Spark 作业执行流程
一、Spark组件
Spark的基本组件,包括负责集群运行的Master和Worker,负责作业运行的Client和Driver,以及负责集群资源管理器(如YARN)和执行单元Executor等。
从架构层面上来说,每一个Spark Application都由控制集群的主控节点Master、负责集群资源管理的Cluster Manager、执行具体任务的Worker节点和执行单元Executor、负责作业提交的Client端和负责作业控制的Driver进程组成。
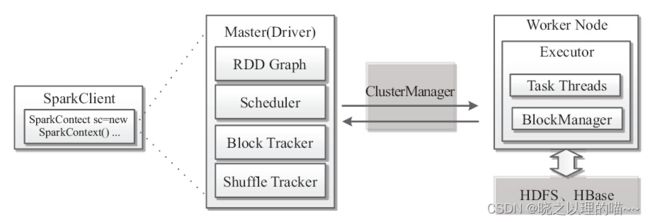
SparkClient负责任务的提交,Driver进程通过运行用户定义的main函数,在集群上执行各种并发操作和计算。其中,SparkContext是应用程序与集群交互的唯一通道,主要包括:获取数据、交互操作、分析和构建DAG图、通过Scheduler调度任务、Block跟踪、Shuffle跟踪等。
用户通过Client提交一个程序给Driver之后,Driver会将所有RDD的依赖关联在一起绘制成一张DAG图;当运行任务时,调度Scheduler会配合组件Block Tracker和Shuffle Tracker进行工作;通过ClusterManager进行资源统一调配;具体任务在Worker节点进行,由Task线程池负责具体任务执行,线程池通过多个Task运行任务。由BlockManager进行存储管理,数据在内存中可以保存多份,一方面进行备份,另一方面支持RetryTask和StragglingTask快速恢复。
二、RDD视图
Spark的核心是基于RDD的抽象,可分为基于RDD数据的静态视图和基于Partition分区的动态视图。
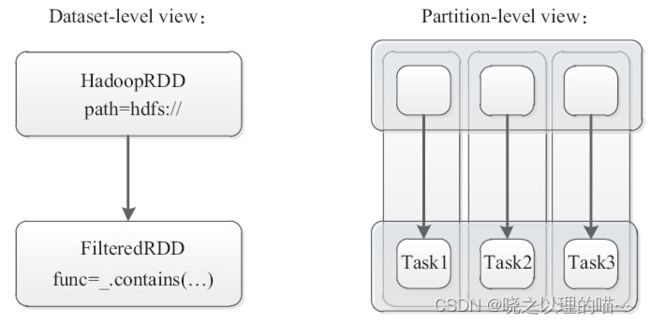
上图对三个数据分片的计算任务,启动了三个Task任务,每个任务都需要单独作用于RDD数据集的代码,返回执行结果给新的RDD。
示例:word count计算
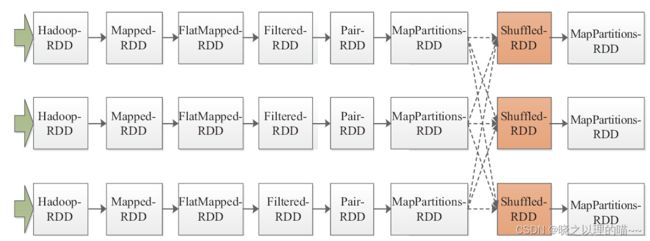
上图中ShulffledRDD产生宽依赖而将整个DAG图划分成两个Stage。第一个Stage由HadoopRDD到MapPartitionsRDD,生成ShuffleMapTask,第二个Stage由ShulffledRDD到MapPartitionsRDD,生成ResultTask。第一个Stage是由三个ShuffleMapTask通过Pipeline的方式并行执行,直至三个Task均执行结束至MapPartitionsRDD处。ShuffleMapTask会产生一些中间结果,而这些中间结果又是第二个Stage中ResultTask的输入。那么这些中间结果是如何递交至ResultTask的呢?ShuffleMapTask的返回值类型是MapStatus,其中包含一些计算的状态,而具体的中间结果则是写入磁盘;而ResultTask在调用ShuffleRDD时则是通过BlockManager去磁盘中读取中间结果。
三、DAG图
在图论中,如果一个有向图无法从任一顶点出发经过若干条边回到该点,则这个图是一个有向无环图(Directed Acyclic Graph,DAG)。
