爬虫笔记21:页面等待以及当按钮不能被点击时的处理、selenium操作多个窗口、12306扫码登录
一、页面等待
为什么要等?
(1)selenium比较慢 网站打开了 元素没有加载出来
(2)现在的网页越来越多采用了 Ajax 技术,这样程序便不能确定何时某个元素完全加载出来了。如果实际页面等待时间过长导致某个dom元素还没出来,但是你的代码直接使用了这个WebElement,那么就会抛出NullPointer的异常。
如何解决?
(1) time.sleep(10) : Python提供的,import time,一定要等够10秒
(2) selenium也提供了页面等待的方式: 隐式等待(implicit)、显式等待(explicit)
隐式等待情况下,WebDriver 等待一定时间,该时间段内,如果特定元素没加载成功,则抛出异常。显式等待情况下,只有特定条件触发后,WebDriver 才会继续执行后续操作。
1、隐式等待:调用driver.implicitly_wait(10),它是一个设置,并且只针对findelement方法生效。
10秒内,如果特定元素没加载成功,则抛出异常。如果在第5秒特定元素已加载可用,就立即执行,不用再等。
案例1:
from selenium import webdriver
driver = webdriver.Chrome(r'C:\Users\01\Desktop\chromedriver.exe')
# 隐式等待
driver.get('https://www.baidu.com/')
driver.implicitly_wait(10000) #只要找到元素就立即执行
driver.find_element_by_id('kw').send_keys('python')
结果:(并未等待10000秒)

案例2:
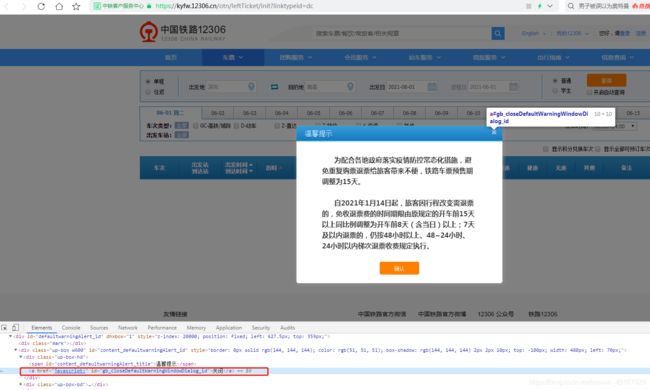
from selenium import webdriver
driver = webdriver.Chrome(r'C:\Users\01\Desktop\chromedriver.exe')
driver.get('https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc')
driver.implicitly_wait(10000)
# 千万不要忘记click() 这一步是去掉那个提示框
driver.find_element_by_id('gb_closeDefaultWarningWindowDialog_id').click()
结果:(并未等待10000秒就把提示框给X掉了)
补充:当按钮不能被点击时的处理
from selenium import webdriver
driver = webdriver.Chrome(r'C:\Users\Administrator\Desktop\chromedriver_win32\chromedriver.exe')
driver.get('https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc')
driver.implicitly_wait(10000)
driver.find_element_by_id('gb_closeDefaultWarningWindowDialog_id').click()
btn = driver.find_element_by_id('query_ticket')
btn.click()
结果:
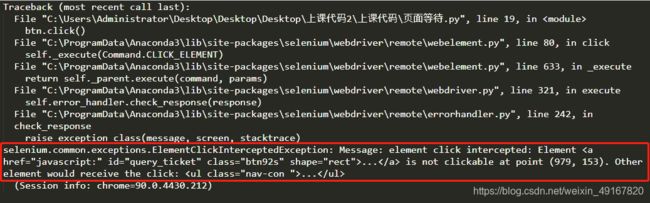
报错:selenium.common.exceptions.ElementClickInterceptedException: Message: element click intercepted: Element … is not clickable at point (979, 153). Other element would receive the click:
(element …在点(979,153)不可点击。其他元素将接收点击)
解决方法:driver.execute_script(‘arguments[0].click()’,btn)
备注:execute_script即执行Javascript语句,当按钮等需要被点击的对象被隐藏或者或者被覆盖或者说要下拉滚动条才出现该按钮时,就可以用这个方法。
from selenium import webdriver
driver = webdriver.Chrome(r'C:\Users\Administrator\Desktop\chromedriver_win32\chromedriver.exe')
driver.get('https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc')
driver.implicitly_wait(10000)
driver.find_element_by_id('gb_closeDefaultWarningWindowDialog_id').click()
btn = driver.find_element_by_id('query_ticket')
driver.execute_script('arguments[0].click()',btn)
结果:

