深度强化学习之策略学习-王树森课程笔记
学习资料
深度强化学习课程-王树森
目录
- 一、Policy-based learning
- 二、Policy Network
- 三、 Policy-Based Reinforcement Learning(策略学习)
-
- 1. 用神经网络近似状态价值函数 V π V_{\pi} Vπ
- 2. 策略学习的主要思想
- 3. 策略梯度算法
-
- 3.1 Policy Gradient
- 3.2 策略梯度算法
【基本思想】用一个神经网络(策略网络)来近似策略函数
一、Policy-based learning
策略学习:学习policy函数 π ( a ∣ s ) \pi(a|s) π(a∣s),用 π \pi π控制agent做动作:
- 每观测到一个状态 s t s_t st,把 s t s_t st作为policy函数的输入, π \pi π函数输出每一个动作的概率;
- 用得到的概率做随机抽样得到 a t ∼ π ( ⋅ ∣ s t ) a_t\sim\pi(\cdot|s_t) at∼π(⋅∣st);
- agent执行动作 a t a_t at.
二、Policy Network
Policy Network π ( a ∣ s ; θ ) \pi(a|s;\bm{\theta}) π(a∣s;θ):策略网络,用于近似policy函数 π ( a ∣ s ) \pi(a|s) π(a∣s)。
- θ \bm{\theta} θ:神经网络的参数,一开始是随机初始化的,通过不断地学习来改进 θ \bm{\theta} θ
以超级玛丽为例

- 输入:状态 s s s,即当前屏幕显示的画面或最近几帧的画面;
- 一个或几个卷积层把画面变成特征向量;
- 全连接层把特征向量映射到一个三维向量(因为有三个动作,所以维度是三);
- 用softmax激活函数输出概率分布,输出的是三维向量,每一个元素对应一个动作,值为动作的概率。
policy函数是概率密度函数,需满足 ∑ a ∈ A π ( a ∣ s ; θ ) = 1 \sum_{a\in A}\pi(a|s;\bm{\theta})=1 ∑a∈Aπ(a∣s;θ)=1;
使用softmax函数:让输出值都是正数且加和等于一。
三、 Policy-Based Reinforcement Learning(策略学习)
1. 用神经网络近似状态价值函数 V π V_{\pi} Vπ
State-value function:状态价值函数
对 Q π Q_\pi Qπ关于动作 A A A求期望把 A A A消掉(这里 A A A是随机变量,概率密度函数是 π \pi π, A ∼ π ( ⋅ ∣ s t ) A\sim\pi(\cdot|s_t) A∼π(⋅∣st)),得到的 V π V_\pi Vπ只与 π \pi π和状态 s s s有关
V π ( s t ) = E A [ Q π ( s t , A ) ] = ∑ a π ( a ∣ s t ) ⋅ Q π ( s t , a ) V_\pi(s_t)=E_A[Q_\pi(s_t,A)]=\sum_a\pi(a|s_t)\cdot Q_\pi (s_t,a) Vπ(st)=EA[Qπ(st,A)]=a∑π(a∣st)⋅Qπ(st,a) V π ( s t ) = E A [ Q π ( s t , A ) ] = ∫ π ( a ∣ s t ) ⋅ Q π ( s t , a ) d a V_\pi(s_t)=E_A[Q_\pi(s_t,A)]=\int\pi(a|s_t)\cdot Q_\pi (s_t,a)\space da Vπ(st)=EA[Qπ(st,A)]=∫π(a∣st)⋅Qπ(st,a) da
用策略网络近似策略函数:把 V π V_\pi Vπ中的 π ( a ∣ s t ) \pi(a|s_t) π(a∣st)替换成神经网络 π ( a ∣ s t ; θ ) \pi(a|s_t;\bm{\theta}) π(a∣st;θ),得到对状态价值函数的近似 V ( s ; θ ) V(s;\bm\theta) V(s;θ)
V ( s t ; θ ) = ∑ a π ( a ∣ s t ; θ ) ⋅ Q π ( s t , a ) V(s_t;\bm{\theta})=\sum_a\pi(a|s_t;\bm{\theta})\cdot Q_\pi (s_t,a) V(st;θ)=a∑π(a∣st;θ)⋅Qπ(st,a)
直观意义:
- V V V可以评价状态 s t s_t st和策略网络的好坏;
- 给定状态 s t s_t st,策略网络越好 V V V越大。
2. 策略学习的主要思想
如何让策略网络越来越好?
