【pytorch】pytorch学习笔记(续1)
p22:1.加减乘除:
(1)add(a,b):等同于a+b。
(2)sub(a,b):等同于a-b。
(3)mul(a,b):等同于a*b。
(4)div(a,b):等同于a/b。a//b表示整除。
2.tensor的矩阵式相乘:matmul
注意区分:(1)*:表示相同位置的元素相乘;(2).matmul:表示矩阵相乘。
对于(2)矩阵的相乘,有三种方式:
(1)torch.mm:只适用于二维的tensor,不推荐。
(2)torch.matmul:适用于2d,3d,4d... 推荐。该函数只是对后两维进行矩阵相乘,前面的维度不变。若前面的维度中两个tensor有不相同的维度,则还需要使用broadcasting。
(3)@:是torch.matmul的重载的符号形式,是一样的原理。
pytorch默认的rand函数的第一个维度表示输出的维度,第二个维度表示输入的维度。
3.矩阵的乘方运算:pow(a:表示要进行次方运算的tensor,2/3/4...)
pow函数的重载符号维**。
4.矩阵的次方根:
(1)tensor.sqrt():开平方根。也可以用**(1/2,1/4,...)表示。
(2)tensor.rsqrt():tensor.sqrt()的倒数。用到稍微少一点。
补:

log表示以1为底,以2为底用log2,以10为底用log10。
5.矩阵的近似运算:
(1).floor():向下取整。
(2).ceil():向上取整。
(3).round():四舍五入。
(4).trunc():裁剪,就是把tensor裁剪成整数部分和小数部分,返回整数部分。
(5).frac():小数。
(6).clamp(min[,max]):裁剪。用的比较多。
w.grad.norm(2):打印矩阵w的模,用的是L2范数,.grad返回的是梯度。模如果等于100,就说明梯度已经很大了,属于梯度爆炸。
.clamp(min):将tensor中小于min的都置为min。
.clamp(min,max):将tensor中小于min的都置为min,大于max的都置为max。
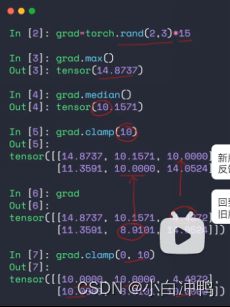
p23:1.范数:norm(1/2:表示做L1范数还是L2范数[,dim=0/1/...:表示在具体的某一个维度上做范数]):注意:norm != normalize。
L1范数:所有元素绝对值之和。L2范数:所有元素绝对值的平方和开根号。
2.均值:.mean()=.sum()/prod(.size)
3.累乘:.prod()
4.最大值:.max()
5.最小值:.min()
6.求和:.sum()
7.最大值的位置:.argmax([dim=0:表示在第0个维度上求最大值的索引])
8.最小值的位置:.argmin([dim=0:表示在第0个维度上求最小值的索引])
注意:argmax,argmin不带参数的话,会先把tensor打平成一维的,然后再返回最大最小值的索引。
p24:
9.dim:
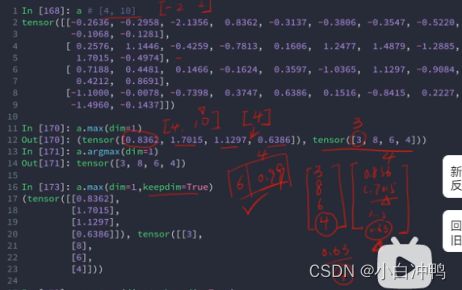
10.keepdim:保持dimension前后tensor的维度一致。因为dimension操作本来就会消掉维度。
11.top-k:.topk(k,dim=1,largest=True(最大的k个)/False(最小的k个)):返回最大或最小的k个。会返回比max或min更多的数据。
12.k-th:即第k个的值:kthvalue(k,dim=1):只能表示最小的,即k表示第k小的。
13.比较(对每一个元素进行比较):
pytorch中没有True和False,因此用0表示False,用1表示True。
.eq(a,a):返回的是tensor,表示每个元素是否相等,相等为1,不相等为0.
.equal(a,a):返回的是True/False,判断两个tensor中的元素是否完全一样,所有元素都相等则返回True,否则返回False。
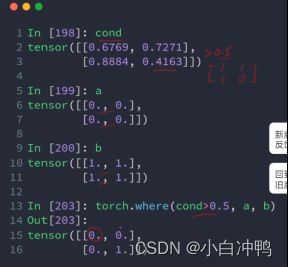
p25:1..where(condition,x:源头A,y:源头B):返回一个新的tensor。
condition、A、B的shape是一样的。

