【时序预测】2、prophet:Forecasting at Scale | Python 文档教程

文章目录
- 一、Quick Start
- 二、饱和预测
-
- 2.1 Forecasting Growth 预测增长
- 2.2 Saturating Minimum 饱和最小值
- 三、Trend Changepoints 趋势变化点
-
- 3.1 Automatic changepoint detection in Prophet 自动检测变化点
- 3.2 Adjusting trend flexibility 调整趋势灵活性
- 3.3 Specifying the locations of the changepoints 指定变更点的位置
- 四、Seasonality, Holiday Effects, And Regressors 季节、节假日、回归
-
- 4.1 Modeling Holidays and Special Events 对假日和特殊活动进行建模
- 4.2 Built-in Country Holidays 内置的国家放假日
- 4.3 Holidays for subdivisions 详细的节日
- 4.4 Fourier Order for Seasonalities 关于季节性的傅里叶序
- 4.5 Specifying Custom Seasonalities 指定自定义季节性
- 4.6 Seasonalities that depend on other factors 取决于其他因素的季节性
- 4.7 Prior scale for holidays and seasonality 节假日和季节性的优先比例
- 4.8 Additional regressors 附加回归变量
- 4.9 Coefficients of additional regressors 附加回归系数
- 五、Multiplicative Seasonality 乘法季节性
- 六、Uncertainty Intervals 不确定的区间
-
- 6.1 Uncertainty in the trend 趋势中的不确定性
- 6.2 Uncertainty in seasonality 季节性的不确定性
- 七、Outliers 异常值
- 七、非 Daily 数据
-
- 7.1 Sub-daily data 比天更细粒度的数据
- 7.2 Data with regular gaps 有规律间隔的数据
- 7.3 Monthly data 月度数据
- 7.4 Holidays with aggregated data 包含聚合数据的节假日
- 八、Diagnostics 诊断
-
- 8.1 Cross validation 交叉验证
- 8.2 Parallelizing cross validation 并行交叉验证
- 8.3 Hyperparameter tuning 超参数调整
-
- 8.3.1 Parameters that can be tuned
-
- changepoint_prior_scale
- seasonality_prior_scale
- holidays_prior_scale
- seasonality_mode
- 8.3.2 Maybe tune?
-
- changepoint_range
- 8.3.3 Parameters that would likely not be tuned
- 九、Handling Shocks 处理冲击
-
- 9.1 Case Study - Pedestrian Activity 行人活动
- 9.2 Default model without any adjustments 默认型号,无需任何调整
- 9.3 Treating COVID-19 lockdowns as a one-off holidays 把新冠肺炎封锁当作一次性假期
- 9.4 Sense checking the trend 感官检查趋势
- 9.5 Changes in seasonality between pre- and post-COVID 新冠感染前后的季节性变化
- 9.6 Further reading 更多资料
- 十、Additional Topics 其他主题
-
- 10.1 Saving models 保存模型参数
- 10.2 Flat trend 保持平稳趋势
- 10.3 Custom trends 自定义趋势
- 10.4 Updating fitted models 更新已拟合的模型
- 10.5 minmax scaling 最小最大缩放 (new in 1.1.5)
- 10.7 Inspecting transformed data 检查转换后的数据 (new in 1.1.5)
- 10.8 External references 其他库
- 十一、源码贡献
一、Quick Start
https://facebook.github.io/prophet/docs/quick_start.html#python-api
python3 install -m pip install prophet
pip uninstall pandas && pip install pandas==2.0.3 # 防止 https://github.com/facebook/prophet/issues/2492 panda 版本错误导致 ploy.py 无法画图的问题
pip install notebook ipywidgets
prophet 的输入是数据集,其有两列:ds 和 y。
- ds(datestamp)列需为 Pandas 库的格式,理想情况下,日期为YYYY-MM-DD,时间戳为YYYY-MM-DD HH:MM:SS。
- y 列需为数字,标识我们要预测的度量值。
作为一个例子,让我们看看 Peyton Manning 的维基百科页面(他是一个橄榄球教练)的,每天页面浏览量的时间序列。我们使用R中的 Wikipediatrend包收集了这些数据。
佩顿·曼宁提供了一个很好的例子,因为它展示了Prophet的一些特征,如多重季节性、不断变化的增长率,以及模拟特殊日子的能力(如曼宁的季后赛和超级碗出场)。csv 在这里。
其数据如下:
$ head example_wp_log_peyton_manning.csv
"ds","y"
"2007-12-10",9.59076113897809
"2007-12-11",8.51959031601596
"2007-12-12",8.18367658262066
"2007-12-13",8.07246736935477
"2007-12-14",7.8935720735049
$ python3 main.py
ds y
0 2007-12-10 9.590761
1 2007-12-11 8.519590
2 2007-12-12 8.183677
3 2007-12-13 8.072467
4 2007-12-14 7.893572
$
$ tail -n 5 example_wp_log_peyton_manning.csv
"2016-01-16",7.81722278550817
"2016-01-17",9.27387839278017
"2016-01-18",10.3337753460756
"2016-01-19",9.12587121534973
"2016-01-20",8.89137400948464
Prophet() 的构造函数可以传入参数,然后调用 fit() 调整参数,大概 5s。
可以用 Prophet.make_Future_dataframe() 获得一个合适的 dataframe,该 dataframe 可以延伸到未来指定的天数。默认情况下,它还将包括来自历史的日期,因此我们将看到模型也适合。
import pandas as pd
from prophet import Prophet
df = pd.read_csv('example_wp_log_peyton_manning.csv') # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv'
# df = pd.read_csv('a.csv')
# h = df.head()
# print(h)
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=3650)
t = future.tail()
print(t)
# result:
12:49:05 - cmdstanpy - INFO - Chain [1] start processing
12:49:05 - cmdstanpy - INFO - Chain [1] done processing
ds
6550 2026-01-13
6551 2026-01-14
6552 2026-01-15
6553 2026-01-16
6554 2026-01-17
Forecast() 方法将为未来的每一行分配一个预测值,将其命名为yhat。如果你传递历史日期,它将提供样本内的匹配。
下例的预测对象是一个新的 dataframe,它包括一个包含预测的列,以及组件和不确定性间隔的列。
import pandas as pd
from prophet import Prophet
df = pd.read_csv('example_wp_log_peyton_manning.csv') # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv'
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=3650)
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
# result:
ds yhat yhat_lower yhat_upper
6550 2026-01-13 4.838391 -7.642209 17.851909
6551 2026-01-14 4.674697 -7.957884 17.743943
6552 2026-01-15 4.691029 -7.637463 17.654419
6553 2026-01-16 4.714947 -7.876806 17.869388
6554 2026-01-17 4.493113 -7.915132 17.588772
可以用 Prophet.plot() 函数画图:
预测一年如下图:
预测 10 年如下图:
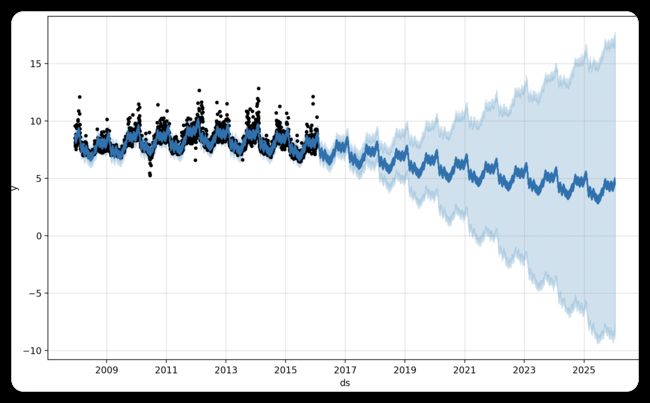
可以通过 Prophet.plot_components() 查看预测详情(默认会看到趋势、年、周的结果),如下:

可以需要单独安装 Plotly 4.0或更高版本,安装 notebook 和 ipywidgets。
import pandas as pd
from prophet import Prophet
df = pd.read_csv('example_wp_log_peyton_manning.csv') # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv'
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=3650)
forecast = m.predict(future)
from prophet.plot import plot_plotly, plot_components_plotly
plot_plotly(m, forecast).show() # This returns a plotly Figure
plot_components_plotly(m, forecast).show()


help(Prophet) or help(Prophet.fit) 可查看更多 api 的详情。
二、饱和预测
https://facebook.github.io/prophet/docs/saturating_forecasts.html
2.1 Forecasting Growth 预测增长
默认情况下,Prophet使用线性模型进行预测。在预测增长时,通常有一些最大可达到点:总市场规模、总人口规模等。这称为承载能力,预测应该在这一点饱和。
Prophet 可以用 logistic growth trend model 进行预测,可以指定 carrying capacity(承载能力)。我们用访问维基百科R语言页面的日志页面数量为例。
通过 cap 字段指定容量,这通常是由业务专家确定的。dataframes 的每一行都要有 cap 字段,且每行的 cap 值可以不同(例如市场如果变好,cap 可以增长)
df['cap'] = 8.5
我们像以前一样为未来预测制作数据帧,只是我们还必须指定未来的容量。在这里,我们保持 cap 与历史相同的值不变,并预测未来5年:
import pandas as pd
from prophet import Prophet
df = pd.read_csv('example_wp_log_peyton_manning.csv') # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv'
df['cap'] = 8.5
m = Prophet(growth='logistic')
m.fit(df)
future = m.make_future_dataframe(periods=365*5) # 产生未来的数据(只有日期, 没有值)
# print(future.tail())
future['cap'] =8.5
# print(future.tail())
fcst=m.predict(future)
fig = m.plot(fcst)
fig.show()
wait = input("PRESS ENTER TO CONTINUE.")

