vit细粒度图像分类(四)BT-Net学习笔记
1.摘要
为了改进在细粒度图像分类过程中类别差异难以提取的问题,本文提出了一种基于 Transformer 双线性网络的细粒度网络分类优化方法(BT-Net)。
首先,将输入图像通过不同卷积处理成不同长度的二维向量,然后,构建重复次数不同的编码器,最后,双网络分支将图像表示为来自两个 Transformer 的特征集合,得到更加丰富的互补特征信息,从而提高细粒度分类的精度。
实验结果表明,BT-Net 在 CUB-200-2011、Cars196 和 Stanford Dogs 数据集中,分类准确率分别获得了 89.4%,92.5%,94.8%,优于已有的双线性卷积神经网络。
2.问题
图像分类主要为了分别出不同类别的对象,如人和车。包括场景识别 [1] 、对象识别 [2] 。人脸识别 [3]等。而细粒度图像信噪比很低,区分度信息存在细微局部区域,例如车的品牌,鸟的品种。
2.1发现
细粒度图像分类根据网络训练是否需要人工额外的标注信息,分为强监督图像分类和弱监督图像
分类 [4] ,强监督图像分类算法需要图像类别标签和额 外 的 人 工 标 注 与 位 置 区 域 。 Wei 等 提 出Mask-CNN [5] 模 型 借 助 FCN(Fully ConvolutionalNetworks for Semantic Segmentation)学习部分分割模型,真实标记通过部位标注点得到部分区域的最小外接矩阵,但真实标记矩形框与获取信息存在差异,影响最终结果。
弱监督图像分类仅需要类别标签,舍弃人工标记的信息。Zhu 等人 [6] 提出基于卷积神经网络
(Convolution Neural Networks,CNN)注意力模型,没有强监督信息的指导下,两级注意力在很多情况下无法准确定位到有用区域。Lin 等 [7] 设计了一种双线性 卷 积 网 络 (Bilinear Convolution NeuralNetworks,B-CNN)模型,B-CNN 可看作 A 网络对图像进行局部区域的定位,B 网络对定位到的局部区域进行特征提取。A 和 B 网络之间发挥相互协调,相互互补的作用,模型在整个网络中完成了端到端的训练过程。
2.2发展
从 AlexNet [8] 广泛应用到图像分类,VGG [9] 、ResNet [10] 等卷积神经网络的发展,CNN 开始在计算机视觉等领域占主导地位。基于 CNNs 的框架能增加网络模块形式 [11] 、多种类连接方式 [12] ,复杂多样的卷积操作 [13] ,多种类特征融合 [14] ,基于视觉注意力 [15] 等方法应用于计算机视觉领域。虽然 CNN 的滤波器关注的是图像中部分像素,上述方法能一定程度上弥补 CNN 对图像的全局建模能力的不足,但是仍未获得较好的效果。Transformer 最开始因其强大的学习能力在自然语言处理(Natural Language Processing,NLP)领域被广泛应用 [16] ,研究人员逐渐将其扩展到计算机视觉任务 [17] 中。Wan 等 [18] 将图像进行下采样和像素聚类,将缺失的图像转化为表征序列作为输入补全像素。Carion 等 [17] 将 Transformer 整合为检测 pipeline中心构建块的目标检测框架,利用 Transformer 来进行物体检测和分割。Liu 等 [19] 通过 Transformer 的非局部相互作用以自我注意机制来捕捉更为细长结构和上下文信息进行自动驾驶车道标记检测。VisionTransformer [20] 利用全局注意力应用到全尺寸图像上。
2.3创新
Transformer 相比于 CNN 的优势在于对全局信息的把握更好,能弥补 CNN 对于图像全局依赖性
的不足,针对 CNN 对于细粒度图像局部区分细微差异可能定位不准和有效特征信息不能充分利用的问题,本文结合 B-CNN 信息互补的特点和Transformer 网络能提取全局信息的优势,设计并提出了双线性 Transformer 网络用于细粒度图像分类。本文的主要贡献如下:
1.提出了一种基于Transformer的双线性结构分类网络,利用了 Transformer 获取全局上下文信息
的优势。
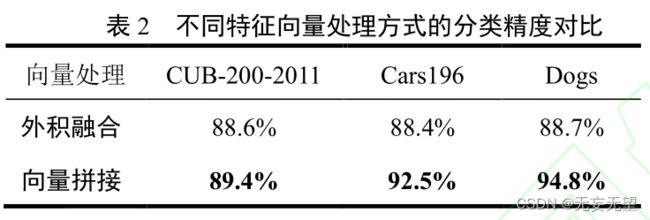
2. 将不同分支 Transformer 的特征向量进行拼接,把不同通道的特征进行融合处理,以此来加强
双分支的空间联系,充分表达通道内特征信息,以获取更多的细粒度信息,最终提高识别率。
3.双线性Transformer网络应用到细粒度图像分类领域中,进一步来满足工业界和学术界研究需求与应用场景。
4.BT-Net 网络面对细粒度图像数据集中,在分类结果上均取得了不错的表现。
3.网络
3.1整体结构
本文提出的 BT-Net 使用的双线性 Transformer分支并行结合的组成方式来对细粒度图像进行分类,网络架构图如图 1 所示。

