flink架构
Flink 是一个分布式系统,需要有效的分配和管理 计算资源,以便执行流式处理应用程序。它集成了 使用所有常见的群集资源管理器,例如 Hadoop YARN 和 Kubernetes,但也可以设置为作为 独立集群,甚至作为库。
本节概述了 Flink 的架构,并描述了 Flink 的架构如何 主要组件交互以执行应用程序并从故障中恢复。
Flink 集群剖析#
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或多个 TaskManager。

客户端不是运行时和程序执行的一部分,但用于 准备数据流并将其发送到 JobManager。之后,客户端可以 断开连接(分离模式),或保持连接以接收进度报告 (附加模式)。客户端作为 Java/Scala 程序的一部分运行 触发执行,或在命令行进程中触发。./bin/flink run ...
JobManager 和 TaskManager 可以通过多种方式启动:直接在 计算机作为独立群集、容器中或由资源管理 像 YARN 这样的框架。 TaskManager 连接到 JobManagers,宣布自己可用,并且 被分配了工作。
作业管理器#
JobManager 在协调 Flink 应用的分布式执行方面有很多职责: 它决定何时安排下一个任务(或一组任务),对完成做出反应 任务或执行失败,协调检查点,并协调恢复 失败等。此过程由三个不同的组件组成:
-
资源管理器
ResourceManager 负责资源去/分配和 在 Flink 集群中配置 — 它管理任务槽,这些任务槽是 Flink 集群中的资源调度单元(详见 TaskManagers)。 Flink 为不同的环境实现了多个 ResourceManager,并且 资源提供程序,例如 YARN、Kubernetes 和独立 部署。在独立设置中,ResourceManager 只能分发 可用 TaskManager 的插槽,并且无法启动新的 TaskManager 自己。
-
调度
Dispatcher 提供了一个 REST 接口来提交 Flink 应用程序 执行并为每个提交的作业启动一个新的 JobMaster。它 还运行 Flink WebUI 以提供有关作业执行的信息。
-
工作主管
JobMaster 负责管理单个 JobGraph 的执行。 一个 Flink 集群中可以同时运行多个作业,每个作业都有其 自己的 JobMaster。
始终至少有一个 JobManager。高可用性设置可能具有 多个 JobManager,其中一个始终是领导者,其他是备用的(请参阅高可用性 (HA))。
任务管理器#
TaskManager(也称为工作线程)执行数据流的任务,并缓冲和交换数据 流。
必须始终至少有一个 TaskManager。TaskManager 中资源调度的最小单位是任务槽。任务槽的数量 TaskManager 表示并发处理任务的数量。请注意, 一个任务槽中可以执行多个操作员(请参阅任务和操作员 链)。
返回页首
任务和操作链#
对于分布式执行,Flink 将 operator 子任务链接在一起,成为任务。每个任务由一个线程执行。将运算符链接在一起 tasks 是一个有用的优化:它减少了线程到线程的开销 切换和缓冲,并在降低整体吞吐量的同时提高整体吞吐量 延迟。可以配置链接行为;有关详细信息,请参阅链接文档。
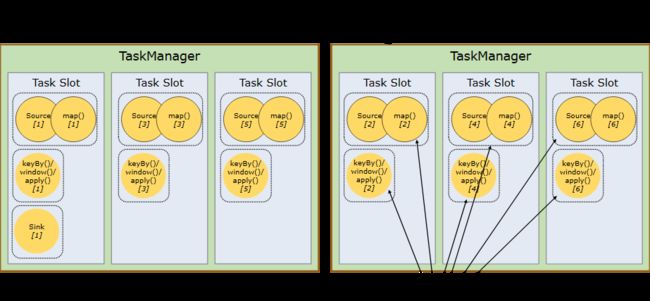
下图中的示例数据流使用五个子任务执行,并且 因此有五个并行线程。

任务槽和资源#
每个工作线程(TaskManager)都是一个JVM进程,可以执行一个或多个 子任务在单独的线程中。为了控制 TaskManager 接受的任务数量,它 有所谓的任务槽(至少一个)。
每个任务槽代表 TaskManager 的固定资源子集。一个 例如,具有三个插槽的 TaskManager 将专用其托管的 1/3 内存到每个插槽。安排资源意味着子任务不会 与其他作业中的子任务竞争托管内存,但具有 一定数量的预留托管内存。请注意,不会发生 CPU 隔离 这里;目前,槽仅分隔任务的托管内存。
通过调整任务槽的数量,用户可以定义子任务的 彼此隔离。每个 TaskManager 有一个槽意味着每个任务 组在单独的 JVM 中运行(可以在单独的容器中启动,用于 示例)。拥有多个槽意味着更多的子任务共享同一个 JVM。任务 在同一 JVM 中共享 TCP 连接(通过多路复用)和检测信号 消息。它们还可以共享数据集和数据结构,从而减少 每个任务的开销。
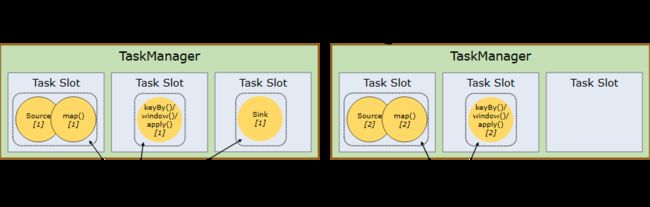