Logistic 函数的隐式最小值为0,并将以与容量饱和相同的方式在0饱和。还可以指定不同的饱和最小值。
2.2 Saturating Minimum 饱和最小值
Logistic增长模型还可以处理饱和最小值,它是用列底部指定的,其方式与上限列指定最大值的方式相同
import pandas as pd
from prophet import Prophet
df = pd.read_csv('example_wp_log_peyton_manning.csv') # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv'
df['y'] = 10 - df['y']
df['cap'] = 6
df['floor'] = 1.5
m = Prophet(growth='logistic')
m.fit(df)
future = m.make_future_dataframe(periods=365*5)
future['cap']=6
future['floor']=1.5
fcst=m.predict(future)
fig=m.plot(fcst)
fig.show()
wait = input("PRESS ENTER TO CONTINUE.")
要使用具有饱和最小值的逻辑增长趋势,还必须指定最大容量。
三、Trend Changepoints 趋势变化点
https://facebook.github.io/prophet/docs/trend_changepoints.html
您可能已经注意到,在本文档前面的示例中,实时序列的轨迹经常会发生突变。默认情况下,Prophet 将自动检测这些变化点,并允许趋势进行适当调整。然而,如果您希望对此过程有更好的控制(例如,Prophet错过了一次汇率变化,或者在历史上过多地适应了汇率变化),那么有几个输入参数可以使用。
3.1 Automatic changepoint detection in Prophet 自动检测变化点
Prophet通过首先指定允许速率变化的大量潜在变化点,来检测变化点。然后,它将稀疏优先放在速率变化的幅度上(相当于L1正则化) - 这本质上意味着Prophet有大量可能的速率变化的位置,但会使用尽可能少的位置。
就像 Quick Start 对佩顿·曼宁的预测一样,默认情况下,Prophet 指定25个可能的变化点,这些变化点统一放置在时间序列的前80%。如下图中的垂直线表示放置潜在变更点的位置:

尽管我们有很多地方的速率可能会发生变化,但由于先前的稀疏,这些变化点中的大多数都没有使用。我们可以通过绘制每个变化点的速率变化幅度图来了解这一点:

可以用参数 n_changepoints 设置潜在变化点的数量,但通过调整正则化可以更好地调整这一点。有意义变化点的位置可通过以下方式可视化:
import pandas as pd
from prophet import Prophet
from prophet.plot import add_changepoints_to_plot
df = pd.read_csv('example_wp_log_peyton_manning.csv') # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv'
df['cap']=8.5
m=Prophet(growth='logistic')
m.fit(df)
future=m.make_future_dataframe(periods=300)
future['cap']=8.5
fcst=m.predict(future)
fig=m.plot(fcst)
a=add_changepoints_to_plot(fig.gca(),m,fcst)
fig.show()
wait = input("PRESS ENTER TO CONTINUE.")
默认情况下,只对时间序列的前80%推断变化点,以便有足够的跑道来预测趋势,并避免在时间序列结束时过度拟合波动。此缺省值在许多情况下都适用,但不是所有情况下都适用,并且可以用 changepoint_range 参数进行更改。例如用 m=prophet(changepoint_range=0.9) 将潜在的变化点放置在时间序列的前90%。
3.2 Adjusting trend flexibility 调整趋势灵活性
如果趋势变化是过拟合(灵活性过高)或欠拟合(灵活性不足),则可以使用输入参数 changepoint_prior_scale 调整稀疏优先的强度。默认此参数为0.05。增加这一比例将使这一趋势更加灵活:
m = Prophet(changepoint_prior_scale=0.5)
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)
import pandas as pd
from prophet import Prophet
from prophet.plot import add_changepoints_to_plot
df = pd.read_csv('example_wp_log_peyton_manning.csv') # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv'
df['cap']=8.5
m=Prophet(growth='logistic', changepoint_prior_scale=0.5)
m.fit(df)
future=m.make_future_dataframe(periods=300)
future['cap']=8.5
fcst=m.predict(future)
fig=m.plot(fcst)
a=add_changepoints_to_plot(fig.gca(),m,fcst)
fig.show()
wait = input("PRESS ENTER TO CONTINUE.")
降低它将使这一趋势变得不那么灵活:
m = Prophet(changepoint_prior_scale=0.001) # changepoint_prior_scale: 调整自动变化点选择的灵活性的参数。较大的值将允许许多变点,较小的值将允许较少的变点。
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)
import pandas as pd
from prophet import Prophet
from prophet.plot import add_changepoints_to_plot
df = pd.read_csv('example_wp_log_peyton_manning.csv') # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv'
df['cap']=8.5
m=Prophet(growth='logistic', changepoint_prior_scale=0.01)
m.fit(df)
future=m.make_future_dataframe(periods=300)
future['cap']=8.5
fcst=m.predict(future)
fig=m.plot(fcst)
a=add_changepoints_to_plot(fig.gca(),m,fcst)
fig.show()
wait = input("PRESS ENTER TO CONTINUE.")
在可视化预测时,如果趋势似乎过高或过低,则可以根据需要调整此参数。在全自动设置中,有关如何调优此参数的建议,请参阅关于交叉验证的文档。
3.3 Specifying the locations of the changepoints 指定变更点的位置
如果愿意,可以用 changepoints 参数手动指定潜在变化点的位置,而不是使用自动变化点检测。
然后,将只允许在这些点处进行坡度更改,并使用与以前相同的稀疏正则化。
例如,人们可以自动创建一个点的网格,随后用一些已知可能发生变化的特定日期,来增强该网格。
另一个例子是,变更点可以完全限制为一小部分日期,如下所示:
m = Prophet(changepoints=['2014-01-01'])
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)
import pandas as pd
from prophet import Prophet
from prophet.plot import add_changepoints_to_plot
df = pd.read_csv('example_wp_log_peyton_manning.csv') # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv'
df['cap']=8.5
m=Prophet(growth='logistic', changepoint_prior_scale=0.01, changepoints=['2014-01-01'])
m.fit(df)
future=m.make_future_dataframe(periods=300)
future['cap']=8.5
fcst=m.predict(future)
fig=m.plot(fcst)
a=add_changepoints_to_plot(fig.gca(),m,fcst)
fig.show()
wait = input("PRESS ENTER TO CONTINUE.")
四、Seasonality, Holiday Effects, And Regressors 季节、节假日、回归
https://facebook.github.io/prophet/docs/seasonality,_holiday_effects,_and_regressors.html
4.1 Modeling Holidays and Special Events 对假日和特殊活动进行建模
如果您有想要建模的节假日或其他重复性事件,则必须为它们创建 dataframe。它有两列(hodiday 和 ds),每一次假日都有一行。它必须包括节日的所有发生,既包括过去(追溯到历史数据),也包括未来(只要做出预测)。如果它们不会在未来重复,Prophet将对它们进行建模,然后不会将它们包括在预测中。
还可以指定 lower_window 和 upper_window 列,它们可以把假期延长到日期周围的 [lower_window, upper_window] 天。
- 比如,如果想在圣诞节的基础上,额外指定平安夜,可以指定 lower_window=-1,upper_window=0。
- 比如,如果想在感恩节的基础上,额外指定黑色星期五,可以指定 lower_window=0,upper_window=1。
- 可以增加 prior_scale 列,来分别为每个假日设置先前的刻度,如下所述。
在这里,我们创建一个 dataframe,其中包括佩顿·曼宁所有季后赛出场的日期:
# Python
playoffs = pd.DataFrame({
'holiday': 'playoff',
'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
superbowls = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
holidays = pd.concat((playoffs, superbowls))
上面我们把 superbowl days 包括在 playoff games 和 superbowl games 中。这意味着 superbowl effect 将是 playoff effect 之上的额外加分。
通过 holidays 参数,可以应用,如下例:
m = Prophet(holidays=holidays)
forecast = m.fit(df).predict(future)
完整示例如下:
import pandas as pd
from prophet import Prophet
# set pandas display options
pd.set_option('display.expand_frame_repr', False)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
# read
df=pd.read_csv('example_wp_log_peyton_manning.csv')
# holidays
playoffs=pd.DataFrame({
'holiday': 'playoff',
'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
print(playoffs)
superbowls = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
print(superbowls)
holidays = pd.concat((playoffs, superbowls))
print(holidays)
# forecast
m = Prophet(holidays=holidays)
m.fit(df)
future = m.make_future_dataframe(periods=365)
print(future.tail())
# Reset display options to default
# pd.reset_option('display.expand_frame_repr')
# pd.reset_option('display.max_columns')
# pd.reset_option('display.width')
forecast = m.predict(future)
print(forecast.tail())
# fig = m.plot(forecast)
# fig.show()
print(forecast['playoff'])
print(forecast['superbowl'])
print(forecast['playoff'] + forecast['superbowl'])
print((forecast['playoff'] + forecast['superbowl']).abs())
print((forecast['playoff'] + forecast['superbowl']).abs() > 0)
print(forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0])
print(forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:])
print(1)
fig = m.plot_components(forecast)
fig.show()
wait = input("PRESS ENTER TO CONTINUE.")
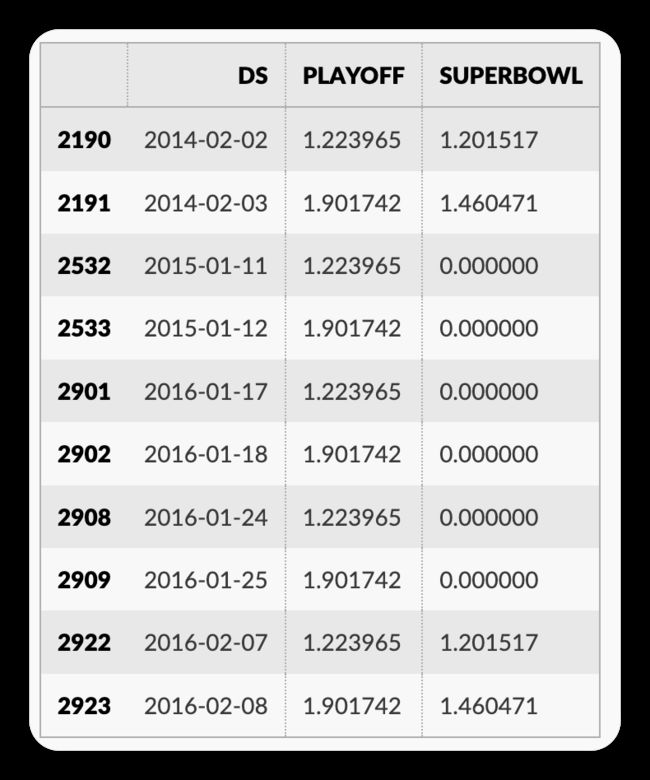
从 forecast 数据结构中,可看到应用 holiday 的效果:
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]
从 components plot 可看到 holiday effect,如下图, playoff 有一波峰值,super bowl 有更大的一波峰值。
fig = m.plot_components(forecast)

可以通过 from prophet.plot import plot_forecast_component 和 plot_forecast_component(m, forecast, ‘superbowl’) 只画 superbowl 相关的图。
4.2 Built-in Country Holidays 内置的国家放假日
可以用内置的 add_country_holidays() 函数,可以指定国家,其是通过 https://github.com/vacanza/python-holidays/ 仓库获取的假日列表。
m = Prophet(holidays=holidays)
m.add_country_holidays(country_name="CN")
m.fit(df)
print(m.train_holiday_names)
# result:
0 playoff
1 superbowl
2 New Year's Day
3 Chinese New Year (Spring Festival)
4 Labor Day
...
82 Day off (substituted from 02/15/2015)
83 Day off (substituted from 02/28/2015)
84 70th Anniversary of the Victory of the Chinese...
85 Day off (substituted from 09/06/2015)
86 Day off (substituted from 10/10/2015)
Length: 87, dtype: object
完整代码如下:
import pandas as pd
from prophet import Prophet
df = pd.read_csv("example_wp_log_peyton_manning.csv")
playoffs = pd.DataFrame(
{
"holiday": "playoff",
"ds": pd.to_datetime(
[
"2008-01-13",
"2009-01-03",
"2010-01-16",
"2010-01-24",
"2010-02-07",
"2011-01-08",
"2013-01-12",
"2014-01-12",
"2014-01-19",
"2014-02-02",
"2015-01-11",
"2016-01-17",
"2016-01-24",
"2016-02-07",
]
),
"lower_window": 0,
"upper_window": 1,
}
)
superbowls = pd.DataFrame(
{
"holiday": "superbowl",
"ds": pd.to_datetime(["2010-02-07", "2014-02-02", "2016-02-07"]),
"lower_window": 0,
"upper_window": 1,
}
)
holidays = pd.concat((playoffs, superbowls))
m = Prophet(holidays=holidays)
m.add_country_holidays(country_name="US").fit(df)
future = m.make_future_dataframe(periods=365)
forecast = m.predict(future)
fig = m.plot_components(forecast)
fig.show()
wait = input("wait")
从下图的 holidays 部分可看到节假日:

4.3 Holidays for subdivisions 详细的节日
可通过 make_holidays_df() 函数创建自定义的 holidays DataFrames,例如 python 的 holidays 库的数据,可以传入 Prophet() 的构造函数。
import pandas as pd
from prophet import Prophet
from prophet.make_holidays import make_holidays_df
df = pd.read_csv("example_wp_log_peyton_manning.csv")
cn_holidays = make_holidays_df(year_list=[2022 + i for i in range(10)], country="CN")
h = cn_holidays.head(n=100)
print(h)
m_cn = Prophet(holidays=cn_holidays)
# result:
ds holiday
0 2024-01-01 New Year's Day
1 2024-02-10 Chinese New Year (Spring Festival)
2 2024-02-11 Chinese New Year (Spring Festival)
3 2024-02-12 Chinese New Year (Spring Festival)
4 2024-05-01 Labor Day
.. ... ...
72 2023-05-02 Day off (substituted from 04/23/2023)
73 2023-05-03 Day off (substituted from 05/06/2023)
74 2023-06-23 Day off (substituted from 06/25/2023)
75 2023-10-05 Day off (substituted from 10/07/2023)
76 2023-10-06 Day off (substituted from 10/08/2023)
[77 rows x 2 columns]
4.4 Fourier Order for Seasonalities 关于季节性的傅里叶序
季节性使用部分傅立叶和来估计。有关完整的详细信息,请参阅这篇论文,维基百科上的这张图说明了部分傅里叶和如何逼近任意周期信号。

部分和(顺序)中的项数是一个参数,用于确定季节性变化的速度。
为了说明这一点,可以用 QuickStart 小节 Peyton Manning 里的数据。年度季节性的默认傅立叶阶数是10,这会产生以下拟合:
from prophet.plot import plot_yearly
m = Prophet().fit(df)
a = plot_yearly(m)

缺省值通常是适当的,但当季节性需要适应更高频率的变化时,可以增加这些值,并且通常不那么平滑。实例化模型时,可以为每个内置季节性指定傅立叶阶数,此处将其增加到20:
from prophet.plot import plot_yearly
m = Prophet(yearly_seasonality=20).fit(df)
a = plot_yearly(m)

增加傅立叶项的数量可以使季节性适应变化更快的周期,但也可能导致过度拟合:N个傅立叶项对应于用于建模周期的2N个变量。
4.5 Specifying Custom Seasonalities 指定自定义季节性
如果时间序列长度超过两个周期,则Prophet将默认符合每周和每年的季节性。它还将 fit daily seasonality for a sub-daily time series。可以用 add_easonality() 添加其他季节性(每月、每季度、每小时)。
此函数的输入是名称、季节性的周期(以天为单位)和季节性的傅立叶阶数。
作为参考,默认情况下,Prophet 使用傅立叶阶数3表示每周季节性,使用10表示年度季节性。add_seasonality 的一个可选输入是该季节性组件的先验比例-这一点将在下文中讨论。
下文仍用 Quick Start 的 Peython Manning 数据,但将 weekly seasonality 替换为 monthly seasonality。monthly seasonality 会出现在下图中:
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)
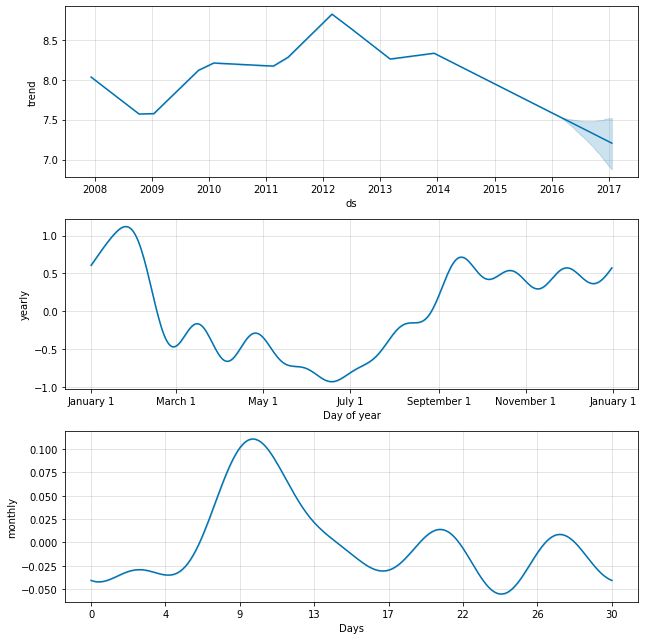
4.6 Seasonalities that depend on other factors 取决于其他因素的季节性
在某些情况下,季节性可能取决于其他因素,例如夏季的每周季节性模式与一年中其余时间不同,或者周末与工作日的每日季节性模式不同。这些类型的季节性可以使用条件季节性来建模。
考虑一下《快速入门》中的佩顿·曼宁的例子。默认的每周季节性假设每周季节性的模式在一年中是相同的,但我们预计每周季节性的模式在赛季(每个周日都有比赛)和淡季期间会有所不同。我们可以使用条件季节性来构造单独的旺季和淡季每周季节性。
首先,我们在数组中添加一个布尔列,指示每个日期是在旺季还是淡季:
def is_nfl_season(ds):
date = pd.to_datetime(ds)
return (date.month > 8 or date.month < 2)
df['on_season'] = df['ds'].apply(is_nfl_season)
df['off_season'] = ~df['ds'].apply(is_nfl_season)
然后,我们禁用内置的每周季节性,并将其替换为两个每周季节性,并将这些列指定为条件。这意味着季节性将仅应用于 condition_name 列为True的日期。还要在 future dataframe 中添加此列。
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='weekly_on_season', period=7, fourier_order=3, condition_name='on_season')
m.add_seasonality(name='weekly_off_season', period=7, fourier_order=3, condition_name='off_season')
future['on_season'] = future['ds'].apply(is_nfl_season)
future['off_season'] = ~future['ds'].apply(is_nfl_season)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)

这两种季节性现在都出现在上面的组成部分曲线图中。我们可以看到,在每个周日都有比赛的赛季,周日和周一有很大的增长,而在休赛期完全没有。
4.7 Prior scale for holidays and seasonality 节假日和季节性的优先比例
如果您发现假期过多,则可以使用参数 holidays_prior_scale 调整其先前比例以使其平滑。默认情况下,该参数为10,这提供的正则化非常少。减小此参数会抑制节日效果:
m = Prophet(holidays=holidays, holidays_prior_scale=0.05).fit(df)
forecast = m.predict(future)
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]

与以前相比,假期效应的幅度有所减弱,特别是对超级碗来说,它的观测次数最少。有一个参数 seasonality_prior_scale,它类似地调整季节性模型对数据的拟合程度。
通过在 holidays 表框中包含一列 prior_scale,可以为各个假日单独设置优先级。单个季节性的 prior scale 可以作为参数传递给 add_seasonality()。例如,可以使用以下公式设置每周季节性的先验尺度:
m = Prophet()
m.add_seasonality(name='weekly', period=7, fourier_order=3, prior_scale=0.1)
4.8 Additional regressors 附加回归变量
可以用 add_regressor() 将其他回归量添加到模型的线性部分。具有回归量值的列,需要同时出现在 拟合 和 预测 dataframe中。例如,我们可以在NFL赛季的周日增加一个额外的效果。在 components 图上,此效果将显示在 ‘Extra_Regresors’ 图中:
def nfl_sunday(ds):
date = pd.to_datetime(ds)
if date.weekday() == 6 and (date.month > 8 or date.month < 2):
return 1
else:
return 0
df['nfl_sunday'] = df['ds'].apply(nfl_sunday)
m = Prophet()
m.add_regressor('nfl_sunday')
m.fit(df)
future['nfl_sunday'] = future['ds'].apply(nfl_sunday)
forecast = m.predict(future)
fig = m.plot_components(forecast)
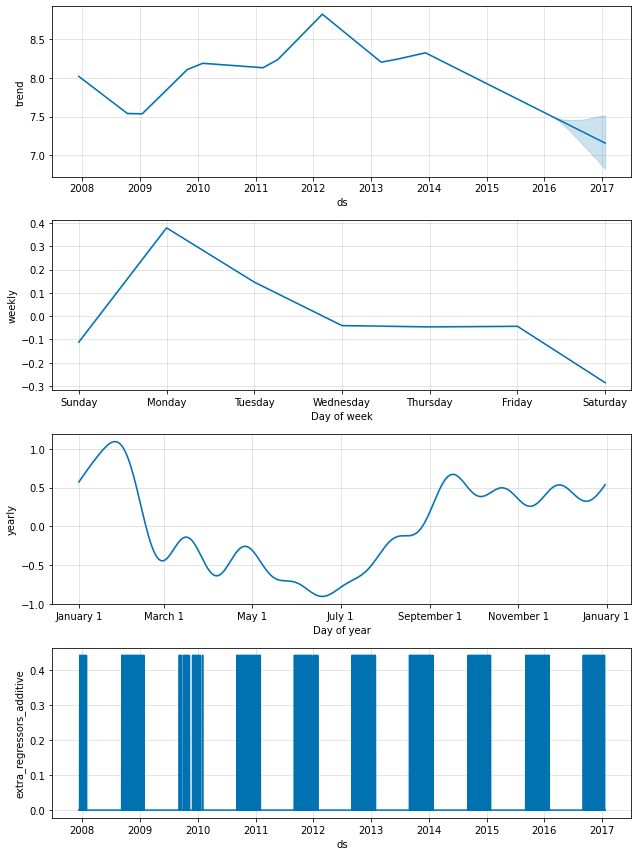
NFL星期日也可以使用上面描述的 “holidays” interface 来处理,通过创建过去和未来NFL星期日的列表。add_regressor() 为定义额外的线性回归量提供了一个更通用的接口,特别是不要求回归量是二进制指示符。另一个时间序列可以用作回归量,尽管它的未来值必须是已知的。
这个笔记本
展示了一个在自行车使用预测中,使用天气因素作为额外回归量的例子,并提供了一个很好的说明如何将其他时间序列作为额外回归量。
add_regressor() 具有可选参数,用于指定先验尺度(默认情况下使用假日先验尺度)以及回归量是否标准化-请参阅Python中的文档字符串帮助(Prophet.add_regressor)。请注意,必须在模型拟合之前添加回归变量。如果回归量在整个历史中是恒定的,那么Prophet也会产生错误,因为没有任何东西可以从中拟合。
对于历史和未来日期,额外的回归变量必须是已知的。因此,它要么是已经知道未来价值的东西(比如NFL_SUNDAY),要么是其他地方已经单独预测的东西。上面链接的笔记本中,使用的天气回归变量是一个很好的例子,它具有预测未来值的额外回归变量。
人们还可以将另一个用时间序列模型(如Prophet)预测的时间序列用作回归变量。例如,如果r(T)被包含为y(T)的回归变量,则可以使用Prophet来预测r(T),然后在预测y(T)时将该预测作为未来值插入。关于这种方法需要注意的一点是:除非r(T)比y(T)更容易预测,否则这种方法可能不会有用。这是因为r(T)的预测误差将产生y(T)的预测误差。这可能有用的一种设置是在分层时间序列中,其中顶层预测具有较高的信噪比,因此更容易预测。它的预测可以包括在每个较低级别系列的预测中。
额外的回归变量被放入模型的线性分量中,因此基本模型是时间序列依赖于额外的回归变量作为加性或乘性因素(参见下一节的乘性)。
4.9 Coefficients of additional regressors 附加回归系数
要提取额外回归变量的Beta系数,请在已拟合的模型上使用实用函数 regressor_cofficients(来自profiet。实用程序在Python中导入regressor_cofficients)。每个回归变量的估计贝塔系数大致代表回归量值单位增加时预测值的增加(请注意,返回的系数始终在原始数据的范围内)。如果指定了MCMC_Samples,则还会返回每个系数的可信区间,这有助于确定回归变量对模型是否有意义(包含0值的可信区间表示回归变量没有意义)。
五、Multiplicative Seasonality 乘法季节性
默认情况下,Prophet符合附加的季节性,这意味着季节性的影响被添加到趋势中,以获得预测。这个航空乘客数量的时间序列是季节性加法不起作用的一个例子:
import pandas as pd
from prophet import Prophet
df = pd.read_csv("example_air_passengers.csv") # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_air_passengers.csv
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=50, freq="MS")
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()
wait = input("wait")