2、显式等待:显式等待是表明某个条件成立后才执行获取元素的操作。也可以在等待的时候指定一个最大的时间,如果超过这个时间那么就抛出一个异常。显示等待使用selenium.webdriver.support.excepted_conditions期望的条件和selenium.webdriver.support.ui.WebDriverWait来配合完成。
比如等待页面某个元素加载成功:
WebDriverWait(driver,15).until(EC.presence_of_element_located((By.ID, “templateDiv”)))
案例:
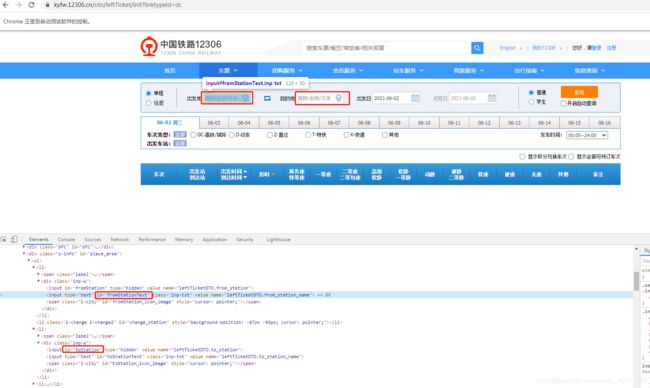
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome(r'C:\Users\Administrator\Desktop\chromedriver_win32\chromedriver.exe')
driver.get('https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc')
driver.implicitly_wait(10000)
driver.find_element_by_id('gb_closeDefaultWarningWindowDialog_id').click()
# 显式等待,等待出发地加载出来
WebDriverWait(driver,10000).until(
EC.text_to_be_present_in_element_value((By.ID,'fromStationText'),'北京')
)
# 显式等待,等待目的地加载出啦
WebDriverWait(driver,10000).until(
EC.text_to_be_present_in_element_value((By.ID,'toStationText'),'长沙')
)
btn = driver.find_element_by_id('query_ticket')
driver.execute_script('arguments[0].click()',btn)
结果:
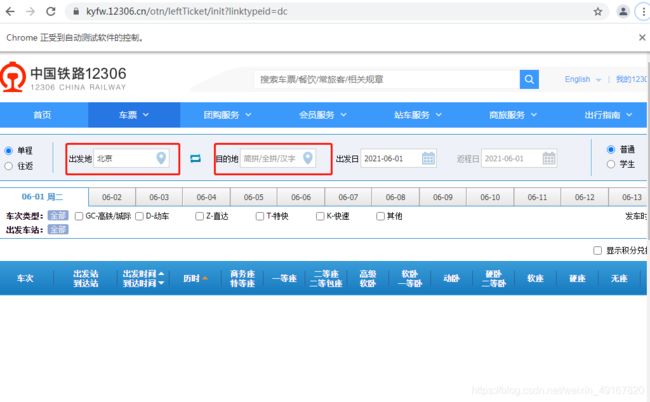
当手动输入北京、长沙后,页面显示出查询结果:

二、selenium操作多个窗口
from selenium import webdriver
driver = webdriver.Chrome(r'C:\Users\01\Desktop\chromedriver.exe')
driver.get('https://www.baidu.com/')
driver.get('https://www.douban.com/')
结果:从浏览器的流程上,我们可以看到,豆瓣把百度覆盖掉了。
那么要如何同时打开呢?
from selenium import webdriver
import time
driver = webdriver.Chrome(r’C:\Users\01\Desktop\chromedriver.exe’)
driver.get(‘https://www.baidu.com/’)
driver.execute_script(‘window.open(“https://www.douban.com/”)’)
结果:

1、driver.execute_script(‘window.open(“https://www.douban.com/”)’)的作用

从浏览器的流程上,我们可以看到:driver.execute_script(‘window.open(“https://www.douban.com/”)’)只是单纯的打开了豆瓣,但后续的操作跟豆瓣网页没有任何关系。
那么要如何才能对豆瓣网页进行操作呢?
2、driver.switch_to.window(driver.window_handles[2])的作用:切换当前窗口
from selenium import webdriver
import time
driver = webdriver.Chrome(r'C:\Users\01\Desktop\chromedriver.exe')
driver.get('https://www.baidu.com/')
driver.execute_script('window.open("https://www.douban.com/")')
time.sleep(2)
print(driver.current_url)
driver.switch_to.window(driver.window_handles[2])
time.sleep(3)
print(driver.current_url)
driver.close() #关闭了豆瓣
结果:

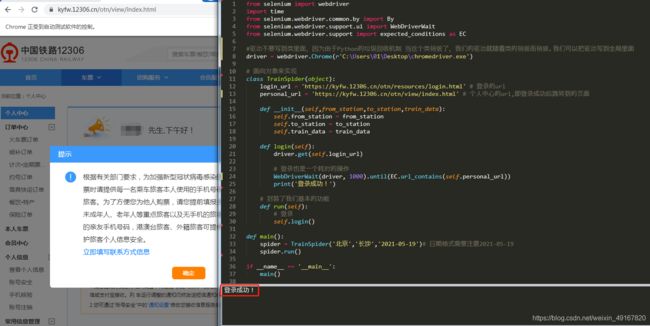
三、12306扫码登录
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#驱动不要写到类里面,因为由于Python的垃圾回收机制 当这个类销毁了,我们的驱动就随着类的销毁而销毁。我们可以把驱动写到全局里面
driver = webdriver.Chrome(r'C:\Users\01\Desktop\chromedriver.exe')
# 面向对象来实现
class TrainSpider(object):
login_url = 'https://kyfw.12306.cn/otn/resources/login.html' # 登录的url
personal_url = 'https://kyfw.12306.cn/otn/view/index.html' # 个人中心的url,即登录成功后跳转到的页面
def __init__(self,from_station,to_station,train_data):
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
def login(self):
driver.get(self.login_url)
# 登录也是一个耗时的操作
WebDriverWait(driver, 1000).until(EC.url_contains(self.personal_url))
print('登录成功!')
# 封装了我们基本的功能
def run(self):
# 登录
self.login()
def main():
spider = TrainSpider('北京','长沙','2021-05-19')# 日期格式需要注意2021-05-19
spider.run()
if __name__ == '__main__':
main()
结果: