【吴恩达-神经网络与深度学习】第3周:浅层神经网络
目录
神经网络概览
神经网络表示
含有一个隐藏层的神经网络(双层神经网络)
计算神经网络的输出
多样本的向量化
向量化实现的解释
激活函数(Activation functions)
一些选择激活函数的经验法则:
为什么需要非线性激活函数?
激活函数的导数
神经网络的梯度下降法
(选修)直观理解反向传播
随机初始化
神经网络概览
右上角方括号[]里面的数字表示神经网络的层数
可以把许多sigmoid单元堆叠起来形成一个神经网络:

第一层:

第二层:

反向传播过程:

神经网络表示
含有一个隐藏层的神经网络(双层神经网络)
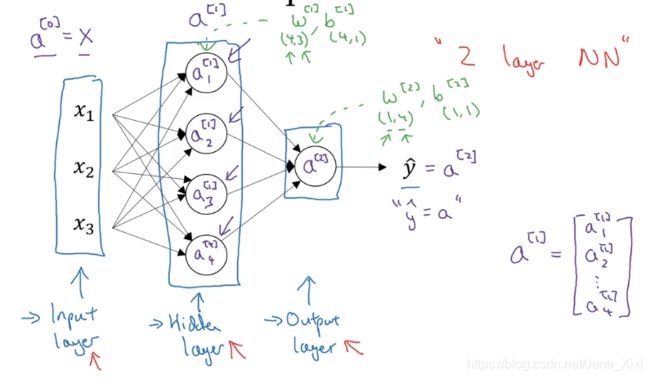
隐藏层,表示无法在训练集中看到它们。
 表示激活的意思,它意味着网络中不同层的值会传递到它们后面的层中,输入层将X传递给隐藏层,所以我们将输入层的激活值称为
表示激活的意思,它意味着网络中不同层的值会传递到它们后面的层中,输入层将X传递给隐藏层,所以我们将输入层的激活值称为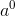
计算神经网络的输出
输入单样本

将其向量化:
即:

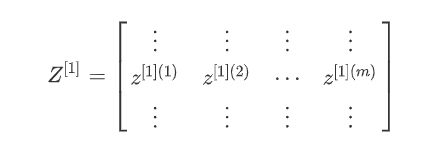
多样本的向量化
m个样本:

进行向量化:
其中:
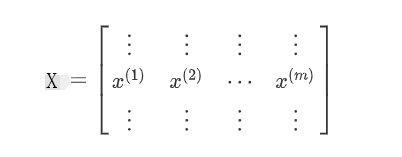

从水平上看,矩阵A代表了各个训练样本。从竖直上看,矩阵A的不同的索引对应于不同的隐藏单元。对于矩阵Z、X也是同样的。
向量化实现的解释
先手动对几个样本计算一下前向传播,看看有什么规律: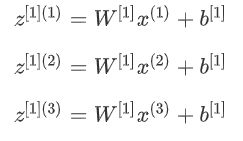
这里,为了描述的简便,我们先忽略掉![b^{[1]}](http://img.e-com-net.com/image/info8/5aaf86b87b0448dfbfe7ee9720b76a5a.gif) 。之后利用Python 的广播机制,可以很容易的将加进来。
。之后利用Python 的广播机制,可以很容易的将加进来。
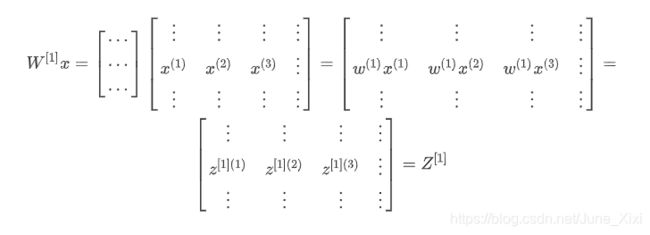
总结:
激活函数(Activation functions)

tanh函数在所有场合都优于sigmoid函数。但有一个例外:在二分类的问题中,对于输出层,因为y的值是0或1,所以想让输出的数值介于0和1之间,而不是在-1和+1之间,所以需要使用sigmoid激活函数。
不同层的激活函数可以不同。
sigmoid函数和tanh函数两者共同的缺点是,在z特别大或者特别小的情况下,导数的梯度或者函数的斜率会变得特别小,最后就会接近于0,导致降低梯度下降的速度。
在机器学习另一个很流行的函数是:修正线性单元的函数ReLu:

