Presto源码阅读——如何获取Hive中的Metadata(HMS+HDFS)
Presto源码阅读——如何获取Hive中的Metadata(HMS+HDFS)
本文的Metadata定义
SQL on Hadoop系统在执行一个query时所需要的Metadata主要有两部分
- Hive中的TableSchema信息和Partition信息,这部分从HMS(Hive MetaStore)中拿到
- HDFS中的文件信息(包括Block Location信息),这部分从HDFS NameNode中拿到
TableSchema主要用在语义分析阶段,即在sql字符串被语法分析解析成一棵抽象语法树(AST)后,语义分析根据TableSchema来判断sql是否合法,以及理解这句SQL真正要做什么。比如说在AST里,我们只知道输出的某一列是tableA.col1 + tableB.col2,并不知道这样加起来是否合法,因为还不知道col1和col2的类型。再比如说在AST里,我们只能看到各个table的名字,具体的它是一个view还是一个table还不清楚。这些都需要在语义分析阶段来完成。
Partition信息主要用来获取HDFS上的目录路径,这样我们可以得到需要读取的所有文件的元信息(路径、文件长度、文件类型等),从而才能分布式地去执行。
为什么要研究这个问题
个人认为Impala的Metadata管理有很大问题,Table的Metadata是作为一个整体缓存在catalog里的。当某个Table初次被使用时,impalad会请求catalogd去加载它全量的Metadata,即不管它是怎么被使用的,只要出现了,我就把Metadata全部加载进来并缓存在各个节点的catalog中。要知道对于一些大表,Block Location的信息是很大的(每个文件被切成多个Block,每个Block有三个复本的位置),全量加载它们是很费时的。这就会导致我第一次访问一个大表时,即使只是用DESCRIBE看一下列结果,不涉及数据读取,也要花很长时间。有人会说这种Cache的方案只会在第一次访问Table时比较恶心,后面就好了。问题是当全表的Metadata量非常大时,Cache就会被撑爆然后OOM了……是的,Impala里的Catalog Cache也没有evict机制。相关的ticket有
- IMPALA-3127 旨在将Table的Metadata再细分为各个Partition的Metadata,只加载所需的Partition的Metadata。这能解决初次访问是 describe table 或只读少量数据的SQL执行慢的问题,但不能解决如果Table的Metadata太大,最终Catalog Cache被撑爆的问题。
- IMPALA-6729 是我提的,想干脆就不要缓存Block Location了,更严格地说,是不要缓存所有File级别的Metadata了。这样至少Impala还能在大数仓(即存在一些很大的Fact表)环境下存活,因为Catalog Cache不可能再被单个表的Metadata塞爆。这种方案再来的损失就是每次query plan的时候都需要去拿Block Location信息,没有了Cache的加速。
我司的Presto也是部署在同样的数据仓库里,面对同样的大表,为什么Presto就能正常工作呢?Presto获取Hive中的Metadata有两种实现:
- CachingHiveMetastore: 像Impala一样做了catalog的缓存,但缓存的是除了Block Location之外的所有元信息. Cache机制主要由 hive.metastore-cache-ttl 和 hive.metastore-refresh-interval 两个配置来控制。前者控制cache的存活时间,默认设为0,表示不启用这种cache机制。后者控制cache自动刷新的频率,默认为1ms.