有向无环图是描述一项工程进行过程的有效工具。除最简单的情况之外,几乎所有的工程(project)都可分为若干个称为“活动”(activity)的子工程,而这些活动子工程之间,通常受着一定条件的约束,如其中某些子工程的开始必须在另一些子工程完成之后。
定义节点为活动,有向边的指向表示活动执行的次序。举例来说,假设有A、B、C、D一共四个数据集,其中B数据集依赖于A,C数据集依赖于B,D数据集依赖于C,针对A、B、C、D数据集的依赖关系绘制成一张图DAG图。

如上图所示,针对该DAG图,集合的顶点是A,通过有向边A→B,连接到集合B,B通过有向边B→C,连接到集合C,C通过有向边C→D,连接到集合D。这样,在集合的顶点A开始,沿着有序的边,最终循环再次回到A是不可能的。
在Spark中,DAG图绘制完毕,不会被立即执行,而是仅仅对数据集进行标记。
四、作业执行流程
提交作业有两种方式,分别是Driver运行在集群中,Driver运行在客户端。
基本概念:
(1)Stage,一个Spark作业一般包含一到多个Stage。
(2)Task,一个Stage包含一到多个Task,通过多个Task实现并行运行的功能。
(3)DAGScheduler,实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的TaskSet放到TaskScheduler中。
1,基于Standalone模式的Spark架构
在Standalone模式下有两种运行方式:以Driver运行在Worker上和以Driver运行在客户端,如下图所示给出了Standalone模式下两种运行方式的架构。这两种运行方式可以通过参数–deploy-mode进行配置,默认是Client模式(即Driver运行在客户端)。集群启动Master与Worker进程,Master负责接收客户端提交的作业,管理Worker,并提供Web展示集群与作业信息。
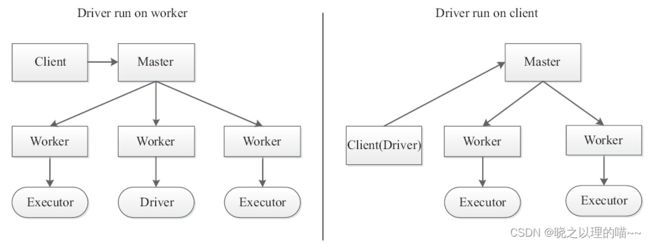
整个框架下,各种进程角色如下。
(1)Master:主控节点,负责接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
(2)Worker:Slave节点上的守护进程,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor。
(3)Client:客户端进程,负责提交作业到Master。
(4)Driver:一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责DAG图的构建、Stage的划分、Task的管理及调度以及生成SchedulerBackend用于Akka通信。主要组件包括DAGScheduler、TaskScheduler及SchedulerBackend。
(5)Executor:执行作业的地方。每个Application一般会对应多个Worker,但是一个Application在每个Worker上只会产生一个Executor进程,每个Executor接收Driver的命令LaunchTask,一个Executor可以执行一到多个Task。
示例:提交一个任务到集群,以Standalone为例,首先启动Master,然后启动Worker,启动Worker时要向Master注册。
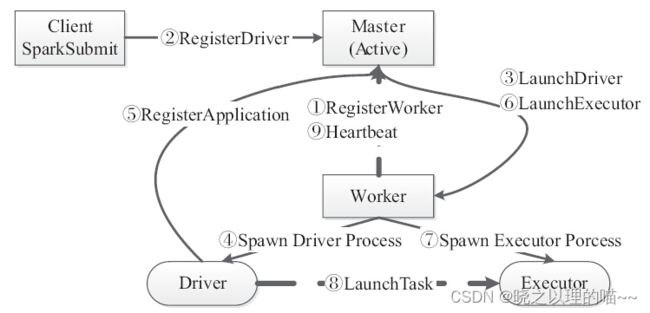
Standalone作业执行流程:
Master收到应用程序提交之后,需要注册并加载Driver,然后由Driver注册应用程序,由Master去Launch具体的Executor资源,由Driver去触发Executor进程Launch具体的Task。
作业执行流程详细描述:
客户端提交作业给Master,Master让一个Worker启动Driver,即SchedulerBackend。Worker创建一个DriverRunner线程,DriverRunner启动SchedulerBackend进程。另外,Master还会让其余Worker启动Executor,即ExecutorBackend。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。ExecutorBackend启动后会向Driver的SchedulerBackend注册。SchedulerBackend进程中包含DAGScheduler,它会根据用户程序生成执行计划,并调度执行。对于每个Stage的Task,都会被存放到TaskScheduler中,ExecutorBackend向SchedulerBackend汇报时把TaskScheduler中的Task调度到ExecutorBackend执行。所有Stage都完成后作业结束。
程序执行过程中,由Worker节点向Master发送心跳,随时汇报Worker的健康状况。
针对几种故障情况,给出了相应的处理方案:
第一种情况,Worker节点出现故障。Worker在退出之前,会将该Worker上的Executor杀掉;而Worker是需要定期发送心跳给Master的,Master通过心跳机制能够感知到该Worker节点的故障,而后将该情况汇报给Driver,并将该Worker从节点中移除;这样,Driver即可知道该Worker上对应的Executor已被杀死。
第二种情况,Executor出现问题。ExecutorRunner会将情况汇报给Master,从而Master便知道该Executor出现问题。但是此时运行该Executor的Worker是正常的,因此Master会发送LaunchExecutor指令给该Worker,让其再次启动一个Executor;而Worker收到LaunchExecutor指令后便再次启动Executor。
第三种情况,Master出现故障,通过Zookeeper搭建Master的HA,一个作为Active,其他的作为Standby,一旦Active节点出现故障,能够及时进行切换。
Driver运行在客户端,和Driver运行在Worker节点上类似,但也有几点不一样。
2,基于YARN模式的Spark架构
在YARN模式下有两种运行方式:Driver运行在集群NodeManager和Driver运行在客户端。
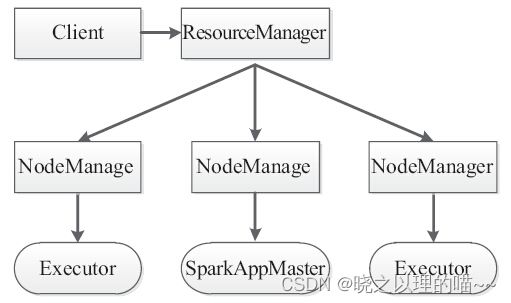
这里SparkAppMaster相当于Standalone模式下的SchedulerBackend,Executor相当于Standalone模式下的ExecutorBackend,SparkAppMaster包括DAGScheduler和YARNClusterScheduler。
Spark on YARN的作业执行机制:
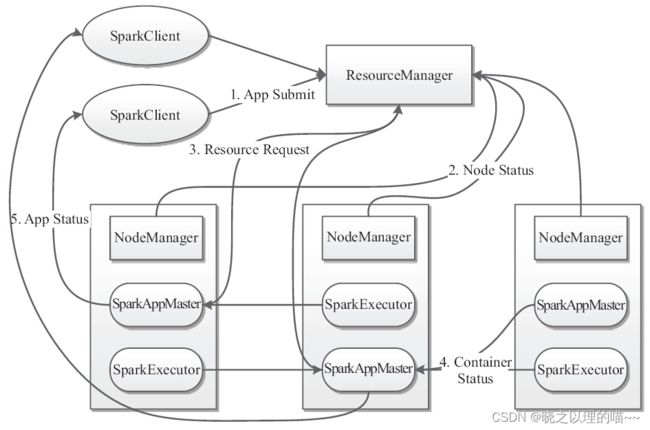