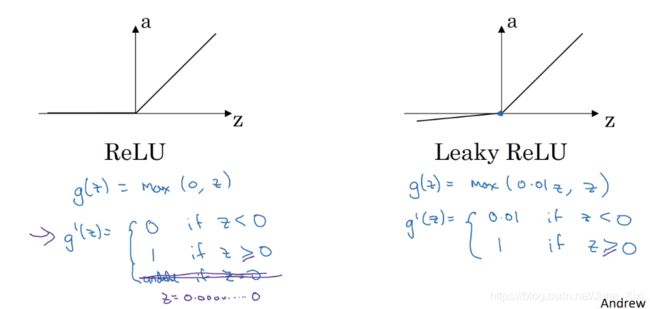
只要z是正值的情况下,导数恒等于1,当z是负值的时候,导数恒等于0。从实际上来说,z=0的导数是没有定义的。但是当编程实现的时候,z的取值刚好等于0.0000000...的概率很小,所以,在实践中,不需要担心这个值。可以再z等于0的时候,假设导数是1或者0。
一些选择激活函数的经验法则:
如果输出是0、1值(二分类问题),则输出层选择sigmoid函数,然后其它的所有单元都选择Relu函数。
这是很多激活函数的默认选择,如果在隐藏层上不确定使用哪个激活函数,那么通常会使用Relu激活函数。有时,也会使用tanh激活函数,但Relu的一个缺点是:当是负值的时候,导数等于0。
有另一个版本的Relu被称为Leaky Relu:当z是负值时,这个函数的值不是等于0,而是有轻微的倾斜。这个函数通常比Relu激活函数效果要好,尽管在实际中使用频率不高。
sigmoid激活函数:除了输出层是一个二分类问题基本不会用它。
tanh激活函数:tanh是非常优秀的,几乎适合所有场合。
ReLu激活函数:最常用的默认函数,,如果不确定用哪个激活函数,就使用ReLu或者Leaky ReLu。

为什么需要非线性激活函数?
这是神经网络正向传播的方程,现在我们去掉函数g,然后令,或者我们也可以令,这叫做线性激活函数或恒等激励函数。

令:
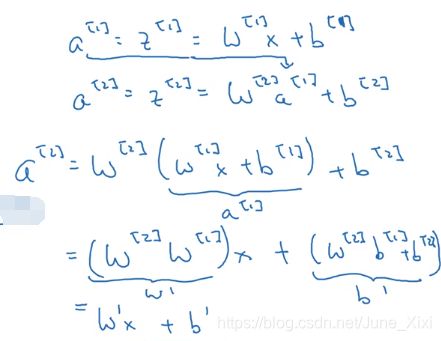
可以看出,如果用线性激活函数(恒等激励函数),那么神经网络只是把输入线性组合再输出。
如果你使用线性激活函数或者没有使用一个激活函数,那么无论你的神经网络有多少层一直在做的只是计算线性函数,所以不如直接去掉全部隐藏层。事实证明如果你在隐藏层用线性激活函数,在输出层用sigmoid函数,那么这个模型的复杂度和没有任何隐藏层的标准Logistic回归是一样的。
总而言之,不能在隐藏层用线性激活函数,可以用ReLU或者tanh或者leaky ReLU或者其他的非线性激活函数,唯一可以用线性激活函数的通常就是输出层。
激活函数的导数
1)sigmoid activation function
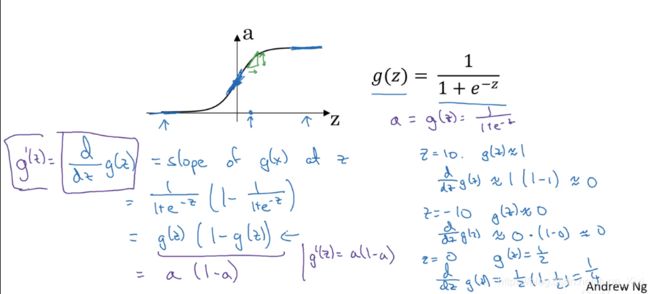
2) Tanh activation function
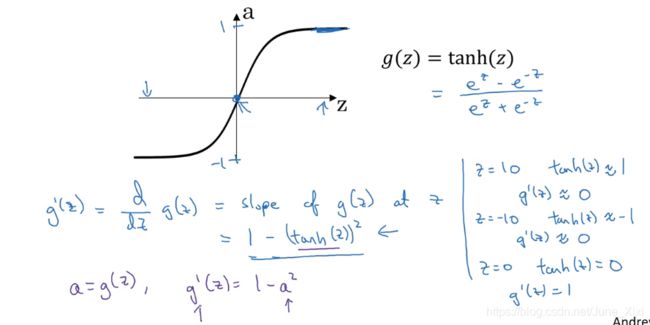
3)ReLU and Leaky ReLU
神经网络的梯度下降法
单隐藏层的神经网络:
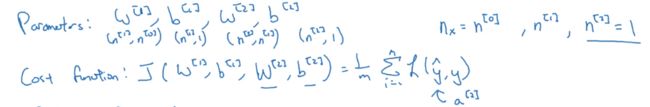
梯度下降:假设为二分逻辑回归
Repeat {
Compute predict (, i = 1, ... , m)
![]()
![]()