这个时间序列有明确的年周期,但预报中的季节性在时间序列开始时太大,在时间序列结束时太小。在这个时间序列中,季节性并不像Prophet假设的那样是一个恒定的相加因素,而是随着趋势而增长。这是一种乘性季节性。
Prophet 可以通过在输入参数中设置 seasonality_mode=‘multiplicative’ 来模拟乘性季节性:
m = Prophet(seasonality_mode='multiplicative')
m.fit(df)
forecast = m.predict(future)
fig = m.plot(forecast)
import pandas as pd
from prophet import Prophet
df = pd.read_csv("example_air_passengers.csv") # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_air_passengers.csv
m = Prophet(seasonality_mode='multiplicative')
m.fit(df)
future = m.make_future_dataframe(periods=50, freq="MS")
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()
wait = input("wait")

component plot 将季节性显示为趋势的百分比:
fig = m.plot_components(forecast)

如果 seasonality_mode=‘multiplicative’,则假日效应也将被建模为乘法效应。默认情况下,任何添加的季节性或额外的回归变量都将使用 seasonality_mode 设置的值,但可以通过在添加季节性或回归变量时将 mode=‘additive’ 或mode=‘multiplicative’ 指定为参数来覆盖。
例如,下文将 built-in seasonalities 设置为乘性,但包括相加的季度季节性和相加的回归变量:
m = Prophet(seasonality_mode='multiplicative')
m.add_seasonality('quarterly', period=91.25, fourier_order=8, mode='additive')
m.add_regressor('regressor', mode='additive')
相加和相乘的额外回归变量将显示在组件图的不同面板中。然而,请注意,它几乎不太可能混合存在相加和相乘的季节性因素,因此通常只有在有理由预期会出现这种情况时才会使用这种方法。
六、Uncertainty Intervals 不确定的区间
默认情况下,Prophet将返回预测 yhat 的不确定间隔。在这些不确定区间背后有几个重要的假设。
预测中的不确定性有三个来源:趋势的不确定性,季节性估计的不确定性,以及额外的观测噪音。
6.1 Uncertainty in the trend 趋势中的不确定性
预测中最大的不确定性来源是未来趋势变化的可能性。我们在本文档中已经看到的时间序列显示了历史上明显的趋势变化。Prophet 能够发现并适应这些变化,但我们应该怎么预期未来的趋势变化?这是不可能确定的。
所以我们做了我们能做的最合理的事情,我们假设未来会看到类似的趋势变化,就像历史一样。特别是,我们假设未来趋势变化的平均频率和幅度与我们在历史上观察到的相同。
这种测量不确定性的方法的一个特性是,通过增加 changepoint_prior_scale 来允许更高的 rate 灵活性,将增加预测的不确定性。这是因为,如果我们在历史上模拟更多的rate 变化,那么我们将在未来预期更多,并使不确定性区间成为过度拟合的有用指标。
可以用参数 interval_width 设置 uncertain intervals(不确定区间)的宽度(默认为80%):
forecast = Prophet(interval_width=0.95).fit(df).predict(future)
同样, these intervals assume that the future will see the same frequency and magnitude(振幅) of rate changes as the past。This assumption is probably not true, so you should not expect to get accurate coverage on these uncertainty intervals。
6.2 Uncertainty in seasonality 季节性的不确定性
默认情况下,Prophet将只返回趋势和观察噪声中的不确定性。为了获得季节性的不确定性,你必须进行全面的贝叶斯抽样。这是用参数 mcmc.samples(默认值为0)完成的。下例对来自Quickstart的Peyton Manning数据的前六个月进行了分析:
m = Prophet(mcmc_samples=300)
forecast = m.fit(df, show_progress=False).predict(future)
这用MCMC抽样取代了典型的MAP估计,并且可能需要更长的时间,这取决于观测的数量–预计是几分钟而不是几秒。如果进行完全抽样,则在绘制季节性分量图时,您将看到它们的不确定性:
fig = m.plot_components(forecast)

可以用 m.recrective_samples(future) 方法访问原始的后验预测样本。
七、Outliers 异常值
异常值可以通过两种主要方式影响先知的预测。在这里,我们对之前记录的维基百科访问R页面的次数进行预测,但有一组坏数据:
import pandas as pd
from prophet import Prophet
df = pd.read_csv("example_wp_log_R_outliers1.csv") # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_R_outliers1.csv
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=1096)
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()
wait = input("wait")
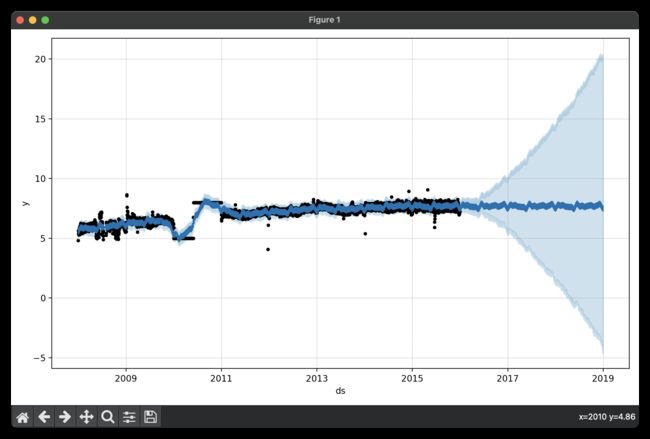
趋势预测似乎是合理的,但不确定性区间似乎太宽了。Prophet能够处理历史上的异常值,但只能通过将它们与趋势变化相匹配。然后,不确定性模型预计未来的趋势变化具有类似的幅度。
处理离群值的最好方法是删除它们,因为Prophet可以容忍缺失的数据。如果把历史异常值设置为 NA,保留 future 的 dates,是可以正常预测出 future 的结果的。
df.loc[(df['ds'] > '2010-01-01') & (df['ds'] < '2011-01-01'), 'y'] = None
model = Prophet().fit(df)
fig = model.plot(model.predict(future))
import pandas as pd
from prophet import Prophet
df = pd.read_csv(
"example_wp_log_R_outliers1.csv"
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_R_outliers1.csv
df.loc[(df["ds"] > "2010-01-01") & (df["ds"] < "2011-01-01"), "y"] = None
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=1096)
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()
wait = input("wait")

在上面的例子中,异常值扰乱了不确定性估计,但没有影响主要预测。情况并不总是如此,就像本例中添加的异常值一样:
df = pd.read_csv('example_wp_log_R_outliers2.csv') # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_R_outliers2.csv
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=1096)
forecast = m.predict(future)
fig = m.plot(forecast)
这里,2015年6月的一组极端异常值扰乱了季节性估计,因此他们的影响将永远影响到未来。同样,正确的方法是移除它们。
df.loc[(df['ds'] > '2015-06-01') & (df['ds'] < '2015-06-30'), 'y'] = None
m = Prophet().fit(df)
fig = m.plot(m.predict(future))
import pandas as pd
from prophet import Prophet
df = pd.read_csv(
"example_wp_log_R_outliers2.csv"
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_R_outliers2.csv
df.loc[(df["ds"] > "2015-06-01") & (df["ds"] < "2015-06-30"), "y"] = None
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=1096)
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()
wait = input("wait")

七、非 Daily 数据
7.1 Sub-daily data 比天更细粒度的数据
Prophet 可以通过在 ds列 中传递带有时间戳的数据帧,来对具有次日观测的时间序列进行预测。时间戳的格式应为YYYY-MM-DD HH:MM:SS-请参阅此处的示例CSV。
使用 sub-daily data 时,将自动匹配 daily seasonality。下例我们将 Prophet 与5分钟分辨率的数据(Yosemite的每日温度)进行匹配:
import pandas as pd
from prophet import Prophet
df = pd.read_csv(
"example_yosemite_temps.csv"
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_yosemite_temps.csv
m = Prophet(changepoint_prior_scale=0.01).fit(df)
future = m.make_future_dataframe(periods=300, freq="H")
fcst = m.predict(future)
fig = m.plot(fcst)
fig.show()
wait = input("wait")
每日季节性将显示在成分图中:
fig = m.plot_components(fcst)

7.2 Data with regular gaps 有规律间隔的数据
假设上面的数据集只有从12a到6a的观测:
import pandas as pd
from prophet import Prophet
df = pd.read_csv("example_yosemite_temps.csv")
df2 = df.copy()
df2["ds"] = pd.to_datetime(df2["ds"])
df2 = df2[df2["ds"].dt.hour < 6]
m = Prophet().fit(df2)
future = m.make_future_dataframe(periods=300, freq="H")
fcst = m.predict(future)
fig = m.plot(fcst)
fig.show()
wait = input("wait")
预测似乎相当糟糕,未来的波动比历史上看到的要大得多。这里的问题是,我们将每日周期与只有一天中部分时间(12a到6a)数据的时间序列进行了匹配。因此,每天的季节性在一天的其余时间是不受限制的,因此不能很好地估计。
解决方案是只对有历史数据的时间窗口进行预测。这里,这意味着将 future dataframe的时间限制在12a到6a之间:
future2 = future.copy()
future2 = future2[future2['ds'].dt.hour < 6]
fcst = m.predict(future2)
fig = m.plot(fcst)
import pandas as pd
from prophet import Prophet
df = pd.read_csv("example_yosemite_temps.csv")
df2 = df.copy()
df2["ds"] = pd.to_datetime(df2["ds"])
df2 = df2[df2["ds"].dt.hour < 6]
m = Prophet().fit(df2)
future = m.make_future_dataframe(periods=300, freq="H")
future2 = future.copy()
future2 = future2[future2["ds"].dt.hour < 6]
fcst = m.predict(future2)
fig = m.plot(fcst)
fig.show()
wait = input("wait")
同样的原理也适用于数据中有规律缺口的其他数据集。例如,如果历史记录仅包含工作日,则应仅对工作日进行预测,因为周末的每周季节性不会被很好地估计。
7.3 Monthly data 月度数据
您可以使用Prophet来拟合月度数据。然而,底层模型是连续时间的,这意味着如果你将模型与月度数据拟合,然后要求每日预测,你可能会得到奇怪的结果。以下是我们对未来10年美国零售额的预测:
import pandas as pd
from prophet import Prophet
df = pd.read_csv(
"example_retail_sales.csv"
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_retail_sales.csv
m = Prophet(seasonality_mode="multiplicative").fit(df)
future = m.make_future_dataframe(periods=3652)
fcst = m.predict(future)
fig = m.plot(fcst)
fig.show()
wait = input("wait")