基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager,ResourceManager在某一NodeManager汇报时把AppMaster分配给NodeManager,NodeManager启动SparkAppMaster,SparkAppMaster启动后初始化作业,然后向ResourceManager申请资源,申请到相应资源后SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor,SparkExecutor向SparkAppMaster汇报并完成相应的任务。此外,SparkClient会通过AppMaster获取作业运行状态。
五、作业事件流和调度分析
1,Spark任务处理事件流
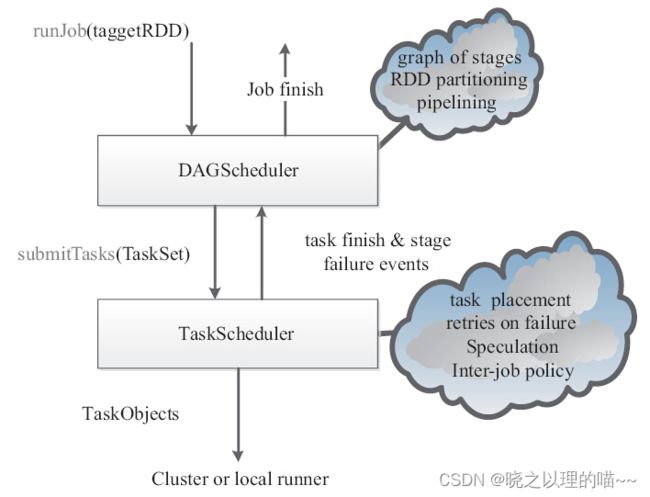
任务提交到集群,集群将任务分配到具体的工作节点去处理。运行任务有4个参数:targetRDD、partitions、func和listeners。runJob会把代码提交给DAGScheduler,DAGScheduler将代码绘制成DAG图,而根据依赖关系又将DAG图划分成不同的Stage,对应多个TaskSet,TaskSet交给TaskScheduler,TaskScheduler与资源管理器进行交互,资源管理再根据不同的部署模式与集群进行交互,当然也可以在Local级别进行运行。TaskScheduler有自己的事件处理机制,task finish和stage failure都是事件触发的。
2,作业处理的调度框架
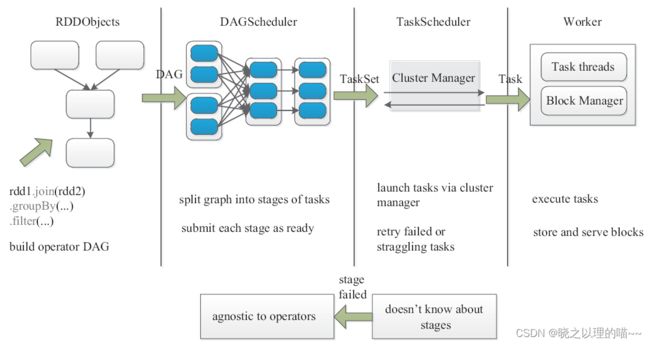
整个调度过程包括:生成RDD对象、构建DAGScheduler、任务调度、作业执行等几个部分。
(1)生成RDD对象过程中,根据输入RDD进行解析,构建操作DAG图(build operator DAG)。代码中RDD进行转换(transformation)操作是惰性(lazy)的,转换操作只会产生标记,并不立即执行,只有遇到执行(action)操作时,执行操作调用runJob方法,从而递交至DAGScheduler,并绘制DAG图,程序才会真正执行。
(2)构建DAGScheduler过程中,根据DAG图划分任务阶段(split graph into stages of tasks),并将按照阶段(Stage)提交任务集(TaskSet)。首先将整个DAG图划分成一个完整的Stage(也称为finalStage),然后从Stage中的最后一个RDD起往前回溯。在回溯过程中,不断判断RDD的依赖关系,如果是窄依赖(narrowdependncy)则继续回溯,如果是宽依赖(wide dependncy)则划分出一个新的Stage。从而将整个DAG图划分成多个Stage,每个Stage有一组Task组成。如果满足;localExecutionEnabled为真;allowLocal为真;finalStage没有父Stage;Partition数目为1这四个条件,则会在本地开启Local模式执行任务。否则,采取集群模式运行任务。只要满足该Stage没有未执行完毕的父Stage,则该Stage可以提交任务,并将任务集(TaskSet)作为Stage的参数提交。
