Linux学习之文件系统与动静态库
目录
一,文件的管理
什么是磁盘?
磁盘的逻辑抽象结构
格式化
inode
挂载
软硬链接
二,动静态库
什么是动静态库?
1.站在库的制作者角度
静态库:
制作一个静态库
2.站在静态库使用者的角度
动态库
作为制作者
作为使用者
动态库加载
一,文件的管理
和进程,内存一样,操作系统创建它就要管理他,文件也是如此,也需要操作系统来管理,那么如何管理呢?还是我们的六字真言,先描述在组织,这与我们学习进程的思想是近似的。
而我们
管理文件的核心就是找到文件,即文件的路径,其次管理文件根据文件的属性分为两种:
1.打开的文件在内存中的管理。
2.未打开的文件在磁盘中的管理。
所以我们首先第一件事就是先弄清楚如何找到文件的路经,并且是快速的,准确的。而了解这个,就先了解磁盘是如何存储并且定位寻找的。
什么是磁盘?
磁盘是一种用电磁原理记录数据的存储设备,由涂上磁性物质的盘片和盘片读写装置(驱动器)组成。磁盘可以分为软盘、硬盘等类型。如果您需要管理硬盘分区及文件、搜索丢失的分区及文件、对磁盘进行快速分区格式化等操作。磁盘价格便宜,容量大,是企业大量使用的存储介质。
磁盘的结构:

磁盘与盘面的比例是一比一的,通过磁头的摆动,来定位磁盘的某个位置,磁盘的摆动只能左右摆动,盘面是在高速的旋转着,相对于其他外设较慢。其中磁头是具有磁性的,受到碰撞就会损坏磁盘。
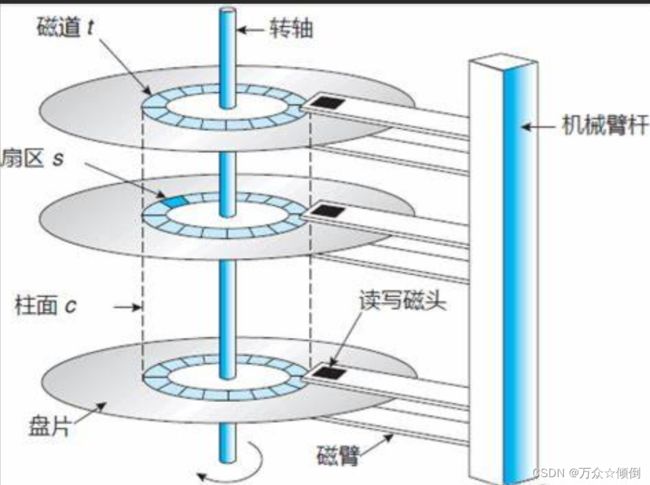
一个磁盘上面有许多磁道,他们是一圈圈的同心圆,而扇区就是把一个磁盘分成若干份,因此磁盘再进行存储时,扇区是磁盘被读写的最小单位,一般是512字节,当我们需改某一扇区的即使某一比特位是,也需要加载这个扇区到内存中,所谓一我们把磁盘这样的设备叫块设备。
那么我们如何寻址,定位,选择哪一个扇面,本质就是上选择磁头,选择好了哪一面,下来就是选择哪一个磁道,最后在磁道当中最后在来选择哪一个扇区。同一个磁道构建出的柱面,这种的寻址方法在这里(head,cylinder,sector)就是CHS寻址法。
而文件包括了属性加内容,因此在存储时,属性和属性放在一些,内容与内容放在一起,有的磁道访属性,有的磁道放内容。经过磁头找磁道,盘面旋转确定扇区,我们完成寻址。
磁盘的逻辑抽象结构
操作系统无法用CHS这种方法,因为软硬件是不能固定的,软件的寻址方式变化,硬件不可能要变,因此软件方面是不会使用这种方法的。
对于磁盘,盘面是由一个个同心圆构成,我们可以将该盘面抽象成我们小时候用的磁带一样,比如步步高学习机,在机子里,磁带被旋转卷成一个圆,我们就可以类比这个圆是盘面。
旋转的时候是一个圆,那么拉直的时候就是一个长条子,此时的扇面就是相当于磁带一段一段的,如下图:
 一个磁道是一个数组,因此用二维数组我们就可以表示出一个盘面,对于任何某一扇区的位置,我们只需知道它的下标位置即可,通过已知的下标位置,由于一个盘面的大小我们是知道的,我们也可以计算出他是哪一个盘面中的第几个。比如小标123456,同盘面大小取模再取余就能知晓扇区的位置。
一个磁道是一个数组,因此用二维数组我们就可以表示出一个盘面,对于任何某一扇区的位置,我们只需知道它的下标位置即可,通过已知的下标位置,由于一个盘面的大小我们是知道的,我们也可以计算出他是哪一个盘面中的第几个。比如小标123456,同盘面大小取模再取余就能知晓扇区的位置。