从上面来看,这是同一个问题,其中数据集具有规则的间隙。当我们拟合每年的季节性时,它只有每个月第一天的数据,其余日期的季节性成分是无法识别的和过度匹配的。这一点可以通过做 MCMC 来清楚地看到季节性的不确定性:
m = Prophet(seasonality_mode='multiplicative', mcmc_samples=300).fit(df, show_progress=False)
fcst = m.predict(future)
fig = m.plot_components(fcst)
import pandas as pd
from prophet import Prophet
df = pd.read_csv(
"example_retail_sales.csv"
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_retail_sales.csv
m = Prophet(seasonality_mode="multiplicative", mcmc_samples=300).fit(
df, show_progress=False
)
future = m.make_future_dataframe(periods=3652)
fcst = m.predict(future)
fig = m.plot(fcst)
fig.show()
wait = input("wait")
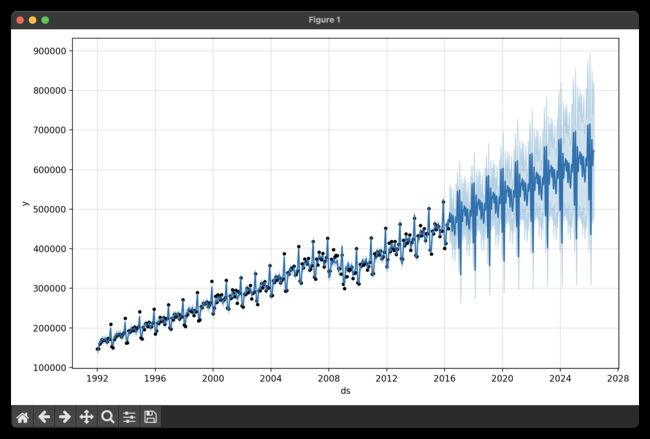
fig = m.plot_components(fcst)

在有数据点的每个月开始时,季节性的不确定性很低,但在两者之间具有非常高的后验方差。在将Prophet与月度数据进行拟合时,仅进行月度预测,这可以通过将频率传递到Make_Future_DataFrame中来实现:
future = m.make_future_dataframe(periods=120, freq='MS')
fcst = m.predict(future)
fig = m.plot(fcst)
import pandas as pd
from prophet import Prophet
df = pd.read_csv(
"example_retail_sales.csv"
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_retail_sales.csv
m = Prophet(seasonality_mode="multiplicative", mcmc_samples=300).fit(
df, show_progress=False
)
future = m.make_future_dataframe(periods=120, freq="MS") # MS 是月份开始的意思
fcst = m.predict(future)
fig = m.plot(fcst)
fig.show()
wait = input("wait")

在Python中,频率可以是pandas频率字符串列表中的任何字符串:https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#timeseries-offset-aliases。请注意,这里使用的MS是月份开始,这意味着数据点位于每个月的开始。
在月度数据中,年度季节性也可以用二进制额外回归变量来建模。特别是,该模型可以使用12个额外的回归变量,如 is_jan、is_feb等,其中,如果日期在1月,is_jan为1,否则为0。这种方法将避免上文所见的月内无法识别的情况。如果要添加每月额外的回归变量,请确保使用 yearly_seasonality=False。
7.4 Holidays with aggregated data 包含聚合数据的节假日
假日效果适用于指定假日的特定日期。对于已聚合到每周或每月频率的数据,不在数据中使用的特定日期的假期将被忽略:例如,每周时间序列中的周一假期,其中每个数据点都在周日。要在模型中包括假期效果,需要将假期移动到历史数据框中需要效果的日期。请注意,对于每周或每月的聚合数据,许多假期的影响将被年度季节性很好地捕捉到,因此,添加假期可能只对整个时间序列中不同周发生的假期是必要的。
八、Diagnostics 诊断
8.1 Cross validation 交叉验证
Prophet 包括时间序列交叉验证功能,以使用历史数据衡量预测误差。这是通过在历史中选择截止点,并仅使用截止到该截止点的数据对每个截止点进行模型拟合来实现的。然后我们可以将预测值与实际值进行比较。
此图显示了在Peyton Manning数据集上模拟的历史预测,其中该模型适用于5年的初始历史,并在一年范围内进行了预测。Prophet论文 对模拟的历史预报作了进一步描述。

可以用 cross_validation() 函数自动为多个历史 cutoffs 做交叉验证。
- 通过 horizon 参数指定,预测时段
- 通过 initial 参数指定,初始时段(历史数据时段)
- 通过 period 参数指定,各 cutoffs 的间隔。默认情况下,period 会设置为 horizon 的三倍,每隔半个 horizon 进行一次 cutoff。
cross_validation() 的输出是一个 dataframe,其中包含每个模拟预测日期和每个截止日期的,真实值y,和样本外预测值yhat。通常对 [cutoff, cutoff + horizon] 之间的每个观测点进行预测。输出的 dataframe 可以用来计算 yhat 相比 y 的误差。
下例,用交叉验证来评估365天的预测性能,从第一个 cutoff 的第730天训练数据开始,然后每180天进行一次预测。在这8年的时间序列中,这对应于11个总预测。
from prophet.diagnostics import cross_validation
df_cv = cross_validation(m, initial='730 days', period='180 days', horizon = '365 days')
df_cv.head()

initial、period、horizon 字符串参数,应该用 pandas 的 Timedelta 的格式,其接受天或更短的时间单位。
cutoffs 参数可以指定多项,例如三个 cutoff,每个相隔 6 个月,可设置如下:
cutoffs = pd.to_datetime(['2013-02-15', '2013-08-15', '2014-02-15'])
df_cv2 = cross_validation(m, cutoffs=cutoffs, horizon='365 days')
performance_metrics() 可用于计算预测的一些有用统计信息(yhat、yhat_lower和yhat_upper,相对 y 的误差)。
计算的统计量是均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、中位数绝对百分比误差(MDAPE)以及yhat下限和yhat上限估计的覆盖率。这些是在通过 horizon(df - cutoff) 计算得到的序列基础上,在 df_cv 中的预测的滚动窗口上计算出的。
默认情况下,每个窗口中将包含10%的预测,但这可以通过 rolling_window 参数进行更改。
from prophet.diagnostics import performance_metrics
df_p = performance_metrics(df_cv)
df_p.head()

交叉验证性能指标可使用 plot_cross_validation_metric 进行可视化。下图中,点表示 df_cv 中每个预测的绝对百分比误差。蓝线显示了MAPE,平均值是通过各点的滚动窗口计算出的。我们看到,对于这个预测,一个月后的预测误差约5%,而一年后的预测误差会增加到约11%。

