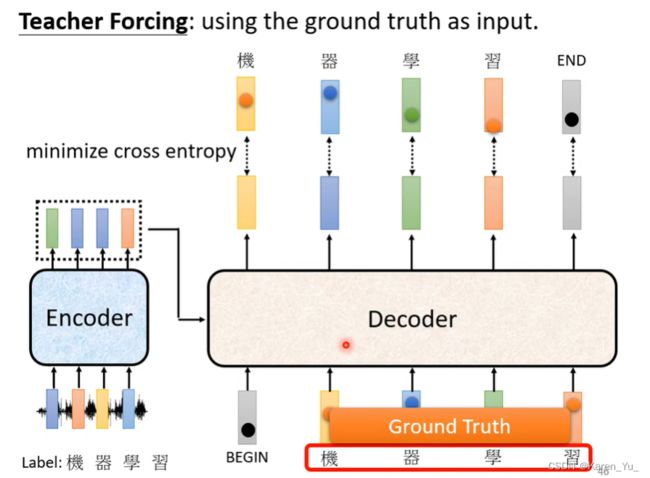
这边有一个问题需要注意。decoder的在训练的时候会给看正确答案(输入ground truth),也就是说我们会告诉decoder在已经有BEGIN和“机”的情况下会输出“器”,有BEGIN“机”“器”的情况下会输出“学”……decoder在训练的时候会给输入正确答案->这种做法叫teacher forcing
(弹幕:可以理解成encoder是在找到输入向量之间的相关性,而decoder是借助这种相关性进行预测,再将预测结果和真实值做交叉熵作为训练的目标函数)
Tips
Copy Mechanism

对很多任务而言,我们都要求decoder自己产生输出,但是对某些任务而言,decoder不需要自己创造输出,也许decoder要做的是从输入的东西里面复制一些东西出来。
什么样的任务需要复制一些东西出来呢?一个例子是做聊天机器人。比如在上图的例子里面,“库洛洛”这个人名显然就没必要让decoder自己创造出来(老实说要是能创造不如让decoder自己画下去了)。但是现在decoder学的并不是要产生“库洛洛”,而是看到“我是xxx”就自动把xxx复制出来说“xxx你好”。
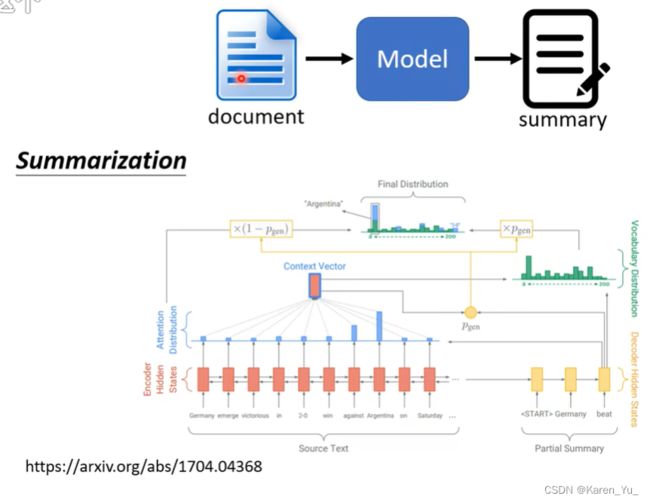
或者在做摘要的时候,可能更需要copy的技能。训练的方法就是收集大量的文章,每个文章都有人写的摘要,然后train一个seq2seq的model,这种model需要大量的文章(比如搞一万篇文章就很逊啦)。在做摘要的时候,有很多字直接就是从原来的文章中复制的。

附相关资料
Guided Attention

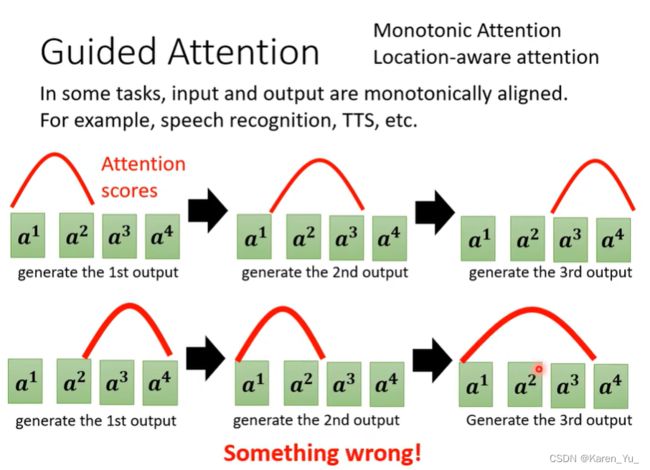
机器是个黑盒子,所以学到什么我们可能也不太清楚,所以有什么会犯很低级的错误。这里给出的例子是语音合成(TTS,text-to-speech)。完全可以用seq2seq的model,就搜集很多的文字和声音对应关系,告诉这个seq2seq model看到这个句子就输出这个声音。然后硬train一发。
怎么解决这个问题呢?
要求机器在做attention的时候有固定的方式。比如在TTS的时候我们认为应该按照从左到右去看句子。
->把这种限制放到training里面,要求机器学到attention就应该从左向右
Beam Search
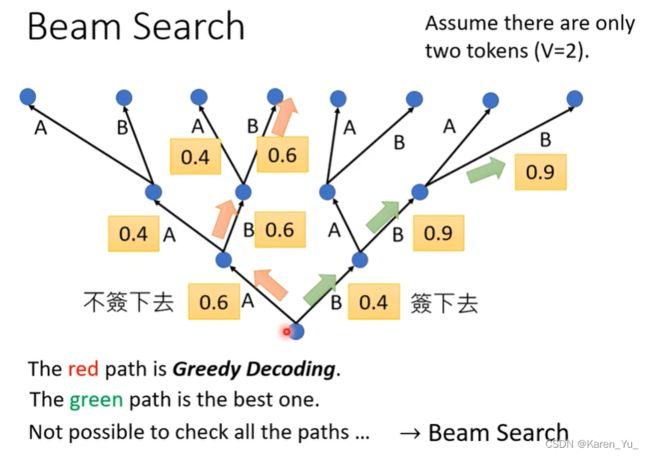
有时候有用,有时候没用
sampling

加入一些随机性(加点噪声)可能效果更好