vivado 将I/O规划项目迁移到RTL、UltraScale的I/O规划体系结构内存IP、UltraScale体系结构内存IP I/O规划设计流程变更、综合I/O规划
将I/O规划项目迁移到RTL
项目
定义I/O端口并将其放置到封装引脚上后,可以迁移I/O规划项目到RTL项目。端口定义用于为
按照规定,使用Verilog或VHDL进行RTL设计。差分对缓冲器添加到顶部模块和总线定义也包括在RTL中。项目属性更改为反映RTL项目类型。
重要!迁移后,RTL项目无法转换回I/O规划项目。要转换项目,请执行以下操作:
1.选择文件 → 迁移到RTL。
注意:或者,也可以从流导航器中选择“移植到RTL”。
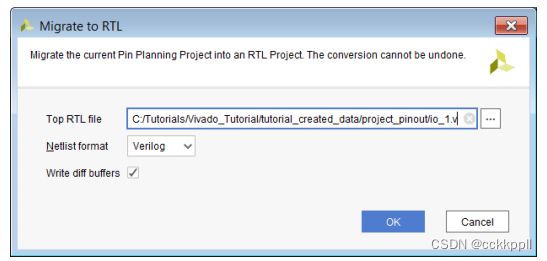
2.在“移植到RTL”对话框中(请参见下图),设置以下选项,然后单击好啊
•顶部RTL文件:指定要为其创建的Verilog(.v扩展名)或VHDL(.vhd扩展名)文件设计的顶部模块。
HDL文件包括带有端口的模块定义总线引脚的定义、方向和宽度。
•网表格式:为顶部模块指定Verilog或VHDL格式。
•写入diff缓冲区:将diff对缓冲区作为顶部模块定义的一部分写入。这保留I/O规划项目中定义的任何差分对。
将I/O规划项目转换为RTL项目后,可以开始添加源为项目和设计工作。有关更多信息,请参阅“使用”一节Vivado Design Suite用户指南中的源文件:系统级设计条目(UG895)。
UltraScale的I/O规划体系结构内存IP
AMD UltraScale™ 体系结构内存IP使用预先设计的控制器和物理层(PHY),用于连接FPGA用户设计和AMBA®规范高级可扩展接口(AXI4)从接口到支持的外部存储器设备。高速内存接口必须遵守:
•由计时和偏斜需求驱动的特定引脚输出要求
•内存I/O组中字节通道使用的特定规则
•物理引脚分配要求
内存还具有仅限硬内存控制器的I/O引脚(DDRMC)。这些引脚不能用于除了硬盘控制器之外的任何东西。因此,如果设计不使用这些引脚引脚不能用于GPIO。
出于性能目的,内存IP的最终配置取决于I/O作业。因此,在IP的I/O已分配。因此,您必须处理的I/O分配和实现此IP与大多数其他IP不同。本章介绍了I/O规划和UltraScale体系结构内存IP的实现。
建议:由于与端口分组和内存I/O组分配相关的限制控制器,AMD建议您在常规I/O之前完成内存控制器的I/O规划合成后项目中的任务。
视频:有关更多信息,请参阅Vivado Design Suite QuickTake视频:使用UltraScale进行设计
设备内存IP。
重要!本章仅介绍UltraScale体系结构内存IP。有关内存IP的信息有关7系列设备,请参阅Zynq 7000 SoC和7系列设备内存接口解决方案(UG586)。
UltraScale体系结构内存IP I/O规划设计流程变更
AMD Vivado™ Design Suite在I/O分配和UltraScale体系结构的实施过程内存IP:
•整合内存IP I/O规划与Vivado IDE主I/O中的其余设计规划视图布局,使引脚规划与设计RTL或合成后设计
•作为opt_design的一部分,现在在合成后执行IP的PHY实现命令,它启用基于网表的I/O规划。
•包含IP的物理块(Pblock)现在自动生成为opt_design命令,并且是瞬态的,对用户不可见。
综合I/O规划
在以前的Vivado Design Suite版本中,您将所有I/O分配作为自定义的一部分IP。这些工具将结果约束与IP一起存储在只读XDC文件中。这是必需的您可以重新自定义IP以修改端口分配。此外,这些限制是在设计的其余部分的I/O分配和验证期间不一定可见。开始于在2015.1版本中,您可以在主Vivado IDE I/O中执行内存I/O分配规划视图布局以及其他设计端口。它不再是内存IP的一部分配置此工具被称为高级I/O规划器,现在包括XPIO选择IO™接口。它一次放置所有I/O,以优化I/O放置和封装。新的内存I/O方法使您能够:
•在不重新生成内存IP的情况下更改内存I/O端口。
•将内存IP定位到具有不同引脚的不同设备,而无需重新生成内存IP。
在一个环境中同时使用多个内存控制器执行I/O规划。
•在设计的顶级XDC约束文件中定义并存储内存端口分配而不是在IP内的只读文件中。
•直接编辑或替换XDC约束文件以修改内存I/O端口作业。
PHY实现
UltraScale体系结构内存IP使用预先设计的控制器定义内存控制器以及用于将用户设计和AMBA规范AXI4从接口连接到DDR3的PHY,DDR4、QDRII+、QRDRIVE和RLDRAM3 SRAM器件。
存储器IP的结构使得AMD中只有物理层(PHY)互连当引脚变化时,设备需要更新。因为PHY的实现取决于I/O分配,它必须在放置和验证I/O之后发生。启用内存I/O在综合之后进行规划,PHY的实现现在作为opt_design命令期间的实现。