图中滚动窗口的大小可以用可选参数 rolling_window 更改,该参数指定要在每个滚动窗口中使用的预测比例。缺省值为0.1,对应于每个窗口中包含的df_cv中 10% 的行;增加此值将导致图中的平均曲线更平滑。
initial 阶段应该足够长,以捕获模型的所有组成部分,特别是季节性和额外的回归变量:每年的季节性至少一年,每周的季节性至少一周,等等。
8.2 Parallelizing cross validation 并行交叉验证
通过设置 parallel 关键字,还可以在 Python 中以并行模式运行交叉验证。支持四种模式
-
parallel=None (Default, no parallelization)
-
parallel=“processes”
-
parallel=“threads”
-
parallel=“dask”
-
对于不太大的问题,我们建议使用parallel=“processes”。当并行交叉验证可以在一台机器上完成时,它将达到最高性能。
-
对于大型问题,可以使用 daks集群 在多台机器上进行交叉验证。需要自行需要单独安装DASK,因为它不会与 Prophet 一起安装。
from dask.distributed import Client
client = Client() # connect to the cluster
df_cv = cross_validation(m, initial='730 days', period='180 days', horizon='365 days', parallel="dask")
8.3 Hyperparameter tuning 超参数调整
交叉验证可用于调整模型的超参数,如 changepoint_prior_scale 和 seasonality_prior_scale。下面给出了一个Python示例,其中包含这两个参数的4x4网格,并对 cutoffs 进行了并行化。在这里,参数是根据30天的平均RMSE 进行评估的,但不同的性能指标可能适用于不同的问题。
import itertools
import numpy as np
import pandas as pd
param_grid = {
'changepoint_prior_scale': [0.001, 0.01, 0.1, 0.5],
'seasonality_prior_scale': [0.01, 0.1, 1.0, 10.0],
}
# Generate all combinations of parameters
all_params = [dict(zip(param_grid.keys(), v)) for v in itertools.product(*param_grid.values())]
rmses = [] # Store the RMSEs for each params here
# Use cross validation to evaluate all parameters
for params in all_params:
m = Prophet(**params).fit(df) # Fit model with given params
df_cv = cross_validation(m, cutoffs=cutoffs, horizon='30 days', parallel="processes")
df_p = performance_metrics(df_cv, rolling_window=1)
rmses.append(df_p['rmse'].values[0])
# Find the best parameters
tuning_results = pd.DataFrame(all_params)
tuning_results['rmse'] = rmses
print(tuning_results)
可以设置待调参数,统一测试效果,可以肉眼查看各参数效果,也可以直接选出最好的参数:
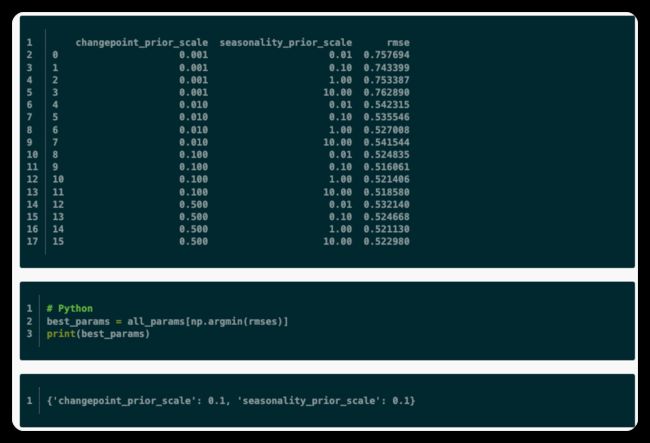
或者,可以通过并行化上面的循环来跨参数组合进行并行化。Prophet模型有许多可以考虑调优的输入参数。以下是一些关于超参数调优的一般性建议,这可能是一个很好的起点。
8.3.1 Parameters that can be tuned
changepoint_prior_scale
这可能是影响最大的参数。它决定了趋势的灵活性,特别是趋势变化点的变化幅度。如本文档中所述,如果它太小,趋势将不太适合,本应使用趋势变化建模的方差最终将使用噪声项进行处理。如果它太大,趋势就会过度匹配,在最极端的情况下,你可能会得到年度季节性的趋势。缺省值0.05时适用于许多时间序列,但这是可以调整的;[0.001,0.5]的范围可能是正确的。像这样的参数(正则化惩罚;这实际上是 lasso 惩罚)通常是在对数尺度上进行调整的。
seasonality_prior_scale
此参数控制季节性的灵活性。同样,较大的值可以使季节性适应较大的波动,较小的值则会缩小季节性的幅度。缺省值为10.0,这基本上不适用任何正则化。这是因为我们很少在这里看到过拟合(存在固有的正则化,因为它是用截断的傅立叶级数建模的,所以它本质上是低通滤波的)。调整它的合理范围可能是[0.01,10];当设置为0.01时,您会发现季节性的幅度被迫非常小。这在对数标度上也是有意义的,因为它实际上是像岭回归一样的L2惩罚。
holidays_prior_scale
这控制了灵活性,以适应假日效果。与 seasonality_prior_scale 类似,它的缺省值为10.0,这基本上不应用正则化,因为我们通常有多个假期观测,并且可以很好地估计它们的影响。这也可以在[0.01,10]的范围内调整,就像使用 seasonality_prior_scale 一样。
seasonality_mode
Options are [‘additive’, ‘multiplicative’]. Default is ‘additive’, 但许多商业领域都设置为 ‘multiplicative’。仅通过查看时间序列并查看季节性波动的大小是否随着时间序列的大小而增长(请参阅文档的 multiplicative seasonality 部分)来识别这一点是最好的,但当这不可能时,可以对其进行调整。
8.3.2 Maybe tune?
changepoint_range
这是允许趋势改变的历史比例。这默认为0.8,即历史的80%,这意味着模型不会拟合时间序列的最后20%中的任何趋势变化。这是相当保守的,以避免在最后的时间序列过拟合,没有足够的数据来学习规律。如果有人类参与其中,这是一件很容易在视觉上识别的事情:人们可以很清楚地看到预测在最后20%的时间里是否做得不好。在全自动设置中,不那么保守可能是有益的。如上所述,通过交叉验证来有效地调整该参数可能是不可能的。该模型从最后10%的时间序列中的趋势变化进行概括的能力将很难通过查看在最后10%中可能没有趋势变化的早期截止值来学习。所以,这个参数最好不要调优,除非是在大量的时间序列上。在这种情况下,[0.8,0.95]可能是一个合理的范围。
8.3.3 Parameters that would likely not be tuned
- growth:Options are ‘linear’ and ‘logistic’。这可能不会被调整;如果有一个已知的饱和点,并朝着该点增长,它将被包括在内,并将使用 logistic 趋势。否则它将是 linear 的。
- changepoints:这用于手动指定变更点的位置。默认情况下为 None,这将自动放置它们。
- n_changepoints:这是自动放置的变更点的数量。缺省值25应该足以捕捉典型时间序列中的趋势变化(至少Prophet无论如何都能很好地处理这种类型)。与增加或减少变化点的数量相比,通过 changepoint_prior_scale 增加或减少这些趋势变化的灵活性可能会更有效。
- yearly_seasonality:By default (‘auto’) this will turn yearly seasonality on if there is a year of data, and off otherwise. Options are [‘auto’, True, False]. 如果有超过一年的数据,而不是试图在HPO期间关闭它,那么通过调整seasonality_prior_scale 来保持它并关闭季节性影响可能会更有效。
- weekly_seasonality: Same as for yearly_seasonality.
- daily_seasonality: Same as for yearly_seasonality.
- holidays: 这是在一个特定假日的 dataframe 中传递的。假日效果将使用 holidays_prior_scale 调整。
- mcmc_samples:是否使用 MCMC 很可能由时间序列的长度和参数不确定性的重要性等因素决定(文档中描述了这些注意事项)。
- interval_width:Prophet 的 predict() 返回每个 component 的 uncertainty intervals,如预测 yhat 的 yhat_lower 和yhat_upper。这些是作为后验预测分布的分位数计算的,interval_width 指定要使用的分位数。默认值0.8提供80%的预测间隔。如果您想要95%的间隔,您可以将其更改为0.95。这只会影响不确定区间,根本不会改变预测,因此不需要调整。
- uncertainty_samples:不确定区间由后验预测区间的分位数计算,后验预测区间用蒙特卡罗抽样估计。此参数是要使用的采样数(默认为1000)。预测的运行时间将在该数字中呈线性。使其更小将增加不确定性区间的方差(蒙特卡罗误差),而将其更大将减小该方差。因此,如果不确定性估计似乎参差不齐,可能会增加这一数字,以进一步消除它们,但很可能不需要改变。与 interval_width 一样,此参数仅影响不确定间隔,更改它不会以任何方式影响 yhat;它不需要调整。
九、Handling Shocks 处理冲击
%matplotlib inline
from prophet import Prophet
import pandas as pd
from matplotlib import pyplot as plt
import logging
logging.getLogger('prophet').setLevel(logging.ERROR)
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['figure.figsize'] = 9, 6
由于 COVID-19 导致的封锁,许多时间序列在2020年经历了“冲击”,例如媒体消费(Netflix、YouTube)、电子商务交易(亚马逊、eBay),而面对面活动的上座率大幅下降。
这些时间序列中的大部分也将在一段时间内维持其新水平,受放松封锁和/或疫苗驱动的波动影响。
季节性模式也可能发生变化:例如,与COVID封锁前的周末相比,人们在工作日消费的媒体(总时数)可能更少,但在封锁期间,工作日的消费可能更接近周末。
在本页中,我们将探讨使用Prophet的功能捕获这些效果的一些策略:
- 把因 COVID 事件而产生的峰值,更改为 once-off(一次性)。
- 行为的持续变化,导致了趋势和季节性的变化。
9.1 Case Study - Pedestrian Activity 行人活动
在本案例研究中,我们将使用 墨尔本市的行人传感器数据。该数据测量来自中央商务区各个地方的传感器的步行流量,我们选择了一个传感器(Sensor_ID = 4)并将值汇总到每日。
数据在这里可以下载:
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_pedestrians_covid.csv')
df.set_index('ds').plot();

从上图的时序中,可以看出如下:
- 客运量最初在2020年3月21日左右下降,到2020年6月6日左右开始回升。这与世卫组织宣布大流行以及随后维多利亚州政府下令封锁相对应。
- 在经历了一些缓慢的复苏后,客运量在2020年7月9日左右第二次下降,并在2020年10月27日左右开始恢复。这与墨尔本大都市大流行的“第二波”相对应。
在时间序列上,也有较短时间的严格封锁导致突然提示:2021年2月为5天,2021年6月初为14天。
9.2 Default model without any adjustments 默认型号,无需任何调整
首先,我们将使用默认的 Prophet 设置拟合模型:
from matplotlib import pyplot as plt
import pandas as pd
from prophet import Prophet
df = pd.read_csv(
"example_pedestrians_covid.csv"
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_pedestrians_covid.csv
m = Prophet()
m = m.fit(df)
future = m.make_future_dataframe(periods=366)
forecast = m.predict(future)
fig = m.plot(forecast)
plt.axhline(y=0, color="red")
plt.title("Default Prophet")
fig.show()
wait = input("PRESS ENTER TO CONTINUE.")

该模型似乎合理地拟合了过去的数据,但请注意我们如何捕捉下跌,以及下跌后的峰值,作为趋势组件的一部分。
默认情况下,该模型假设这些大的峰值在未来是可能的,即使我们实际上不会在我们的预测范围内看到相同幅度的东西(在这种情况下是1年)。这导致对2022年步行交通恢复的预测相当乐观。
9.3 Treating COVID-19 lockdowns as a one-off holidays 把新冠肺炎封锁当作一次性假期
为了防止趋势成分捕捉到大的跌落和尖峰,我们可以将受新冠肺炎影响的日子视为假期,未来不会再次发生。此处将更详细地介绍添加自定义假期。我们这样设置了一个DataFrame 来描述受封锁影响的时间段:
lockdowns = pd.DataFrame([
{'holiday': 'lockdown_1', 'ds': '2020-03-21', 'lower_window': 0, 'ds_upper': '2020-06-06'},
{'holiday': 'lockdown_2', 'ds': '2020-07-09', 'lower_window': 0, 'ds_upper': '2020-10-27'},
{'holiday': 'lockdown_3', 'ds': '2021-02-13', 'lower_window': 0, 'ds_upper': '2021-02-17'},
{'holiday': 'lockdown_4', 'ds': '2021-05-28', 'lower_window': 0, 'ds_upper': '2021-06-10'},
])
for t_col in ['ds', 'ds_upper']:
lockdowns[t_col] = pd.to_datetime(lockdowns[t_col])
lockdowns['upper_window'] = (lockdowns['ds_upper'] - lockdowns['ds']).dt.days
lockdowns

我们为每个封闭周期都有一行,其中 ds 指定封闭的开始。Prophet 没有使用 ds_upper,而用的是 upper_window(这更方便)。
upper_window 告诉 Prophet 跨度为 封闭开始后的x天。请注意,假日回归包含上限。
请注意,由于我们没有指定任何未来日期,因此在创建未来 dataframe 时,Prophet 将假定这些假期不会再次发生(因此它们不会影响我们的预测)。这不同于我们如何指定一个重复的假期。
from matplotlib import pyplot as plt
import pandas as pd
from prophet import Prophet
df = pd.read_csv(
"example_pedestrians_covid.csv"
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_pedestrians_covid.csv
lockdowns = pd.DataFrame(
[
{
"holiday": "lockdown_1",
"ds": "2020-03-21",
"lower_window": 0,
"ds_upper": "2020-06-06",
},
{
"holiday": "lockdown_2",
"ds": "2020-07-09",
"lower_window": 0,
"ds_upper": "2020-10-27",
},
{
"holiday": "lockdown_3",
"ds": "2021-02-13",
"lower_window": 0,
"ds_upper": "2021-02-17",
},
{
"holiday": "lockdown_4",
"ds": "2021-05-28",
"lower_window": 0,
"ds_upper": "2021-06-10",
},
]
)
for t_col in ["ds", "ds_upper"]:
lockdowns[t_col] = pd.to_datetime(lockdowns[t_col])
lockdowns["upper_window"] = (lockdowns["ds_upper"] - lockdowns["ds"]).dt.days
lockdowns
m = Prophet(holidays=lockdowns)
m = m.fit(df)
future = m.make_future_dataframe(periods=366)
forecast = m.predict(future)
fig = m.plot(forecast)
plt.axhline(y=0, color="red")
plt.title("Default Prophet")
fig.show()
fig2 = m.plot_components(forecast)
fig2.show()
wait = input("PRESS ENTER TO CONTINUE.")