(3)任务调度过程中,通过集群管理器分配资源启动具体任务(launch tasks via cluster manager),并重试失败或运行较慢任务(retry failed or straggling tasks)。
DAGScheduler递交给TaskScheduler的是TaskSet,SchedulerBackend通过makeOffers申请资源,通过resourceOffers调度资源。另外,TaskScheduler是通过TaskSetManager来管理这些Task的,当满足一定的条件,包括调度策略(FIFO和FAIR)以及延迟调度(数据本地性),则会将LaunchTask消息发送给ExecutorBackend。当有任务失败或者Straggling Tasks时,在TaskScheduler层面会重新计算这些Task,只有超出Task的范围上升至Stage或者DAG层面时,才会交由DAGScheduler进行处理。任务失败之后,Straggling Tasks采取的措施是开启同样的一个节点,并对这个节点进行计算。此时就有两个阶段对同一个任务进行计算。Spark采取的措施是看谁计算完,就要谁的结果。
(4)作业执行过程中,执行任务(execute task),存储并管理数据块(store and server block)。
ExecutorBackend在接收到LaunchTask消息后,会在Executor上执行LaunchTask操作。LaunchTask操作中,会生成新的TaskRunner,并以线程池的方式进行执行。在Task执行时,是需要区分Task是ShuffleMapTask还是ResultTask的,两者的返回也不一样。通过BlockMananger接口对存储进行管理,包括内存的读写和磁盘的读写。其中,Shuffle的中间结果是需要写入磁盘的。
六、Spark 作业运行时环境
Spark中每个应用程序都维护了自己的一套运行时环境,该运行时环境在应用程序开始时构建,在运行结束时销毁。相对于所有应用程序共用一套运行时环境的方式,极大地缓解了应用程序之间的相互影响。
1,Spark的运行原理
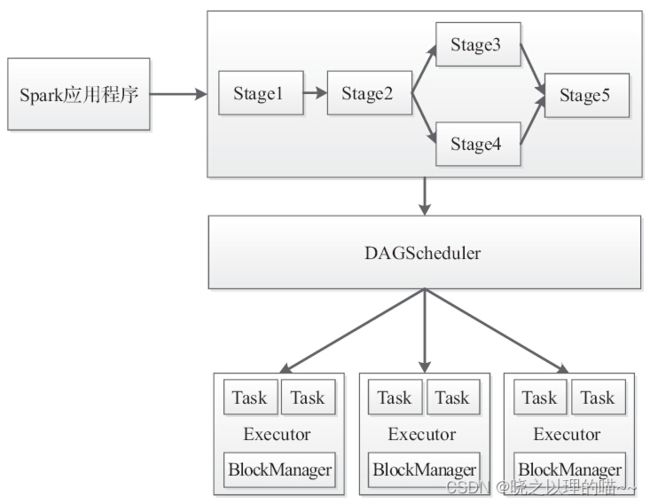
一个Spark运行时环境由4个阶段构成。
·阶段一:构建应用程序运行时环境。
·阶段二:将应用程序转换成DAG图。
·阶段三:按照依赖关系调度执行DAG图。
·阶段四:销毁应用程序运行时环境。
2,构建应用程序运行时环境
为了运行一个应用程序,Spark首先根据应用程序资源需求构建一个运行时环境,这是通过与资源管理器交互来完成的。通常而言,存在两种运行时环境构建方式:粗粒度和细粒度。
(1)粗粒度:应用程序被提交到集群之后,它在正式运行任务之前,将根据应用程序资源需求一次性将这些资源凑齐,之后使用这些资源运行任务,整个运行过程中不再申请新资源。
(2)细粒度:应用程序被提交到集群之后,动态向集群管理器申请资源,只要等到资源满足一个任务的运行,便开始运行该任务,而不必等到所有资源全部到位。目前,基于Hadoop的MapReduce就是基于细粒度运行时环境构建方式。
对于Spark on YARN,目前仅支持粗粒度构建方式。不管何种方式,除了启动任务相关的组件外,每个Executor还需要启动一个RDD缓存管理服务BlockManager,该服务采用了分布式Master/Slaves架构,其中,主控节点上启动Master服务BlockManagerMaster,它掌握了所有的RDD缓存位置,而从节点则启动Slave服务BlockManager,供客户端存取RDD使用。