- BridgingHiveMetastore: 不做任何Cache,每次需要的Metadata都直接调HiveMetaStore的API去拿。这是默认实现。
那么问题来了,BridgingHiveMetastore是怎么做到只拿需要的Metadata呢?为什么不做cache其性能还可以接受,有什么优化?我们带着这两个问题来读源码。
源码阅读的入口
如何在茫茫源码里找到切入口开始看是一个关键点,我推荐“堆栈切入法”,即通过报错堆栈来开始看源码。这样很多诸如定位虚函数实现的问题直接就有了答案。这里给出一个经典的报错堆栈:
presto:default> select count(distinct source_id) from my_table where hour = '2017092723' and event_type = 'application_opened';
Query 20180405_032315_02473_jwja8 failed: Query over table 'default.my_table' can potentially read more than 100000 partitions
com.facebook.presto.spi.PrestoException: Query over table 'default.my_table' can potentially read more than 100000 partitions
at com.facebook.presto.hive.HivePartitionManager.getPartitions(HivePartitionManager.java:144)
at com.facebook.presto.hive.HiveMetadata.getTableLayouts(HiveMetadata.java:1096)
at com.facebook.presto.spi.connector.classloader.ClassLoaderSafeConnectorMetadata.getTableLayouts(ClassLoaderSafeConnectorMetadata.java:72)
at com.facebook.presto.metadata.MetadataManager.getLayouts(MetadataManager.java:307)
at com.facebook.presto.sql.planner.optimizations.MetadataQueryOptimizer$Optimizer.visitAggregation(MetadataQueryOptimizer.java:136)
at com.facebook.presto.sql.planner.optimizations.MetadataQueryOptimizer$Optimizer.visitAggregation(MetadataQueryOptimizer.java:85)
at com.facebook.presto.sql.planner.plan.AggregationNode.accept(AggregationNode.java:214)
at com.facebook.presto.sql.planner.plan.SimplePlanRewriter$RewriteContext.rewrite(SimplePlanRewriter.java:84)
at com.facebook.presto.sql.planner.plan.SimplePlanRewriter$RewriteContext.lambda$defaultRewrite$0(SimplePlanRewriter.java:73)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.Collections$2.tryAdvance(Collections.java:4717)
at java.util.Collections$2.forEachRemaining(Collections.java:4725)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at com.facebook.presto.sql.planner.plan.SimplePlanRewriter$RewriteContext.defaultRewrite(SimplePlanRewriter.java:74)
at com.facebook.presto.sql.planner.plan.SimplePlanRewriter.visitPlan(SimplePlanRewriter.java:38)
at com.facebook.presto.sql.planner.plan.SimplePlanRewriter.visitPlan(SimplePlanRewriter.java:22)
at com.facebook.presto.sql.planner.plan.PlanVisitor.visitOutput(PlanVisitor.java:49)
at com.facebook.presto.sql.planner.plan.OutputNode.accept(OutputNode.java:82)
at com.facebook.presto.sql.planner.plan.SimplePlanRewriter.rewriteWith(SimplePlanRewriter.java:32)
at com.facebook.presto.sql.planner.optimizations.MetadataQueryOptimizer.optimize(MetadataQueryOptimizer.java:82)
at com.facebook.presto.sql.planner.LogicalPlanner.plan(LogicalPlanner.java:130)
at com.facebook.presto.sql.planner.LogicalPlanner.plan(LogicalPlanner.java:121)
at com.facebook.presto.execution.SqlQueryExecution.doAnalyzeQuery(SqlQueryExecution.java:312)
at com.facebook.presto.execution.SqlQueryExecution.analyzeQuery(SqlQueryExecution.java:291)
at com.facebook.presto.execution.SqlQueryExecution.start(SqlQueryExecution.java:247)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745) 这里my_table是一张以hour和event_type作为partition列的表,Query里已经指明了一个partition,但还是报错说怀疑要读超过十万个partition(是的,这个表有超过十万个partition)。这显然是Presto的一个bug,但我们先不管这个。在Presto Web UI可以找到上述堆栈。可以看到是在SQL planning阶段出的错,我们可以从第一个有意义的presto函数开始,那就是 SqlQueryExecution#start(源码对应的Presto版本是0.179)。