于是对磁盘的管理,就变成了对数组的管理。由数组下标就转化成磁盘的CHS了。当然操作系统以扇区为单位进行存取,也可以基于文件系统,按照文件块为单位进行数据存取。例如以8个扇区为一个文件快,直接一起写,在写时也是连续的。因此我们能通过起始地址找到八个块的所在地。
最终结论:对存储设备的管理,在os层,转换成了对数组的增删查改。
格式化
在内存管理方面,我们只需要管理其中一部分空间,剩余的由于与值顺序链接的,我们就可以管理这以快空间。
以分治的思想,将一个大的分区划分成一个个小的块,进行管理,最后将管理中心放在一块小空间即可。

而我们需要知道的文件的路径取决于就是我们对这些组做管理,文件的存储,分为两个部分,一个是文件信息的存储,一个是管理文件信息的存储。因为文件的内容与属性是分开存储的,因此文件信息管理的存储决定了文件信息的存储。
对于分区之后,在先将管理的数据写入块中,即格式化。因此在使用一个盘时,我们都是要先分区,在格式化。例如我们电脑的c盘,d盘就是分区,并且我们可以选择格式化,格式化的本质是清除我们自己的文件数据,对于文件管理数据是不会修改的。
inode
在Linux系统中,我们在使用ls指令时,还有一个选项:
ls -li //可查看文件的inode
一般情况,一个文件对应一个inode,基本上文件都有inode,inode是一个数字,在整个分区中具有唯一性,因此在Linux内核中,识别文件与文件名无关,而是依据inode。
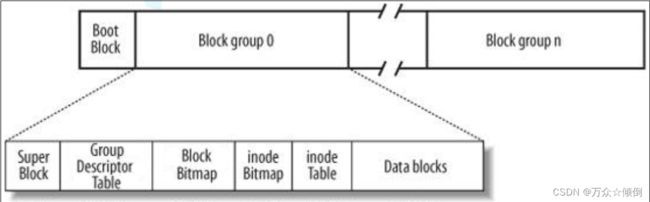
也就是上图,可以看到我们写入管理信息到块中有许多,我们先来看看inode table。
inode_table
一般叫做i节点表,inode table主要存放文件属性,所有者,最近修改时间等。i节点表里面也是存放了许多inode,inode大小为128字节,我们将它理解为一个数组,他的下标就是表示inode位置。
每一个分组(table)都有一个起始的start_inode与记录。在分区的唯一性就是自身位置加上start_inode来确定。
data_blocks
数据区,没有任何管理数据,只是一个以4KB的大小的数据块区域,那么一个块里面能存放这么多文件,如何确定文件对应的数据块? 其实在inode中,为我们维护了一个数组 blocks[ ],记录了位置。
inode bitmap
利用位图来记录这么多文件的使用情况,0表示未使用,1表示使用。
block bitmap
除了文件的使用情况,我们还需要记录数据块的使用情况,因此利用位图记录使用情况。
那么了解了这些我们大概能知道创建和删除文件本质上就是去修改inode位图,数据块位图里的某个位置,0变1,1变为0。所以并未真正的删除数据。
Block Group : 文件系统会根据分区的大小划分为数个 Block Group 。而每个 Block Group 都有着相 的结构组成。超级块( Super Block ):存放文件系统本身的结构信息。记录的信息主要有: bolck 和 inode 的总量, 未使用的block 和 inode 的数量,一个 block 和 inode 的大小,最近一次挂载的时间,最近一次写入数据的 时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block 的信息被破坏,可以说整个 文件系统结构就被破坏了。GDT , Group Descriptor Table :块组描述符,描述块组属性信息
了解了这些,可是我们一般在Linux中也不用inode啊,我们都是用文件名,这是怎么弄得?