3,应用程序转换成DAG
Spark将依赖分为窄依赖与宽依赖;在将应用程序转换成DAG的过程中,Spark的调度程序会检查依赖关系的类型,根据RDD依赖关系将应用程序划分为若干个Stage,每个Stage启动一定数目的任务进行并行处理。
Spark采用了贪心算法划分阶段,即如果子RDD的分区到父RDD的分区是窄依赖,就实施经典的Fusion(融合)优化,把对应的操作划分到一个Stage,如果连续的变换算子序列都是窄依赖,就可以把很多个操作并到一个Stage,直到遇到一个宽依赖。这不但减少了大量的全局屏障(barrier),而且无须物化很多中间结果RDD,可极大地提升性能,Spark把这个称为流水线(pipeline)。
宽依赖在一个执行中会跨越连续的Stage,同时需要显式指定多个子RDD的分区。
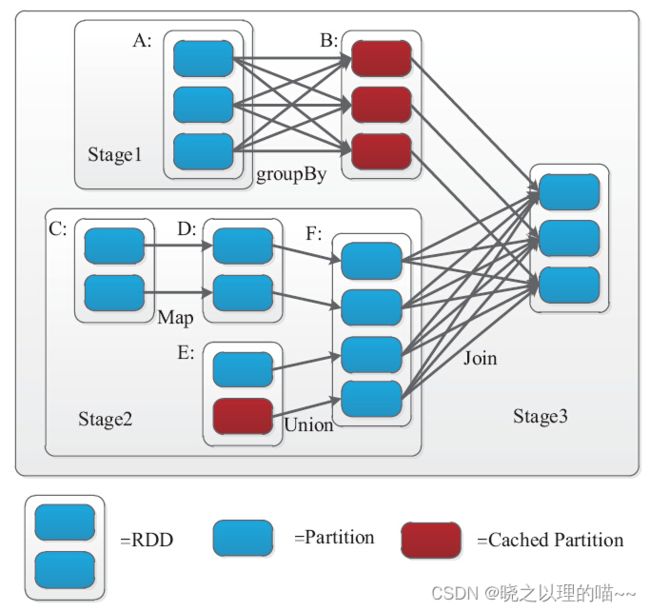
上图是来自Matei Zaharia撰写的论文An Architecture for Fast and General Data Processing on Large Clusters,说明了窄依赖与宽依赖之间的Stage划分。
一个Box代表一个RDD,一个带阴影的矩形框代表一个Partition,红色矩形框代表Cached Partition。
我们知道,一个Stage的边界,输入是外部存储或者一个Stage shuffle的结果;输出则是Job的结果(result task对应的stage)或者shuffle的结果。图5-11中Stage3的输入则是RDD A和RDD Fshuffle的结果。而A和F由于到B和G需要shuffle,因此需要划分到不同的stage。该DAG图最终被转化为三个Stage,每个阶段将启动多个任务并行处理。
DAGScheduler将Stage划分完成后,提交实际上是通过把Stage转换为TaskSet,然后通过TaskScheduler将计算任务最终提交到集群。
4,调度执行DAG图
在该阶段中,DAGScheduler将按照依赖关系调度执行每个Stage:优先选择那些不依赖任何阶段的Stage,待这些阶段执行完成后,再调度那些需要依赖的阶段已经运行完成的Stage。依次进行,这样一直调度下去,直到所有阶段运行完成。
在处理某个阶段时,Spark将为之启动一定数目的Task并行执行,为了提高任务的执行效率,Spark借鉴
MapReduce中的优化机制,包括数据本地性和推测执行:
(1)数据本地性,是指对任务进行调度时为算子选择数据匹配的节点,优先选择数据所在节点,其次选择数据所在机架上的节点,最后选择其他机架上的节点。针对输入数据量较少时本地性变差的情况采用了延迟调度(delay scheduling)机制,即当不存在满足本地性的资源时,暂时将资源分配给其他任务,直到出现满足本地性的资源或者达到设定的最大时间延迟。
(2)推测执行,当检查到同类任务中存在明显比较慢的任务时,尝试为这些比较慢的任务启动备份任务,并将最先完成任务的计算结果作为最终结果。DAG的推测执行开始于DAG的叶节点,往上追溯父RDD需要的依赖性,最终追溯到源节点。
相对于传统的MapReduce计算框架,Executor针对以下两个方面进行了改进:
(1)采取多线程执行具体的任务,减少了多进程任务频繁的启动开销,使任务执行变得非常可靠和高效。