(注:后面会出现很多Presto里的基本概念,还不清晰的同学请先查看:Presto基本概念)
SqlQueryExecution#start
一个query的执行从这里开始,在这之前的很多逻辑如Resource Group的等待和调度等我们就不管了,跟我们主题不相关。函数代码很简单:
public void start()
{
try (SetThreadName ignored = new SetThreadName("Query-%s", stateMachine.getQueryId())) {
try {
// transition to planning
if (!stateMachine.transitionToPlanning()) {
// query already started or finished
return;
}
// analyze query
PlanRoot plan = analyzeQuery();
metadata.beginQuery(getSession(), plan.getConnectors());
// plan distribution of query
planDistribution(plan);
// transition to starting
if (!stateMachine.transitionToStarting()) {
// query already started or finished
return;
}
// if query is not finished, start the scheduler, otherwise cancel it
SqlQueryScheduler scheduler = queryScheduler.get();
if (!stateMachine.isDone()) {
scheduler.start();
}
}
catch (Throwable e) {
fail(e);
Throwables.propagateIfInstanceOf(e, Error.class);
}
}
}stateMachine是管理query状态的,metadata#beginQuery在Hive的场景中没有实现,我们都不用管,因此代码逻辑主要有以下几句话:
PlanRoot plan = analyzeQuery(); // 生成执行计划
planDistribution(plan); // 生成调度器scheduler
scheduler.start(); // 启动query调度器
下面我们依次介绍这三个部分。
SqlQueryExecution#analyzeQuery
analyzeQuery函数的实现主要是调了doAnalyzeQuery,这个才是重点。我们刨去不关心的代码,这个函数的主体如下:
// 语义分析
Analyzer analyzer = new Analyzer(stateMachine.getSession(), metadata, sqlParser, accessControl, Optional.of(queryExplainer), parameters);
Analysis analysis = analyzer.analyze(statement);
// 生成逻辑计划
PlanNodeIdAllocator idAllocator = new PlanNodeIdAllocator();
LogicalPlanner logicalPlanner = new LogicalPlanner(stateMachine.getSession(), planOptimizers, idAllocator, metadata, sqlParser, costCalculator);
Plan plan = logicalPlanner.plan(analysis);
queryPlan.set(plan);
// 将逻辑计划切成PlanFragment
SubPlan subplan = PlanFragmenter.createSubPlans(stateMachine.getSession(), metadata, plan);
// Explan语句的特殊标记
boolean explainAnalyze = analysis.getStatement() instanceof Explain && ((Explain) analysis.getStatement()).isAnalyze();
// 最后返回一个PlanRoot
return new PlanRoot(subplan, !explainAnalyze, extractConnectors(analysis));我们主要看下前三部分在做什么。
1. Analyzer#analyze(Statement statement)
函数接收的Statement对象是抽象语法树(AST)的根节点,因此在这之前已经做完语法分析了,这个阶段做的是语义分析(Semantic Analysis)。这部分代码我们要弄明白的问题是,Hive中的TableSchema是怎么获取的。函数最终调到 StatementAnalyzer#analyze:
public Analysis analyze(Statement statement) {
return analyze(statement, false);
}
public Analysis analyze(Statement statement, boolean isDescribe) {
Statement rewrittenStatement = StatementRewrite.rewrite(session, metadata, sqlParser, queryExplainer, statement, parameters, accessControl);
Analysis analysis = new Analysis(rewrittenStatement, parameters, isDescribe);
StatementAnalyzer analyzer = new StatementAnalyzer(analysis, metadata, sqlParser, accessControl, session);
analyzer.analyze(rewrittenStatement, Optional.empty());
return analysis;
}我们看 StatementAnalyzer#analyze 的实现:
public Scope analyze(Node node, Optional outerQueryScope)
{
return new Visitor(outerQueryScope).process(node, Optional.empty());
} 只见它创建了一个StatementAnalyzer$Visitor 对象,然后调用visitor的 process 方法。Presto里的Visitor模式是用得非常优雅的,语义分析的这个Visitor的父类的父类是 AstVisitor,这里R是每个visit接口的返回值类型,C是每个visit接口额外接收的一个Context对象的类型。