从网络结构来说,就是并行的两个特征提取,因为两边的编码模块数目不同,则提取的特征会有所差异,编码模块多的提取的较为深层特征,编码模块少的提取较为浅层的特征。
就是两个位置编码的获取,从论文来看是没有差异的,只是因为编码模块数码不同,最后的结果就不同。
对于图像数据格式[H,W,C]而言,输入图像先经过不同的卷积层,然后将其展平为二维图像![]() ,其中(H,W)为原始图像分辨率,C 为通道数,(P,P)是每个图像块的分辨率,
,其中(H,W)为原始图像分辨率,C 为通道数,(P,P)是每个图像块的分辨率,
S=HW/P^2 是每个图像分成的总块数,再通过线性映射得到编码向量![]()
。计算公式为:

将编码向量输入 Transformer Encoder 编码器前,需要分别加入维度不同的位置编码向量 PE(PositionEmbedding) 与之前编码向量进行拼接。即![]() 。P i 为加入的位置
。P i 为加入的位置
编码。本文假设网络 B 映射后的向量比网络 A 的映射后的向量长度大。之后通过 Transformer Encoder层堆叠不同次数的编码器块 Block 层提取特征向量,将不同网络的特征向量进行融合送入到全连接层,最后得到最终的分类结果。
3.2 Transformer Encoder
Transformer Encoder 编码器层会分别重复堆叠编码器块 Block 不同的次数以此让模型去关注不同
方面信息。如图 2 所示,Block 编码器块由归一化Layer Norm 层、多头注意力 Multi-Head Attention、正则化 Dropout 层和多层感知块 MLP Block 组成。而 MLP Block 是由全连接层、GELU 激活函数和正则化 Dropout 层组成,在 MLP Block 层中第一个全连接层会把输入节点的个数增加 4 倍,在下一个全连接层还原原节点个数。

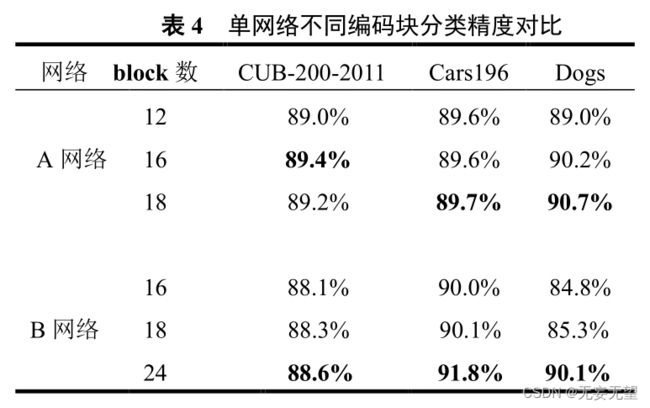
BT-Net 的编码器 Encoder分别堆叠了12个Blocks和24个Blocks模块组成,然后把各个注意力的信息综合,有助于网络获得多更加丰富的特征信息,不仅可以减少信息的损失和防止梯度消失,而且能对同一层网络的输出进行一个标准化的处理。Transformer Encoder 层输出的维度与输入的维度保持不变,只需要分别提取出对应插入的用于分类的可训练的参数 class[token],然后在进行向量融合。向量融合是为了达到与不同空间维度特征交互的目的,以此得到图像的不同的更多的有效的特征。最后将得到的向量输入到 Linear全连接层得到最后的分类结果。
4.实验
4.1实验设置
4.1.1 数据集
本文实验部分采用常用的 3 个细粒度图像分类的数据集:CUB-200-2011 鸟类数据集, Cars196 汽
车数据集 [21] , Stanford Dogs 狗类数据集进行实验评估。
4.1.2 实验细节
本文算法 BT-Net 的提出是由基于开源的Pytorch 深 度 学 习 框 架 来 实 现 , 在 处 理 器Intel®Core™ i9-9900K CPU @ 3.60GHz × 16,TITAN RTX/PCIe/SSE2 上进行训练与测试。输入图片的大小归一化为 224×224,本文采用随机梯度下降(SGD)作为整体优化器和反向传播算法实现对整个网络模型的训练。为了防止出现过拟合的现象用增强数据的策略来提高性能,在训练阶段使用随机裁剪与随机翻转。本文初始学习速率设置为 0.001,动量因子为 0.9,权重衰减为 0.00005,最大迭代次数为 100,对所有的数据集设置的批次大小为 16。
4.2对比试验

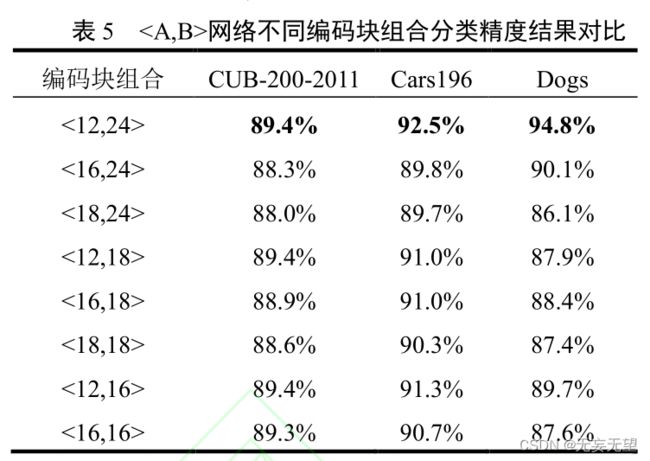
4.3消融实验