改进模型参数 θ \bm{\theta} θ让 V ( s ; θ ) V(s;\bm{\theta}) V(s;θ)变大。
目标函数:
J ( θ ) = E S [ V ( S ; θ ) ] J(\bm{\theta})=\Bbb E_S[V(S;\bm\theta)] J(θ)=ES[V(S;θ)]
- 把状态 S S S作为一个随机变量,关于状态 S S S求期望以去掉 S S S,变量只剩 θ \bm\theta θ;
- 目标函数 J ( θ ) J(\bm\theta) J(θ)是对策略网络的评价,目标网络越好, J ( θ ) J(\bm\theta) J(θ)越大。
策略学习目的:改进 θ \bm{\theta} θ使得 J ( θ ) J(\bm\theta) J(θ)越大越好。
3. 策略梯度算法
如何改进模型参数 θ \bm{\theta} θ?
Policy gradient ascent 策略梯度算法
-
观测到状态 s s s:相当于从状态的概率分布中随机抽样出来的。
-
更新策略:把 V ( s ; θ ) V(s;\bm\theta) V(s;θ)关于 θ \bm\theta θ求导得到一个梯度,并用梯度上升来更新 θ \bm\theta θ
θ ← θ + β ⋅ ∂ V ( s ; θ ) ∂ θ ⏟ Policy Gradient \bm\theta \leftarrow \bm\theta+\beta\cdot\underbrace{\frac{\partial V(s;\bm\theta)}{\partial\bm\theta}}_{\color{d44c47}\text{Policy\space Gradient}} θ←θ+β⋅Policy Gradient ∂θ∂V(s;θ)- β \beta β:学习率;
- 相当于随机梯度上升(真正的梯度是 J ( θ ) J(\bm\theta) J(θ)关于 θ \bm\theta θ的导数),随机性来源于 s s s;
- 梯度上升:让目标函数 J ( θ ) J(\bm\theta) J(θ)变得越来越大。
3.1 Policy Gradient
策略梯度:函数 V ( s ; θ ) V(s;\bm\theta) V(s;θ)对神经网络参数 θ \bm\theta θ的导数 ∂ V ( s ; θ ) ∂ θ \frac{\partial V(s;\bm\theta)}{\partial\bm\theta} ∂θ∂V(s;θ)。
两种等价形式:
- Form1: ∂ V ( s ; θ ) ∂ θ = ∑ a ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) \frac{\partial V(s;\bm\theta)}{\partial\bm\theta}=\sum_{\color{d44c47}a}\frac{\partial \pi({\color{d44c47}a}|s;\bm\theta)}{\partial\bm\theta}\cdot Q_\pi(s,{\color{d44c47}a}) ∂θ∂V(s;θ)=∑a∂θ∂π(a∣s;θ)⋅Qπ(s,a)
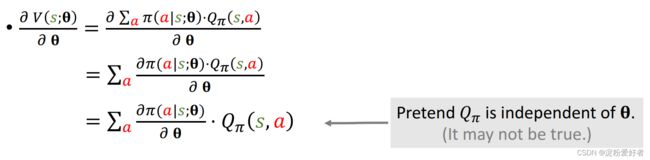
- Form2: ∂ V ( s ; θ ) ∂ θ = E A ∼ π ( ⋅ ∣ s ; θ ) [ ∂ log π ( A ∣ s ; θ ) ∂ θ ⋅ Q π ( s , A ) ] \frac{\partial V(s;\bm\theta)}{\partial\bm\theta}=\Bbb E_{{\color{d44c47}A}\sim\pi(\cdot|s;\bm\theta)}[\frac{\partial\log\pi({\color{d44c47}A}|s;\bm\theta)}{\partial\bm\theta}\cdot Q_\pi(s,{\color{d44c47}A})] ∂θ∂V(s;θ)=EA∼π(⋅∣s;θ)[∂θ∂logπ(A∣s;θ)⋅Qπ(s,A)]

动作是离散的:action space A A A={”left”, “right”, “up”}
使用Form1: ∂ V ( s ; θ ) ∂ θ = ∑ a ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) \frac{\partial V(s;\bm\theta)}{\partial\bm\theta}=\sum_{\color{d44c47}a}\frac{\partial \pi({\color{d44c47}a}|s;\bm\theta)}{\partial\bm\theta}\cdot Q_\pi(s,{\color{d44c47}a}) ∂θ∂V(s;θ)=∑a∂θ∂π(a∣s;θ)⋅Qπ(s,a)