接下来的这部分代码有点难跟,因为visitor模式跳转有点多。我们还是用“堆栈切入法”,找个椎栈来指导我们。随便写个select abc from tableA 这样的SQL,确保tableA确实没有abc这一列,然后我们就能等到堆栈:
com.facebook.presto.sql.analyzer.SemanticException: line 1:8: Column 'abc' cannot be resolved
at com.facebook.presto.sql.analyzer.SemanticExceptions.missingAttributeException(SemanticExceptions.java:30)
at com.facebook.presto.sql.analyzer.Scope.lambda$resolveField$0(Scope.java:104)
at java.util.Optional.orElseThrow(Optional.java:290)
at com.facebook.presto.sql.analyzer.Scope.resolveField(Scope.java:104)
at com.facebook.presto.sql.analyzer.ExpressionAnalyzer$Visitor.visitIdentifier(ExpressionAnalyzer.java:371)
at com.facebook.presto.sql.analyzer.ExpressionAnalyzer$Visitor.visitIdentifier(ExpressionAnalyzer.java:282)
at com.facebook.presto.sql.tree.Identifier.accept(Identifier.java:51)
at com.facebook.presto.sql.tree.StackableAstVisitor.process(StackableAstVisitor.java:26)
at com.facebook.presto.sql.analyzer.ExpressionAnalyzer$Visitor.process(ExpressionAnalyzer.java:301)
at com.facebook.presto.sql.analyzer.ExpressionAnalyzer.analyze(ExpressionAnalyzer.java:258)
at com.facebook.presto.sql.analyzer.ExpressionAnalyzer.analyzeExpression(ExpressionAnalyzer.java:1472)
at com.facebook.presto.sql.analyzer.StatementAnalyzer$Visitor.analyzeExpression(StatementAnalyzer.java:1835)
at com.facebook.presto.sql.analyzer.StatementAnalyzer$Visitor.analyzeSelect(StatementAnalyzer.java:1647)
at com.facebook.presto.sql.analyzer.StatementAnalyzer$Visitor.visitQuerySpecification(StatementAnalyzer.java:864)
at com.facebook.presto.sql.analyzer.StatementAnalyzer$Visitor.visitQuerySpecification(StatementAnalyzer.java:242)
at com.facebook.presto.sql.tree.QuerySpecification.accept(QuerySpecification.java:127)
at com.facebook.presto.sql.tree.AstVisitor.process(AstVisitor.java:27)
at com.facebook.presto.sql.analyzer.StatementAnalyzer$Visitor.process(StatementAnalyzer.java:254)
at com.facebook.presto.sql.analyzer.StatementAnalyzer$Visitor.process(StatementAnalyzer.java:264)
at com.facebook.presto.sql.analyzer.StatementAnalyzer$Visitor.visitQuery(StatementAnalyzer.java:605)
at com.facebook.presto.sql.analyzer.StatementAnalyzer$Visitor.visitQuery(StatementAnalyzer.java:242)
at com.facebook.presto.sql.tree.Query.accept(Query.java:94)
at com.facebook.presto.sql.tree.AstVisitor.process(AstVisitor.java:27)
at com.facebook.presto.sql.analyzer.StatementAnalyzer$Visitor.process(StatementAnalyzer.java:254)
at com.facebook.presto.sql.analyzer.StatementAnalyzer.analyze(StatementAnalyzer.java:228)
at com.facebook.presto.sql.analyzer.Analyzer.analyze(Analyzer.java:72)
at com.facebook.presto.sql.analyzer.Analyzer.analyze(Analyzer.java:64)
at com.facebook.presto.execution.SqlQueryExecution.doAnalyzeQuery(SqlQueryExecution.java:305)
at com.facebook.presto.execution.SqlQueryExecution.analyzeQuery(SqlQueryExecution.java:291)
at com.facebook.presto.execution.SqlQueryExecution.start(SqlQueryExecution.java:247)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)可以看到StatementAnalyzer$Visitor#process进来后的一步跳转过程,我们从 visitQuerySpecification 开始看,这是访问query的主体部分。在函数里可以看到第一步是 analyzeFrom,后面才有堆栈里的 analyzeSelect:
@Override
protected Scope visitQuerySpecification(QuerySpecification node, Optional scope) {
...