- Prophet 明智地给禁闭期内的日子分配了一个很大的负面影响。
- 对这一趋势的预测没有那么强烈乐观,似乎相当合理。
9.4 Sense checking the trend 感官检查趋势
在行为不断变化的环境中,确保模型的趋势组件捕捉到新兴模式而不是过度匹配它们,这一点很重要。
trend_changepoints 文档 解释了我们可以使用趋势组件进行调整的两件事:
- changepoint 的位置,默认情况下在80%的历史记录中均匀分布。我们应该注意这个范围的终点,如果我们认为最新的数据更好地反映了未来的行为,我们应该扩大范围(通过增加百分比或手动添加变化点)。
- 规则化强度(changepoint_prior_scale),它确定趋势的灵活性;默认值为0.05,增加此值将使趋势更接近观察到的数据。
我们在下面绘制了,当前模型检测到的 trend component 和 changepoints。
from prophet.plot import add_changepoints_to_plot
fig = m2.plot(forecast2)
a = add_changepoints_to_plot(fig.gca(), m2, forecast2)
from matplotlib import pyplot as plt
import pandas as pd
from prophet import Prophet
df = pd.read_csv(
"example_pedestrians_covid.csv"
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_pedestrians_covid.csv
lockdowns = pd.DataFrame(
[
{
"holiday": "lockdown_1",
"ds": "2020-03-21",
"lower_window": 0,
"ds_upper": "2020-06-06",
},
{
"holiday": "lockdown_2",
"ds": "2020-07-09",
"lower_window": 0,
"ds_upper": "2020-10-27",
},
{
"holiday": "lockdown_3",
"ds": "2021-02-13",
"lower_window": 0,
"ds_upper": "2021-02-17",
},
{
"holiday": "lockdown_4",
"ds": "2021-05-28",
"lower_window": 0,
"ds_upper": "2021-06-10",
},
]
)
for t_col in ["ds", "ds_upper"]:
lockdowns[t_col] = pd.to_datetime(lockdowns[t_col])
lockdowns["upper_window"] = (lockdowns["ds_upper"] - lockdowns["ds"]).dt.days
lockdowns
m = Prophet(holidays=lockdowns)
m = m.fit(df)
future = m.make_future_dataframe(periods=366)
forecast = m.predict(future)
fig = m.plot(forecast)
plt.axhline(y=0, color="red")
plt.title("Default Prophet")
fig.show()
fig2 = m.plot_components(forecast)
fig2.show()
from prophet.plot import add_changepoints_to_plot
fig3 = m.plot(forecast)
a = add_changepoints_to_plot(fig3.gca(), m, forecast)
fig3.show()
wait = input("PRESS ENTER TO CONTINUE.")
检测到的变化点看起来是合理的,未来趋势跟踪活动的最新上升趋势,但不会达到2020年底的程度。这似乎适合于对未来活动的最佳猜测。
如果我们想在模型训练中更多地强调COVID模式,我们可以看到预测会是什么样子; 我们可以通过在2020年之后添加更多潜在的变化点并使趋势更加灵活来实现这一点。
我们看到在冠状病毒感染后检测到了许多变化点,与放松和收紧封锁带来的各种波动相匹配。总体而言,趋势曲线和预测趋势与我们之前的模型非常相似,但我们看到了更多的不确定性,因为我们在历史上获得了更多的趋势变化。
我们可能不会选择这个模型,而不是使用默认参数作为最佳估计,但它很好地演示了我们如何将我们的信念融入到模型中,了解哪些模式是重要的。
9.5 Changes in seasonality between pre- and post-COVID 新冠感染前后的季节性变化
前面部分中的季节性成分曲线图显示,与一周中的其他日子相比,周五是活动的高峰期。如果我们不确定这是否仍然适用于封锁后,我们可以在模型中添加有条件的季节性因素。Conditional seasonalities(有条件的季节性)的详细文档详见这里。
首先,我们在历史 dataframe 中定义布尔列,以标记“pre covid”和“post covid”时段:
df2 = df.copy()
df2['pre_covid'] = pd.to_datetime(df2['ds']) < pd.to_datetime('2020-03-21')
df2['post_covid'] = ~df2['pre_covid']
我们在这里感兴趣的条件季节性建模是一周(“周”)的季节性。为此,我们首先在创建 Prophet 模型时关闭默认的weekly_seasonality。
m4 = Prophet(holidays=lockdowns, weekly_seasonality=False)
然后我们手动设置 weekly seasonality ,作为两个不同的模型组件-一个用于 pre covid,一个用于 post covid。请注意 weekly seasonality 的默认设置是 fourier_order=3。然后我们可以运行 .fit()。
m4.add_seasonality(name='weekly_pre_covid', period=7, fourier_order=3, condition_name='pre_covid');
m4.add_seasonality(name='weekly_post_covid', period=7, fourier_order=3, condition_name='post_covid');
我们还需要在 future dataframe 中创建 pre_covid 和 post_covid 标志。这是为了让 Prophet 可以将正确的 weekly seasonality 参数应用到 future。
future4 = m4.make_future_dataframe(periods=366)
future4['pre_covid'] = pd.to_datetime(future4['ds']) < pd.to_datetime("2020-03-21")
future4['post_covid'] = ~future4['pre_covid']
完整代码如下:
from matplotlib import pyplot as plt
import pandas as pd
from prophet import Prophet
df = pd.read_csv(
"example_pedestrians_covid.csv"
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_pedestrians_covid.csv
lockdowns = pd.DataFrame(
[
{
"holiday": "lockdown_1",
"ds": "2020-03-21",
"lower_window": 0,
"ds_upper": "2020-06-06",
},
{
"holiday": "lockdown_2",
"ds": "2020-07-09",
"lower_window": 0,
"ds_upper": "2020-10-27",
},
{
"holiday": "lockdown_3",
"ds": "2021-02-13",
"lower_window": 0,
"ds_upper": "2021-02-17",
},
{
"holiday": "lockdown_4",
"ds": "2021-05-28",
"lower_window": 0,
"ds_upper": "2021-06-10",
},
]
)
for t_col in ["ds", "ds_upper"]:
lockdowns[t_col] = pd.to_datetime(lockdowns[t_col])
lockdowns["upper_window"] = (lockdowns["ds_upper"] - lockdowns["ds"]).dt.days
lockdowns
df2 = df.copy()
df2["pre_covid"] = pd.to_datetime(df2["ds"]) < pd.to_datetime(
"2020-03-21"
) # 所有行, 都增加一列 pre_covid, 早期为 true, 后期为 false
df2["post_covid"] = ~df2["pre_covid"]
m4 = Prophet(holidays=lockdowns, weekly_seasonality=False)
m4.add_seasonality(
name="weekly_pre_covid", period=7, fourier_order=3, condition_name="pre_covid"
)
m4.add_seasonality(
name="weekly_post_covid", period=7, fourier_order=3, condition_name="post_covid"
)
m4.fit(df2)
future4 = m4.make_future_dataframe(periods=366)
future4["pre_covid"] = pd.to_datetime(future4["ds"]) < pd.to_datetime("2020-03-21")
future4["post_covid"] = ~future4["pre_covid"]
forecast4 = m4.predict(future4)
from prophet.plot import add_changepoints_to_plot
fig = m4.plot(forecast4)
plt.axhline(y=0, color="red")
plt.title("Lockdowns as one-off holidays + Conditional weekly seasonality")
fig.show()
wait = input("PRESS ENTER TO CONTINUE.")
有趣的是,这个有条件季节性的模型表明,在COVID之后,行人活动的高峰在周六,而不是周五。这可能是有意义的,因为如果大多数人仍然在家工作,周五晚上不太可能外出。从预测的角度来看,只有当我们关心准确预测工作日和周末时,这才是重要的,但总的来说,这种探索有助于我们深入了解COVID是如何改变行为的。
9.6 Further reading 更多资料
这个页面上的很多内容都是从 GitHub 的讨论中获得灵感的。我们已经介绍了在面对 COVID 等冲击时调整 Prophet 模型的一些简易成果,但也有许多其他可能的方法,例如:
- 使用外部回归变量(例如,封闭严格性指数 lockdown stringency index)。只有当我们
- a) 拥有与我们正在预测的序列,很好地(在位置上)一致的回归数据,以及
- b) 能够控制或预测,比单独的时间序列更准确的回归变量时,这才是有成效的。
- 检测并去除训练期间的离群值数据,或完全丢弃较旧的训练数据。对于没有年度季节模式的次日时间序列,这可能是一种更好的方法。
但总体而言,在规则不断变化、疫情随机发生的情况下,很难对我们的预测有信心。在这种情况下,更重要的是不断地重新培训、重新评估我们的模型,并清楚地传达预测中增加的不确定性。
十、Additional Topics 其他主题
10.1 Saving models 保存模型参数
可以保存适合的 Prophet 模型,以便以后 load 和 use。
在 Python 中,不应该使用 picle 保存模型;attach 到 model object 的 Stan 后端将不会很好地进行 pickle,并且在某些版本的Python下会产生问题。相反,您应该使用内置的序列化函数将模型序列化为 json:
# Python
from prophet.serialize import model_to_json, model_from_json
with open('serialized_model.json', 'w') as fout:
fout.write(model_to_json(m)) # Save model
with open('serialized_model.json', 'r') as fin:
m = model_from_json(fin.read()) # Load model
json 文件将可以跨系统移植,并且反序列化向后兼容较旧的 Prophet 版本。
10.2 Flat trend 保持平稳趋势
对于表现出强烈的 seasonality patterns(季节性) 而不是 trend changes(趋势) 的时间序列,或者当我们想要依赖外生回归模式时(例如,对于时间序列的因果推断),强制使 growth rate 保持平稳可能是有用的。这只需在创建模型时传递growth=‘flat’ 即可实现:
m = Prophet(growth='flat')
以下是,使用 linear versus flat growth(线性增长与平坦增长)的外部回归,与反事实预测的比较。
import pandas as pd
from prophet import Prophet
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
regressor = "location_4"
target = "location_41"
cutoff = pd.to_datetime("2023-04-17 00:00:00")
df = pd.read_csv("example_pedestrians_multivariate.csv", parse_dates=["ds"]).rename(
columns={target: "y"}
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_pedestrians_multivariate.csv
# print(df.head())
train = df.loc[df["ds"] < cutoff] # 训练集
test = df.loc[df["ds"] >= cutoff] # 测试集
def fit_model(growth):
m = Prophet(growth=growth, seasonality_mode="multiplicative", daily_seasonality=15)
m.add_regressor("location_4", mode="multiplicative")
m.fit(train)
preds = pd.merge(test, m.predict(test), on="ds", how="inner") # 数据合并
mape = ((preds["yhat"] - preds["y"]).abs() / preds["y"]).mean() # 预测的误差
return m, preds, mape
m_linear, preds_linear, mape_linear = fit_model("linear")
m_flat, preds_flat, mape_flat = fit_model("flat")
m_linear.plot_components(preds_linear).show()
数据情况如下:
$ head -n 5 example_pedestrians_multivariate.csv
ds,location_4,location_41
2023-04-01 00:00:00,903,975
2023-04-01 01:00:00,490,652
2023-04-01 02:00:00,377,434
2023-04-01 03:00:00,216,336
$ py additional_topic_flat_trend.py # print(df.head())
ds location_4 y
0 2023-04-01 00:00:00 903 975
1 2023-04-01 01:00:00 490 652
2 2023-04-01 02:00:00 377 434
3 2023-04-01 03:00:00 216 336
4 2023-04-01 04:00:00 124 115
m_flat.plot_components(preds_flat);
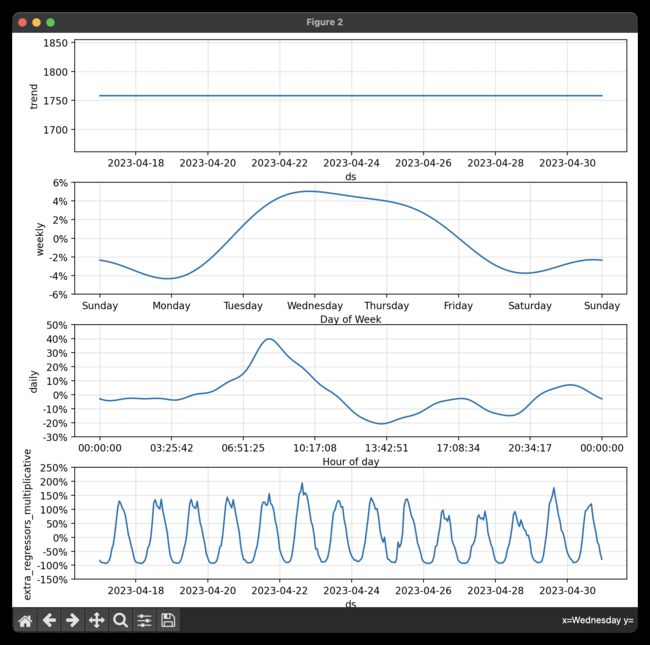
import pandas as pd
from prophet import Prophet
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
regressor = "location_4"
target = "location_41"
cutoff = pd.to_datetime("2023-04-17 00:00:00")
df = pd.read_csv("example_pedestrians_multivariate.csv", parse_dates=["ds"]).rename(
columns={target: "y"}
) # https://raw.githubusercontent.com/facebook/prophet/main/examples/example_pedestrians_multivariate.csv
# print(df.head())
train = df.loc[df["ds"] < cutoff] # 训练集
test = df.loc[df["ds"] >= cutoff] # 测试集
def fit_model(growth):
m = Prophet(growth=growth, seasonality_mode="multiplicative", daily_seasonality=15)
m.add_regressor("location_4", mode="multiplicative")
m.fit(train)
preds = pd.merge(test, m.predict(test), on="ds", how="inner") # 数据合并
mape = ((preds["yhat"] - preds["y"]).abs() / preds["y"]).mean() # 预测的误差
return m, preds, mape
m_linear, preds_linear, mape_linear = fit_model("linear")
m_flat, preds_flat, mape_flat = fit_model("flat")
# m_linear.plot_components(preds_linear).show()
# m_flat.plot_components(preds_flat).show()
# wait = input("PRESS ENTER TO CONTINUE.")
fig, ax = plt.subplots(figsize=(11, 5))
ax.scatter(preds_linear["ds"], preds_linear["y"], color="black", marker=".")
ax.plot(
preds_linear["ds"], preds_linear["yhat"], label=f"linear, mape={mape_linear:.1%}"
)
ax.plot(preds_flat["ds"], preds_flat["yhat"], label=f"flat, mape={mape_flat:.1%}")
plt.xticks(rotation=60)
ax.legend()
plt.show()
wait = input("PRESS ENTER TO CONTINUE.")