2..gather(input,dim,index,out=None):其实就是一个查表的过程。返回的是一个tensor。

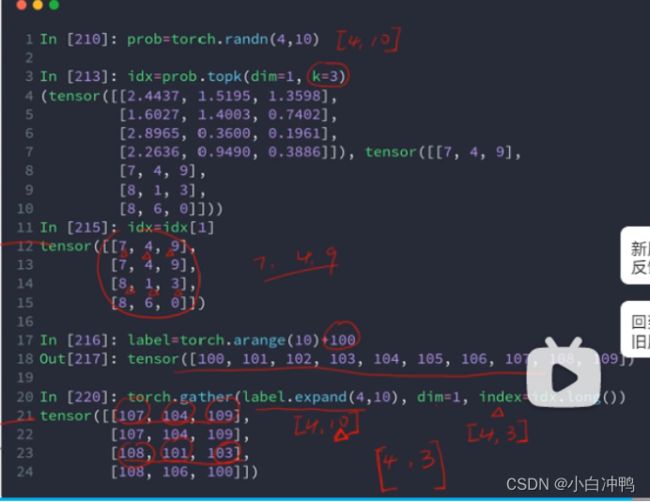
(问题)上图中第19行中label.expand(4,10),label是一个size是[10]的tensor,使用expand操作后就变成了[4,10]的tensor,expand操作当确实维度的时候可以在当前维度前面自动添加一个新维度并对其进行扩展吗?这不是broadcasting的功能吗?
p26:1.梯度是所有偏微分组成的一个向量。
2.函数的梯度是一个向量,这个向量的方向表示这个函数在当前点的增长方向,这个向量的模即长度代表了这个函数在当前这个点增长的一个速率。
3.如何利用梯度找到极小值点?

p27:何凯明:Res-Net
1.一个凸函数总是可以找到一个全局最优点。
2.鞍点:在某个点取到一个维度的极大值,取到另一个维度的极小值,这个点就叫做鞍点。
3.影响搜索过程的因素:
(1)局部极小点
(2)鞍点
(3)初始状态:一定要初始化,没有把握的话可以用凯明初始化方法。
(4)学习率:如果设置的很大的话,很有可能直接就不收敛了。所以在做的时候要把学习率设置的小一点,如0.001,0.01,如果收敛了,可以适当调大lr,较快速度;如果不收敛,九八lr变得再小一点点。lr会影响收敛的速度和精度。
(5)动量:利用惯性逃出局部极小值:
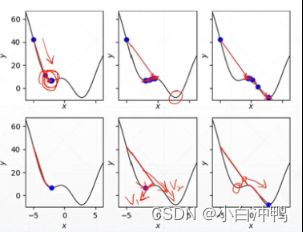
.......
p28:1.logx的底为e。
p29:1.激活函数:来源于青蛙神经元:多个输入经过神经元后输出的并不是一个简单的线性函数,而是有一个阈值,大于这个阈值才会给出响应,否则不会响应。由此推出最一开始的激活函数是一个阶梯函数,不可导。为解决不可导这一问题,提出了一下的激活函数:
(1)sigmoid/Logistic:光滑,相当于压缩的效果:会把负无穷到正无穷的数压缩到0和1之间。常用,如概率,RGB等。
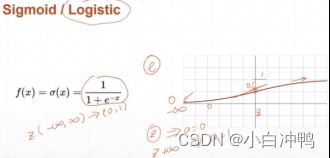

缺陷:x值接近于无穷大的时候,sigmoid函数的导数会非常接近于0,导致梯度下降参数长期不更新,这会导致梯度离散现象的出现。
pytorch实现:
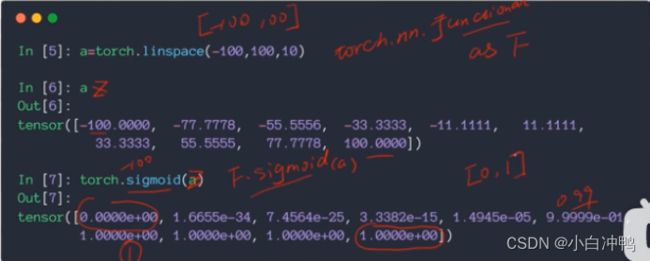
.linespace(start,end,count):从start到end划分成count个片段。
一种实现:torch.sigmoid(tensor):实现sigmoid函数的运算。
另一种是实现:F.sigmoid(tensor)。
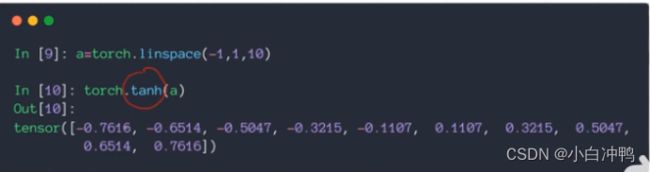
(2)tanh:在RNN中用的比较多。值在[-1,1]内。可以由sigmoid函数变换而来。

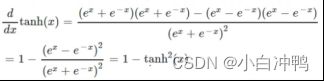
pytorch实现:
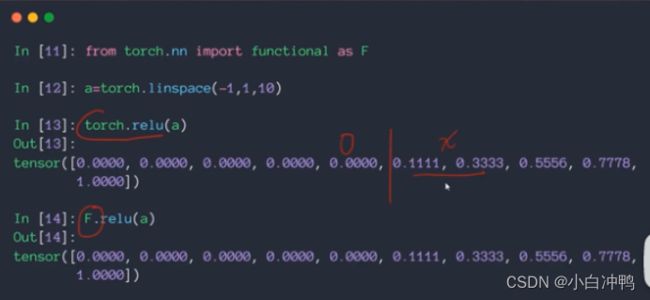
(3)ReLU

z=0时梯度为0,z>0时梯度为1,因此向后传播时梯度不会放大也不会缩小,计算简单,会保持梯度不变,这宴会很大程度上减少梯度离散和梯度爆炸的出现。
pytorch实现:
在做搜索的时候,优先使用ReLU函数,遇到特殊情况可以尝试一下其他函数。
(未完,待续~)