默认情况下,Flink 允许子任务共享槽,即使它们是 不同的任务,只要它们来自同一个工作。结果是那个 槽可以容纳作业的整个管道。允许此插槽共享具有 两个主要好处:
-
Flink 集群需要的任务槽数量与最高并行度完全相同 在作业中使用。无需计算多少个任务(具有不同的任务 并行性)一个程序总共包含。
-
更容易获得更好的资源利用率。如果没有插槽共享, 非密集型 source/map() 子任务将阻止与 资源密集型窗口子任务。通过插槽共享,增加 在我们的示例中,从 2 到 6 的基本并行性可以充分利用 分配的资源,同时确保繁重的子任务是公平的 分布在 TaskManager 之间。
Flink 应用执行#
Flink 应用程序是生成一个或多个 Flink 的任何用户程序 工作从它的方法。这些作业的执行可以在 本地 JVM () 或远程设置具有多个 机器 ()。对于每个程序,都提供了控制作业执行(例如设置并行度)和与之交互的方法 外部世界(参见 Flink 程序剖析)。main()LocalEnvironmentRemoteEnvironmentExecutionEnvironment
Flink 应用程序的作业可以提交到长时间运行的 Flink 会话集群,也可以提交到专用的 Flink 作业 集群(已弃用)或 Flink 应用集群。这些选项之间的区别主要与集群的生命周期和资源有关 隔离保证。
Flink 应用集群#
-
集群生命周期:Flink 应用集群是专用的 Flink 仅从一个 Flink 应用程序执行作业的集群,并且该方法在集群而不是客户端上运行。工作 提交过程是一步到位的:你不需要启动一个 Flink 集群 首先,然后将作业提交到现有集群会话;相反,你 将应用程序逻辑和依赖项打包到可执行作业 JAR 和 集群入口点 () 负责调用提取 JobGraph 的方法。 这允许您像部署任何其他应用程序一样部署 Flink 应用程序 例如,Kubernetes。Flink 应用集群的生命周期为 因此绑定到 Flink 应用的生命周期。
main()ApplicationClusterEntryPointmain() -
资源隔离:在 Flink 应用集群中,ResourceManager 和 Dispatcher 的范围限定为单个 Flink 应用程序,它提供了一个 比 Flink 会话集群更好的关注点分离。
Flink 会话集群#
-
集群生命周期:在 Flink 会话集群中,客户端连接到 预先存在的、长时间运行的集群,可以接受多个作业提交。 即使在完成所有作业后,集群(和 JobManager)也会 保持运行,直到手动停止会话。Flink 的生命周期 因此,会话集群不绑定任何 Flink 作业的生命周期。
-
资源隔离:TaskManager 插槽由 ResourceManager 在作业提交时发布,并在作业完成后释放。 由于所有作业都共享同一个集群,因此存在一些竞争 群集资源 — 例如提交作业阶段的网络带宽。一 此共享设置的局限性在于,如果一个 TaskManager 崩溃,则所有 在此 TaskManager 上运行任务的作业将失败;以类似的方式,如果 JobManager 上发生一些致命错误,它将影响所有正在运行的作业 在群集中。
-
其他注意事项:拥有预先存在的集群可以节省大量成本 申请资源和启动 TaskManager 的时间。这是 在作业执行时间非常短且 启动时间过长会对端到端用户体验产生负面影响,因为 短查询的交互式分析就是这种情况,这是可取的 作业可以使用现有资源快速执行计算。
以前,Flink 会话集群也称为 Flink 集群。 session mode
Flink 作业集群(已弃用)#
Per-job 模式仅支持 YARN,在 Flink 1.15 中已被弃用。 它将在 FLINK-26000 中删除。 请考虑应用程序模式,以便在 YARN 上为每个作业启动专用集群。
-
集群生命周期:在 Flink 作业集群中,可用的集群管理器 (与 YARN 一样)用于为每个提交的作业启动一个集群 并且此群集仅适用于该作业。在这里,客户至上 从集群管理器请求资源以启动 JobManager,并且 将作业提交到在此进程中运行的 Dispatcher。任务管理器 然后根据作业的资源要求延迟分配。一次 作业完成,Flink 作业集群被拆除。
-
资源隔离:JobManager 中的致命错误仅影响该 Flink 作业集群中运行的一个作业。
-
其他注意事项:因为 ResourceManager 必须应用并等待 用于外部资源管理组件以启动 TaskManager 处理和分配资源,Flink 作业集群更适合大型 长时间运行、具有高稳定性要求且不 对较长的启动时间敏感。