在这个例子中,目标传感器的值可以主要由外生回归变量(附近的传感器)来解释。lineat(线性)增长模型呈增长趋势,这导致在测试期间越来越大的超预测性,而 flat (平坦)增长模型主要跟踪外生回归变量的运动,这导致了相当大的MAPE改善。
请注意,只有当我们对回归变量的未来价值有信心时,外生回归变量的预测才是有效的。上面的例子与使用时间序列的因果推断有关,我们想要了解在过去的一段时间内 y 会是什么样子,因此外生回归量值是已知的。
在其他情况下 – 我们没有外生回归变量或必须预测它们的未来值 – 如果将持平增长用于不具有恒定趋势的时间序列,任何趋势都将符合噪声项,因此预测中将存在很高的预测不确定性。
10.3 Custom trends 自定义趋势
要使用这三个内置趋势函数:piecewise linear(分段线性)、piecewise logistic growth(分段逻辑增长)和 flat(平坦)之外的趋势,您可以从 GitHub 下载源码,在本地分支机构根据需要修改趋势函数,然后安装该本地版本。
这个PR 很好地说明了要实现一个定制趋势必须做些什么,就像这个实现了阶跃函数趋势,这个在R中实现了一个新趋势一样。
10.4 Updating fitted models 更新已拟合的模型
预测的一种常见设置是对模型进行拟合,这些模型需要随着更多数据的到来而更新。Prophet模型只能拟合一次,当新数据可用时,必须重新拟合新模型。在大多数设置中,模型拟合速度足够快,因此从头开始重新拟合不会有任何问题。但是,通过从早期模型的模型参数热启动拟合,可以稍微加快速度。此代码示例说明如何在 Python 中完成此操作:
def warm_start_params(m):
"""
Retrieve parameters from a trained model in the format used to initialize a new Stan model.
Note that the new Stan model must have these same settings:
n_changepoints, seasonality features, mcmc sampling
for the retrieved parameters to be valid for the new model.
Parameters
----------
m: A trained model of the Prophet class.
Returns
-------
A Dictionary containing retrieved parameters of m.
"""
res = {}
for pname in ['k', 'm', 'sigma_obs']:
if m.mcmc_samples == 0:
res[pname] = m.params[pname][0][0]
else:
res[pname] = np.mean(m.params[pname])
for pname in ['delta', 'beta']:
if m.mcmc_samples == 0:
res[pname] = m.params[pname][0]
else:
res[pname] = np.mean(m.params[pname], axis=0)
return res
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
df1 = df.loc[df['ds'] < '2016-01-19', :] # All data except the last day
m1 = Prophet().fit(df1) # A model fit to all data except the last day
%timeit m2 = Prophet().fit(df) # Adding the last day, fitting from scratch
%timeit m2 = Prophet().fit(df, init=warm_start_params(m1)) # Adding the last day, warm-starting from m1
1.33 s ± 55.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
185 ms ± 4.46 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
可以看到,前一个模型的参数通过 kwarg init 传递给下一个模型的管件。在这种情况下,使用热启动时,模型拟合速度大约快5倍。加速比通常将取决于最优模型参数随着新数据的添加而改变了多少。
在考虑热启动时,有几点需要注意的事项。首先,热启动可能适用于数据的小幅更新(如上面的示例中增加一天),但如果数据有较大的更改(即,添加了大量天数),则可能比从头开始拟合更糟糕。这是因为当添加大量历史时,两个模型的变化点的位置将非常不同,因此来自前一个模型的参数实际上可能会产生不好的趋势初始化。其次,作为一个细节,从一个模型到下一个模型,变化点的数量需要保持一致,否则将引发错误,因为变化点先前的参数增量将是错误的大小。
10.5 minmax scaling 最小最大缩放 (new in 1.1.5)
在模型拟合之前,Prophet 通过除以历史中的最大值来缩放y。对于具有非常大的 y 值的数据集,缩放的 y 值可以被压缩到非常小的范围(即 [0.99999. - 1.0]),这会导致不好的拟合。这可以通过在 Prophet 构造函数中设置 scaling=‘minmax’ 来修复。
large_y = pd.read_csv(
"https://raw.githubusercontent.com/facebook/prophet/main/python/prophet/tests/data3.csv",
parse_dates=["ds"]
)
m1 = Prophet(scaling="absmax")
m1 = m1.fit(large_y)
m2 = Prophet(scaling="minmax")
m2 = m2.fit(large_y)
m1.plot(m1.predict(large_y));

m2.plot(m2.predict(large_y));
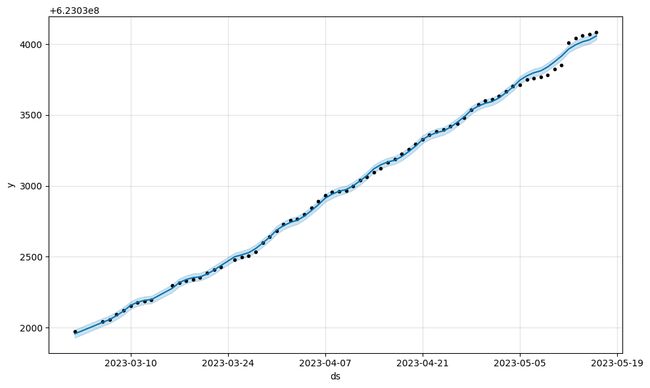
10.7 Inspecting transformed data 检查转换后的数据 (new in 1.1.5)
对于调试,了解原始数据在传递到 stan fit 例程之前是如何转换的是很有用的。我们可以调用.preprocess() 方法来查看 stan 的所有输入,并调用 .culate_init_Params() 来查看模型参数将如何初始化。
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
m = Prophet()
transformed = m.preprocess(df)
transformed.y.head(n=10)
# result:
0 0.746552
1 0.663171
2 0.637023
3 0.628367
4 0.614441
5 0.605884
6 0.654956
7 0.687273
8 0.652501
9 0.628148
Name: y_scaled, dtype: float64
transformed.X.head(n=10)
# result 如下,是 10 行 × 26 列的表格(下表格右边没有截图截全)

m.calculate_initial_params(num_total_regressors=transformed.K)
# result:
ModelParams(k=-0.05444079622224118, m=0.7465517318876905, delta=array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]), beta=array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]), sigma_obs=1.0)
10.8 External references 其他库
正如我们在 2023年关于Prophet状态的博客文章 中所讨论的那样,我们没有进一步开发基础 Prophet 模型的计划。如果您正在寻找最先进的预测准确性,我们推荐以下库:
- statsforecast, and other packages from the Nixtla group such as hierarchicalforecast and neuralforecast.
- NeuralProphet, a Prophet-style model implemented in PyTorch, to be more adaptable and extensible.
这些github存储库提供了在Prophet之上构建的示例,可能会引起广泛的兴趣:
- forecastr: A web app that provides a UI for Prophet.
十一、源码贡献
https://facebook.github.io/prophet/docs/contributing.html
最新的情况详见 https://medium.com/@cuongduong_35162/facebook-prophet-in-2023-and-beyond-c5086151c138,这个库最新的提交是 2023 年 10 月
Prophet有一个不固定的发布周期,但我们将根据用户反馈进行错误修复并添加功能。如果您遇到问题,请通过提交问题来让我们知道。GitHub的问题也是询问有关使用Prophet的问题的合适地方。
我们感谢所有的贡献。如果您计划回馈错误修复,请不要进行任何进一步的讨论。
如果您计划为核心贡献新的功能或扩展,请首先打开一个问题并与我们讨论该功能。发送Pull请求也是可以的,但如果事先在问题中确定了任何设计决策,它可能会更快地合并。
我们试图保持R和Python版本的特性相同,但是可以在单独的提交中为每个方法实现新的特性。
以下部分将介绍如何提交请求,以便向代码库添加增强功能、文档更改或错误修复。