![]()
}
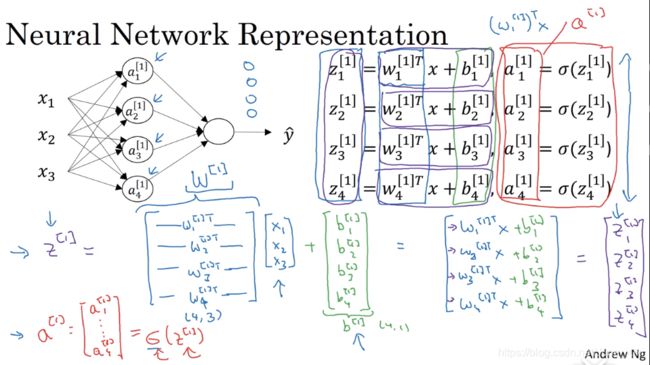
正向传播方程和反向传播方程:

np.sum是python的numpy命令,axis=1表示水平相加求和,keepdims是防止python输出那些古怪的秩数,加上这个确保阵矩阵这个向量输出的维度为这样标准的形式。
*表示逐元素乘积
还有一种防止python输出奇怪的形式的方法,需要显式地调用reshape把np.sum输出结果写成矩阵形式。
(选修)直观理解反向传播

多样本的向量化:
随机初始化
当训练神经网络时,权重随机初始化是很重要的。对于逻辑回归,把权重初始化为0是可以的。但是对于一个神经网络,如果把权重或者参数都初始化为0,那么梯度下降将不会起作用。
用例子来看原因: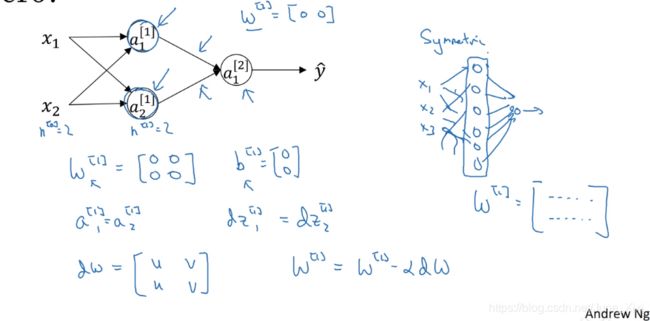
应该对w进行随机初始化:


常数为什么是0.01,而不是100或者1000:通常倾向于初始化为很小的随机数。因为如果用tanh或者sigmoid激活函数,或者说只在输出层有一个Sigmoid,当计算激活值![]() 时,如果W波动很大,z就会很大或者很小,因此这种情况下很可能停在tanh/sigmoid函数的平坦的地方,这些地方梯度很小也就意味着梯度下降会很慢,因此学习也就很慢。
时,如果W波动很大,z就会很大或者很小,因此这种情况下很可能停在tanh/sigmoid函数的平坦的地方,这些地方梯度很小也就意味着梯度下降会很慢,因此学习也就很慢。