// 分析query的FROM语句块
Scope sourceScope = analyzeFrom(node, scope);
// 分析query的WHERE语句块
node.getWhere().ifPresent(where -> analyzeWhere(node, sourceScope, where));
// 分析query的SELECT语句块,即Select列表
List outputExpressions = analyzeSelect(node, sourceScope);
... 因此我们首先要看analyzeFrom里做了什么,我们主要关心TableSchema是怎么获取的,因此我们只需要看 visitTable 做了什么。函数比较长,有一百多行,我们可以忽略前面的 if (!table.getName().getPrefix().isPresent()) 分支和 if (optionalView.isPresent()) 分支,只关心最普通的Table处理逻辑。那么简化后的代码就比较短了:
Optional tableHandle = metadata.getTableHandle(session, name);
...
accessControl.checkCanSelectFromTable(session.getRequiredTransactionId(), session.getIdentity(), name);
TableMetadata tableMetadata = metadata.getTableMetadata(session, tableHandle.get());
Map columnHandles = metadata.getColumnHandles(session, tableHandle.get());
// TODO: discover columns lazily based on where they are needed (to support connectors that can't enumerate all tables)
ImmutableList.Builder fields = ImmutableList.builder();
for (ColumnMetadata column : tableMetadata.getColumns()) {
Field field = Field.newQualified(
table.getName(),
Optional.of(column.getName()),
column.getType(),
column.isHidden(),
Optional.of(name),
false);
fields.add(field);
ColumnHandle columnHandle = columnHandles.get(column.getName());
checkArgument(columnHandle != null, "Unknown field %s", field);
analysis.setColumn(field, columnHandle);
}
analysis.registerTable(table, tableHandle.get());
return createAndAssignScope(table, scope, fields.build()); TableHandle实际由一堆字符串组成(如下图)。
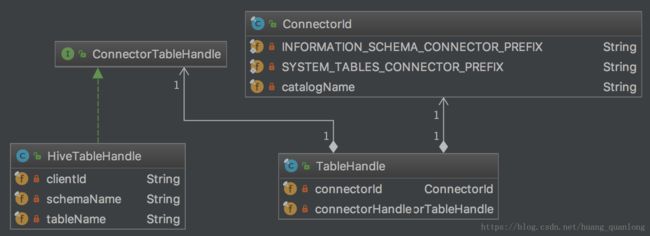
TableMetadata才是真正拿metadata的类,后面的for循环把它的各列都取了出来,最后塞给createAndAssignScope,也就是把TableSchema塞进了对应的Scope对象里。
对Hive MetaStore的请求主要发生在生成TableMetadata对象的那一行,默认配置下最终调到BridgingHiveMetastore去。反向的调用堆栈如下:
ThriftHiveMetastore.getTable(String, String) (com.facebook.presto.hive.metastore)
BridgingHiveMetastore.getTable(String, String) (com.facebook.presto.hive.metastore)
SemiTransactionalHiveMetastore.getTable(String, String) (com.facebook.presto.hive.metastore)
HiveMetadata.getTableMetadata(SchemaTableName) (com.facebook.presto.hive)
HiveMetadata.getTableMetadata(ConnectorSession, ConnectorTableHandle) (com.facebook.presto.hive)
MetadataManager.getTableMetadata(Session, TableHandle) (com.facebook.presto.metadata)
Visitor in StatementAnalyzer.visitTable(Table, Optional) (com.facebook.presto.sql.analyzer) ThriftHiveMetastore#getTable就会获得org.apache.hadoop.hive.metastore.api.Table对象,从而TableSchema信息就拿全了。
后面的语义分析我们就不再看了,有兴趣的同学可以沿着该Visitor的analyzeExpression函数继续看各列的检查,跟着上面的堆栈走就行了。
2. LogicalPlanner#plan
这部分根据语义分析的结果生成逻辑计划,即生成一棵由PlanNode组成的树。顶层代码如下:
public Plan plan(Analysis analysis) {
return plan(analysis, Stage.OPTIMIZED_AND_VALIDATED);
}
public Plan plan(Analysis analysis, Stage stage) {
// 生成PlanNode组成的树
PlanNode root = planStatement(analysis, analysis.getStatement());
// 调用各种Optimizer,这里主要是做表达式下推、插入Exchange节点等
if (stage.ordinal() >= Stage.OPTIMIZED.ordinal()) {
for (PlanOptimizer optimizer : planOptimizers) {
root = optimizer.optimize(root, session, symbolAllocator.getTypes(), symbolAllocator, idAllocator);
requireNonNull(root, format("%s returned a null plan", optimizer.getClass().getName()));
}
}
// 逻辑计划校验
if (stage.ordinal() >= Stage.OPTIMIZED_AND_VALIDATED.ordinal()) {
// make sure we produce a valid plan after optimizations run. This is mainly to catch programming errors
PlanSanityChecker.validate(root, session, metadata, sqlParser, symbolAllocator.getTypes());
}
// 计划各个节点的cost
Map planNodeCosts = costCalculator.calculateCostForPlan(session, symbolAllocator.getTypes(), root);
// 将上述结果封装成一个Plan对象返回
return new Plan(root, symbolAllocator.getTypes(), planNodeCosts);
} 我们主要想看Presto怎么拿metadata,这里深入下去代码会有点多。最终是调的HivePartitionManager的接口:
HivePartitionManager#getPartitions(SemiTransactionalHiveMetastore metastore,
ConnectorTableHandle tableHandle,
Constraint constraint)
注意到这里后的参数是constraint,这个是用来给partition剪枝的。从我们最初的堆栈能知道,Presto在本阶段会获取Table的Partition信息。
3. PlanFragmenter#createSubPlans
这一步的输出是一个SubPlan对象,实际是一棵树的根节点。我们看SubPlan的定义:
@Immutable
public class SubPlan
{
private final PlanFragment fragment;
private final List children;
...