因为用户只认识文件名,操作系统只认识Inode,因此我们需要将文件名与inode一一映射,
一一映射急就是键值对的关系,我们将文件名做为key值,将Inode作为valu,以这样方式一一映射。
因此文件名不属于文件属性。那么如何查找一个文件?其实就是先获取到文件的inode,再根据inode确定分区位置,确定inode编号,确定inode_table,但是我们是一层层往下找的,先从根目录开始,找到下一个目录,依次往下,知道我们需要的文件的位置。
这样找太慢了,于是进程会将当前的目录也会保存到cache中。
挂载
一个磁盘想要被使用,就需要将他分区,而想要使用这个分区,还需要将每一个分区都需要挂载到相应的目录上,挂载其实就是将目录的数据结构与文件的数据结构联系起来。
软硬链接
建立软链接:
ln -s file.c file.c.soft.link //给log文件建立软链接此时ls -li可以看到inode变化,对应的
![]()
建立硬链接:
ln test.c test.c.hard.link //后者硬链接前者![]()
再查看此时的inode没发生变化,但对应的inode编号数字增加了。链接数也发生了变化。
因此我们可以得出,软链接是一个独立的文件,硬链接不是一个独立的文件。因为没有独立的inode编号.
那么什么是软硬链接?
首先我们肯定队快捷方式很熟悉,我们的电脑是双击图标就可以把程序加载到内存中,开始运行这个程序,但事实上我们都是到我们在运行程序时都是运行它的exe文件,一般这个文件在目录下很深的地方,用户每次想加载该文件都需要找到他太国麻烦,因此就可以用一个链接文件当作exe文件,把它拿出来当作我们的快捷方式来加载程序。
而链接分了两种方式:
1.软链接就相当一个wndows的快捷方式,就是一个普通文件,可以快速定位文件。
2.硬链接不是一个独立的文件,从inode往后和目标文件是一个东西,本质上就是在指定目录内部的一组映射关系。
普通文件链接后链接数为1,而空目录连接后,默认链接数位2,这是因为他有两个隐藏文件:
.当前目录 ..上一级目录,他们都记录着对应的inode。
用户无法对目录建立硬链接,对于隐藏文件 .. 和.是系统创建的硬链接,但不允许用户来创建。
二,动静态库
什么是动静态库?
动态库(.a):程序在编译链接的时候,把库里的代码链接到可执行程序当中,运行的时候不再需要库文件。
静态库(.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码
注意:
1.一个与动态库链接的文件,仅仅包含它会使用到的函数接口地址的一个表,而不是函数所在文件的整个机器码
2.在程序运行之前,外部函数的机器码由操作系统从磁盘的动态库复制到内存当中,这个过程称为动态链接。
3.动态库可以在多个文件间共享,因此动态链接使得可执行文件更小,可以节省磁盘的空间,操作系统利用虚拟地址机制,使得物理空间对应的一份动态库可以被所有进程共享,节省了磁盘空间与内存。
为了更好的了解动静态库,我们分三个角度看待动静态库:
1.站在库的制作者角度
静态库:
制作一个静态库
首先库中是没有主函数的,比如我们现在搞一个加减乘除的一个库,先创建对应的头文件与.c文件
![]()
创建并完成这些文件的代码编写,之后再创建一个maintest.c,用于测试。
完成书写后,将所有文件编译成一个可执行:
gcc -o TEST Add.c Sub.c Mul.c Dic.c Maintest.c我们运行TEST,可以看到没什么问题,
我们以这种方式编译成可执行文件,但是这种放式并不是最佳方式,我们一般将所有.c文件都先编译成.o文件,再将我们需要的.o文件链接在一起。
gcc -c 源文件 -o目标.o文件
//一般我们直接使用gcc -c源文件 会自动生成同名的.o文件编写makefile以这样的方式去编译可执行:
TEST:Add.o Sub.o Mul.o Div.o Maintest.o
gcc -o $@ $^
%.o:%.c
gcc -c $<
#$<代表一个个的去取文件列表的文件
.PHONY:clean
clean:
rm -f *.o TEST
于是我们为了其他人想要使用对应的.o文件,我们将所有的.o文件与头文件都打包在一起,用的时候直接链接某一个你需要的.o文件。
故一般在编译文件时,我们只编译成.o文件即可,比如这里我们就将所由.o文件与头文件放在一个test目录下。该目录就当作是用户的目录,此时有一个Maintest.c是你的主程序,我们想将她编译成.o文件,之后想要链接哪一个.o文件,就一起gcc .o文件即可。
这里再将所有的.o文件打个包就是我们所说的库。、
打包.o文件
这里用ar(gnu归档工具进行打包)指令打包:
ar -rc .o文件 -o 目标文件 如打包我们这里的.o文件,我们在makefile中打包:
#这里我们用一个变量表示库的名字
static-lib=libmymath.a
$(static-lib):Add.o Sub.o Mul.o Div.o
ar rc $@ $^
%.o:%.c
gcc -c $<
.PHONY:clean
clean:
rm -f *.o *.a
之后创建的libmymath.a就是我们的静态库。