- f ( a , θ ) = ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) , a ∈ A f(a,\bm\theta)=\frac{\partial \pi({\color{d44c47}a}|s;\bm\theta)}{\partial\bm\theta}\cdot Q_\pi(s,{\color{d44c47}a}),\space a\in A f(a,θ)=∂θ∂π(a∣s;θ)⋅Qπ(s,a), a∈A;
- Policy gradient: ∂ V ( s ; θ ) ∂ θ = f ( " left " , θ ) + f ( " right " , θ ) + f ( " up " , θ ) \frac{\partial V(s;\bm\theta)}{\partial\bm\theta}=f(\text{"{\color{d44c47}left}"},\bm\theta)+f(\text{"{\color{d44c47}right}"},\bm\theta)+f(\text{"{\color{d44c47}up}"},\bm\theta) ∂θ∂V(s;θ)=f("left",θ)+f("right",θ)+f("up",θ);
❗ 这种方法对连续动作不适用
动作是连续的:action space A = [ 0 , 1 ] A=[0,1] A=[0,1]
使用Form2: ∂ V ( s ; θ ) ∂ θ = E A ∼ π ( ⋅ ∣ s ; θ ) [ ∂ log π ( A ∣ s ; θ ) ∂ θ ⋅ Q π ( s , A ) ] \frac{\partial V(s;\bm\theta)}{\partial\bm\theta}=\Bbb E_{{\color{d44c47}A}\sim\pi(\cdot|s;\bm\theta)}[\frac{\partial\log\pi({\color{d44c47}A}|s;\bm\theta)}{\partial\bm\theta}\cdot Q_\pi(s,{\color{d44c47}A})] ∂θ∂V(s;θ)=EA∼π(⋅∣s;θ)[∂θ∂logπ(A∣s;θ)⋅Qπ(s,A)]
用蒙特卡洛近似计算期望
蒙特卡洛:抽一个或很多随机样本,用随机样本来近似期望
- 根据概率密度函数 π ( ⋅ ∣ s ; θ ) \pi(\cdot |s;\bm\theta) π(⋅∣s;θ)随机抽样得到一个动作 a ^ {\color{d44c47}\hat{a}} a^;
- 计算 g ( a ^ , θ ) = ∂ log π ( a ^ ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ^ ) \textbf{g}({\color {d44c47}\hat{a}},\bm\theta)=\frac{\partial\log\pi({\color{d44c47}\hat{a}}|s;\bm\theta)}{\partial\bm\theta}\cdot Q_\pi(s,{\color{d44c47}\hat{a}}) g(a^,θ)=∂θ∂logπ(a^∣s;θ)⋅Qπ(s,a^);
a. 根据定义 E A [ g ( A , θ ) ] = ∂ V ( s ; θ ) ∂ θ \Bbb E_{{\color{d44c47}A}}[\textbf{g}({\color {d44c47}A},\bm\theta)]=\frac{\partial V(s;\bm\theta)}{\partial\bm\theta} EA[g(A,θ)]=∂θ∂V(s;θ);
b. 由于 a ^ {\color{d44c47}\hat{a}} a^是根据概率密度函数 π \pi π随机抽样得到的,所以 g ( a ^ , θ ) \textbf{g}({\color {d44c47}\hat{a}},\bm\theta) g(a^,θ)是策略梯度 ∂ V ( s ; θ ) ∂ θ \frac{\partial V(s;\bm\theta)}{\partial\bm\theta} ∂θ∂V(s;θ)的无偏估计; - 由于 g ( a ^ , θ ) \textbf{g}({\color {d44c47}\hat{a}},\bm\theta) g(a^,θ)是策略梯度 ∂ V ( s ; θ ) ∂ θ \frac{\partial V(s;\bm\theta)}{\partial\bm\theta} ∂θ∂V(s;θ)的无偏估计,可以用 g ( a ^ , θ ) \textbf{g}({\color {d44c47}\hat{a}},\bm\theta) g(a^,θ)来近似策略梯度 ∂ V ( s ; θ ) ∂ θ \frac{\partial V(s;\bm\theta)}{\partial\bm\theta} ∂θ∂V(s;θ)(蒙特卡洛近似)。
这种方法对离散动作同样适用
3.2 策略梯度算法
每轮迭代执行以下六步:
- 在 t t t时刻观测到状态 s t s_t st;
- 用蒙特卡洛近似计算策略梯度:把策略网络 π ( ⋅ ∣ s t ; θ t ) \pi(\cdot |s_t;\bm\theta_t) π(⋅∣st;θt)作为概率密度函数,用它随机抽样得到一个动作 a t {\color{d44c47}a_t} at;
- 计算价值函数的值 q t ≈ Q π ( s t , a t ) q_t\approx Q_\pi(s_t,{\color{d44c47}a_t}) qt≈Qπ(st,at);
- 对策略网络 π ( ⋅ ∣ s t ; θ t ) \pi(\cdot |s_t;\bm\theta_t) π(⋅∣st;θt)求导: d θ , t = ∂ log π ( a t ∣ s t , θ ) ∂ θ ∣ θ = θ t \textbf{d}_{\theta,t}=\frac{\partial\log\pi({\color{d44c47}a_t}|s_t,\bm\theta)}{\partial\bm\theta}|_{\bm\theta=\bm\theta_t} dθ,t=∂θ∂logπ(at∣st,θ)∣θ=θt,得到的结果 d θ , t \textbf{d}_{\theta,t} dθ,t是向量矩阵或张量,大小与 θ \bm\theta θ相同;
- 近似计算策略梯度: g ( a t , θ t ) = q t ⋅ d θ , t \textbf{g}({\color {d44c47}a_t},\bm\theta_t)=q_t\cdot \textbf{d}_{\theta,t} g(at,θt)=qt⋅dθ,t;
- 更新策略网络: θ t + 1 = θ t + β ⋅ g ( a t , θ t ) \bm\theta_{t+1}=\bm\theta_t+\beta\cdot \textbf{g}({\color{d44c47}a_t},\bm\theta_t) θt+1=θt+β⋅g(at,θt)
如何计算第三步的动作价值函数的值 q t ≈ Q π ( s t , a t ) q_t\approx Q_\pi(s_t,{\color{d44c47}a_t}) qt≈Qπ(st,at)?
方法一:REINFORCE算法
- 用策略网络 π ( a ∣ s ; θ ) \pi(a|s;\bm{\theta}) π(a∣s;θ)控制agent运动,从开始到结束,把整个游戏的轨迹记录下来: s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , . . . , s T , a T , r T s_1,a_1,r_1,s_2,a_2,r_2,...,s_T,a_T,r_T s1,a1,r1,s2,a2,r2,...,sT,aT,rT;
- 观测到所有奖励后可以算出return u t = ∑ k = t T γ k − t r k u_t=\sum_{k=t}^T\gamma^{k-t}r_k ut=∑k=tTγk−trk;
- 由于动作价值函数是 U t U_t Ut的期望,即 Q π ( s t , a t ) = E [ U t ] Q_\pi(s_t,{\color{d44c47}a_t})=\Bbb E[U_t] Qπ(st,at)=E[Ut],可以用 U t U_t Ut的观测值 u t u_t ut来近似 Q π ( s t , a t ) Q_\pi(s_t,{\color{d44c47}a_t}) Qπ(st,at);
- 用观测到的 u t u_t ut来代替函数 Q π ( s t , a t ) Q_\pi(s_t,{\color{d44c47}a_t}) Qπ(st,at),即 q t = u t q_t=u_t qt=ut.
缺点:需要玩完一局游戏,观测到所有奖励后才能更新策略网络
方法二:用神经网络近似 Q π Q_\pi Qπ函数
- actor-critic方法(将价值学习和策略学习结合起来)