(2)Executor上会有一个BlockManager存储模块,类似于KV系统(内存和磁盘共同作为存储设备),当需要多轮迭代时,可以将中间过程的数据先放到这个存储系统上,后续需要时直接读取该存储数据,而不需要读写到HDFS等相关的文件系统里;或者在交互式查询场景下,事先将表缓存到该存储系统上,提高读写IO性能。
典型的DAG执行流程如下:
(1)RDD直接从外部数据源(HDFS、本地文件等)创建。
(2)RDD经历一系列的Transformation(Map、flatMap、Filter、groupBy、Join),每一次都会产生不同的RDD,供给下一个Transformation使用。
(3)当触发Action(Count、Collect、Save、Take)时,将最后一个RDD进行转换,输出到外部数据源。
这一系列处理过程称为一个血统(lineage),即DAG拓扑排序的结果。在Lineage中生成的每个RDD都是不可变的。事实上,除非被缓存,每个RDD在进入下一个Transformation操作之前都只使用一次。
以人类进化的方式显示了基于RDD的血统进化图:
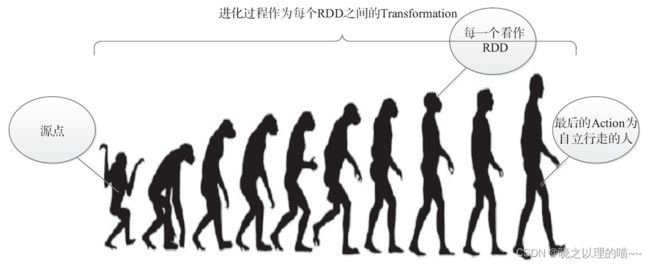
如果按照MapReduce,流程中任何一个步骤出了问题,都会重新计算,但是在Spark中,由于有血统Lineage的存在,可以采取中间持久化的方式进行容错处理,避免全部重新计算。
执行DAG的过程如下:首先应用程序创建SparkContext的实例,如实例为sc,这是应用程序与集群交互的唯一通道;其次,利用SparkContext的实例创建生成RDD,经过一连串的Transformation操作,原始的RDD转换成其他类型的RDD;最后,当Action作用于转换之后的RDD时,会调用SparkContext的runJob方法。sc.runmlil的调用是后面一连串反应的起点,提交应用程序进行针对性的计算。
任务执行完毕,将销毁运行时环境,释放应用程序占用的资源,归还给集群,以供其他程序使用。
5,Spark 作业执行 运行实例
示例:以从日志中找出标有“error”的记录为例,说明Spark的运行原理。
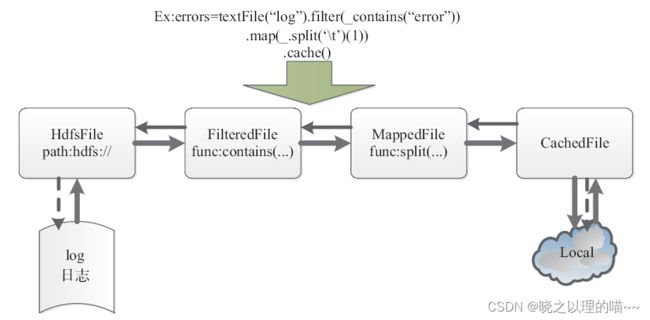
第一步,根据代码和集群交互,申请资源,初始化运行时环境。
第二步,将应用程序转换成DAG图。
将应用程序转换成DAG图,实质上是通过Spark的操作函数来标记各种RDD,关联各种RDD之间的依赖关系构成DAG图,并划分成不同的Stage。如图5-13所示,textFile、Filter、Map都属于Transformation操作,并不立即执行,而是处于延迟操作状态;Cache也是惰性(lazy)执行的,只有当Cache过的数据做Action操作时,才会将Cache的RDD缓存起来,供后续迭代使用。
第三步,按照依赖关系调度执行DAG图。
从HDFS文件中记录读取log(日志)的信息,产生MappedRDD;经过Filter过滤函数,结果产生FilteredRDD;使用Map执行分词取第一列的函数,返回新的MappedRDD;最后将其Cache在内存。
最后,执行完毕,销毁应用程序运行时环境,释放资源。
文章来源:《Spark核心技术与高级应用》 作者:于俊;向海;代其锋;马海平
文章内容仅供学习交流,如有侵犯,联系删除哦!