2.站在静态库使用者的角度
有了静态库,那么我们现在要去使用它,首先将头文件在拿到用户需要编译的目录下,头文件一般都是开放的,之后直接编译,我们发现它会报链接的错误,有了静态库和头文件还不行,我们还需要链接,我们自己写的第三方库gcc是不认识的,我们需要指定连接:
gcc 目标.c文件 -l 静态库 //链接静态库到目标文件中
这里哭的名字一般是要去掉lib与.a才是真实名字
如果还是不认识
gcc 目标.c文件 -l 名字 -L . //当前下的该库链接完成之后就会形成一个a.out的可执行文件。
此时对于gcc来说c标准库可以直接用,不需要指明链接,也就是第二方库。
gcc默认是动态链接的,有序使用动态库连接,如果子提供了静态库,还是会把库链接起来。
但是这又是是静态库,又是头文件,太挫了,所以最终呈现给用户的形式是将库文件与头文件分开的两个目录,并且在一个目录下,我们在makefile中进行分隔:
static-lib=libmymath.a
$(static-lib):Add.o Div.o Mul.o Sub.o
ar -rc $@ $^
%.o:%.c
gcc -c $<
.PHONY:output
output:
mkdir -p mymath_lib/include
mkdir -p mymath_lib/lib
cp -f *.h mymath_lib/include
cp -f *.a mymath_lib/lib
.PHONY:clean
clean:
rm -rf *.o *.a mymath_lib之后我们还可以将该目录压缩,其他用户需要用的是后给他压缩包,解压之后就有了该目录,使用的时候,使用指令:
gcc Maintest.c -I mymath-lib/include然后再链接库即可:
ac ar Maintest.c -l mymath -L mymath-lib/lib当然我们可以一起使用:
gcc Maintest.c -I mymath-lib/include -l mymath -L mymath-lib/lib动态库
作为制作者
动态库与静态库在这里的区别就是打包方式的不同:
首先打包时使用的指令为
gcc -shared -o 目标文件 源文件之后编译时我们还需要添加选想 -fPIC
gcc -fPIC -c .c文件动态库生成的Makefile为:
dy-lib=libmymath.so
$(dy-lib):Add.o Div.o Mul.o Sub.o
gcc -shared -o $@ $^ #打包围为动态库
%.o:%.c
gcc -fPIC -c $< #增加一个选项生成位置无关码
.PHONY:output
output:
mkdir -p mymath_lib/include
mkdir -p mymath_lib/lib
cp -f *.h mymath_lib/include
cp -f *.so mymath_lib/lib
.PHONY:clean
clean:
rm -rf *.o *.so mymath_lib
作为使用者
与静态库不同,动态库生成之后就没有链接错误了,不过有编译错误,会报错头文件找不到,因此只需要与静态库链接一样的指令,在编译时指定链接(link)我们的动态库:
gcc Maintest.c -I mymath_lib/include/ -l mymath -L mymath_lib/lib/
生成了可执行文件还是要依靠动态库,否则无法运行,而之前,我们指定动态库是编译器知道的,一旦生成完,可执行与动态库还是相互不认识,ldd查看动态库就会发现,找不到。这里有四种方法:
1.下载到我们的系统库里。直接将库拷贝到lib64里,之后gcc -l 指定的库,就可以成功运行了。
2.将我们的库与该路径下的一个文件建立软链接。在将该软链接移动到库上。这样只要有谁想找到这个库,我们就会迅速定位到该库。
当然我们建立软连接时最好给这个库的绝对路径,例如我这个:
![]()
3.在Linux中,还存在一个加载项LD_LIBRARY_PATH,加载库路径的环境变量。因此我们可以把动态库的路径找出来,然后导入环境变量。
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home//danchengwei/myfile/file2/test/mymath_lib/lib/libmymath.so4.直接更改系统配置文件
在系统目录下游体格etc/ld.so.conf.d/的配置文件目录,在目录里我们会创建一个文件里面用来存放你要找的动态库的路径。
如果我们的库既有动态也有静态库,默认使用动态库。
当然我们就可以使用别人的库,
ncurses库
下载之后就可以在lib64下找到它的动态库文件。
动态库加载
将方法的地址与可执行程序链接起来,因此动态库连接的程序不仅仅程序要加载,动态库也要加载,态库是一种共享库,它可以在程序运行时加载。在Linux中,您可以使用dlopen函数打开动态链接库,使用dlsym函数获取函数执行地址,使用dlclose函数关闭动态链接库。这些函数都在dlfcn.h头文件中声明.

在编译的时候,代码就有了虚拟地址,用基地址+偏移量表示,并一一映射,这种模式称为平坦模式。