} 可以知道一个SubPlan和一个PlanFragment对应,从而后续会跟一个Stage对应上。这一步没有metadata的获取,我们跳过。
SqlQueryExecution#planDistribution
我们回到SqlQueryExecution类中来,planDistribution这个函数不长,刨去stateMachine等我们不关心的代码,剩下的就很精简了:
// plan the execution on the active nodes
DistributedExecutionPlanner distributedPlanner = new DistributedExecutionPlanner(splitManager);
StageExecutionPlan outputStageExecutionPlan = distributedPlanner.plan(plan.getRoot(), stateMachine.getSession());
PartitioningHandle partitioningHandle = plan.getRoot().getFragment().getPartitioningScheme().getPartitioning().getHandle();
OutputBuffers rootOutputBuffers = createInitialEmptyOutputBuffers(partitioningHandle)
.withBuffer(OUTPUT_BUFFER_ID, BROADCAST_PARTITION_ID)
.withNoMoreBufferIds();
// build the stage execution objects (this doesn't schedule execution)
SqlQueryScheduler scheduler = new SqlQueryScheduler(...)
queryScheduler.set(scheduler);第一步是生成StageExecutionPlan,即每个Stage的执行对象。第二步是设置Exchange节点的OutputBuffers。第三步是生成SqlQueryScheduler。我们主要看下第一步。
DistributedExecutionPlanner#plan
这里又生成了一个Visitor,用它来遍历传入的执行计划树。
private StageExecutionPlan plan(SubPlan root, Visitor visitor)
{
PlanFragment currentFragment = root.getFragment();
// get splits for this fragment, this is lazy so split assignments aren't actually calculated here
Map splitSources = currentFragment.getRoot().accept(visitor, null);
// create child stages
ImmutableList.Builder dependencies = ImmutableList.builder();
for (SubPlan childPlan : root.getChildren()) {
dependencies.add(plan(childPlan, visitor));
}
return new StageExecutionPlan(
currentFragment,
splitSources,
dependencies.build());
} 这个Visitor主要用来生成一个Map,它维护了从PlanNodeId到SplitSource的映射。SplitSource顾名思义就是产生Split的东西,可以简单看下这个接口的定义:
public interface SplitSource extends Closeable {
ConnectorId getConnectorId();
ConnectorTransactionHandle getTransactionHandle();
ListenableFuture> getNextBatch(int maxSize);
@Override
void close();
boolean isFinished();
} 最重要的是getNextBatch函数,返回的是一个Future,用来获取一个List的Split。
我们来看来SplitSource对象是怎么获得的,从该Visitor的visitTableScan方法逐步跟进,可以看到如下的反向堆栈:
HiveSplitManager.getSplits(ConnectorTransactionHandle, ConnectorSession, ConnectorTableLayoutHandle) (com.facebook.presto.hive)
SplitManager.getSplits(Session, TableLayoutHandle) (com.facebook.presto.split)
Visitor in DistributedExecutionPlanner.visitTableScan(TableScanNode, Void) (com.facebook.presto.sql.planner) 最终是调用了HiveSplitManager#getSplits函数,该函数最后几行代码为:
HiveSplitLoader hiveSplitLoader = new BackgroundHiveSplitLoader(...);
HiveSplitSource splitSource = new HiveSplitSource(maxOutstandingSplits, hiveSplitLoader, executor);
hiveSplitLoader.start(splitSource);
return splitSource;我们可以看到这里启动了一个BackgroundHiveSplitLoader,它也是HiveSplitSource的构造函数参数,最后返回了splitSource。
小结一下,planDistribution主要做的事情就是生成SplitSource,以及为各个StageExecutionPlan对象建立dependency连接。
SqlQueryScheduler#start
Presto中一个Query的执行用的是动态调度,即任务是一批一批地调度出去让各个Worker里的Task去执行的。这点和Impala不同,Impala使用的是静态调度,即Query在分布式执行前已经算好了每个FragmentInstance(对应Presto里的Task)要处理的split,具体可参见 Impala源码阅读——SimpleScheduler。
SqlQueryScheduler#start顾名思义就是开始动态调度,从而query也就能开始执行。start函数很简单:
public void start()
{
if (started.compareAndSet(false, true)) {
executor.submit(this::schedule);
}
}这是用的java8的lambda语法,即住线程池里提交一个运行自己的schedule函数的线程。schedule函数比较长,这里就不贴了,最重要的是这一行:
ScheduleResult result = stageSchedulers.get(stage.getStageId())
.schedule();
给定一个stageId,获得它的StageScheduler并调用其schedule函数。StageScheduler是一个接口,有三种实现:
- FixedCountSchedule
- FixedSourcePartitionedScheduler
- SourcePartitionedScheduler
跟TableScan相关的Stage只能是后两种,而FixedSourcePartitionedScheduler#schedule最终调的又是SourcePartitionedScheduler#schedule,因此我们只看第三个的schedule实现。这个函数非常重要,其实现可以概括如下:
// 获取一个FutureTask,其结果是一个List splitAssignment = splitPlacementResult.getAssignments();
// 分配Split到各个机器上
Set newTasks = assignSplits(splitAssignment); 我们最关注的是SplitSource#getNextBatch是怎么拿到Block Location信息的,但在分析它之前,我们先介绍完这个schedule函数的逻辑。函数最后调用的assignSplits函数接下来的调用堆栈是
SqlStageExecution#scheduleSplits(Node node, Multimap splits)
SqlStageExecution#scheduleTask
RemoteTask#start -> HttpRemoteTask#start 最终会从Coordinator端发出一个restful请求给Worker,让Worker去创建或更新Task(第一次发出请求会创建Task,后续主要更新Task需要新处理的Split,即调度一些新的split给Task)。
回到我们最关心的SplitSource#getNextBatch,hive对应的调用堆栈是
ConnectorAwareSplitSource#getNextBatch
HiveSplitSource#getNextBatch最后这个函数的代码很短,主体如下:
@Override
public CompletableFuture> getNextBatch(int maxSize) {
...
CompletableFuture> future = queue.getBatchAsync(maxSize);
...
return future;
} 这里的queue是一个AsyncQueue,看来这里是消费者部分,那么生产者在哪呢?
这个queue是private的,只有自己的函数能加数据。我们在HiveSplitSource里可以找到两个addToQueue函数,查找下是谁调用了它们,发现就是前面planDistribution部分启动的BackgroundHiveSplitLoader!因此这些FutureTask是在planDistribution阶段Visitor遍历到TableScan节点时就启动的了。
总结
Presto的query执行可以分为Plan和Schedule两个阶段。其中Plan阶段又可细分为四个阶段:
- 语义分析,这一步会获取Hive中的TableSchema。
- 生成逻辑计划,这一步会获取Hive中的Partition信息。
- 生成PlanFragment
- planDistribution:初始化获取Split(即File Metadata)的各种异步对象(SplitSource)
在Schedule阶段query开始真正执行,采用的是动态调度。每次从SplitSource里获取一批split然后调度出去。Split的获取是跟Schedule阶段并行进行的。