【pytorch】pytorch学习笔记(续3)
p41:1.Leak ReLU,SELU,softplus
2.GPU加速:.to方法

p42:不太懂
p43:1.visdom,tensorbroadX
p44:
p45:1.如何检测过拟合?在train上表现很好,而在test上表现不好。
test的目的(没有val set的时候):防止过拟合,选取最优参数。相当于是验证集。
一般选取test accuracy最高的那点停止训练,作为最优参数。

p46:1.train--validation--test
2.k折交叉验证法
把train分成k份,把k-1份作为train,1份作为val。
3.一般会把数据集划分为train和test,用train=True/False来区分是训练集还是测试集。
把数据集划分为train和test:
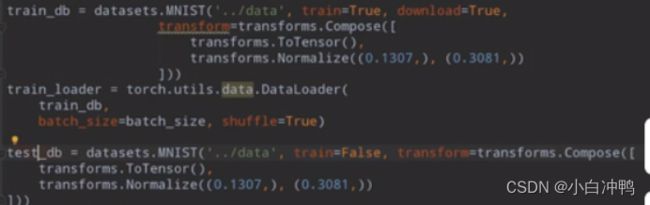
再把train划分为train和val:

p47:1.减轻overfitting的方法:
- 更多的数据;
(2)降低模型的复杂的:数据不是很多的时候模型不要很深,使用正则化;
(3)加droptout;
(4)进行数据增强;
(5)早停。
(本节课将正则化)
2.正则化(也叫权重衰减):对损失函数加正则项
正则项接近于0时,模型的复杂度会降低。 ?
因为对损失函数最小化的时候,不仅对原本的损失函数做了最小化,还对正则项做了最小化,从而使得模型的低微变量的参数相对较大,二高维变量的参数十分接近于0,这就会造成不仅使得模型的表现最优,还使得模型的复杂度得到了降低的效果,从而实现在不影响模型表现的情况下降低模型复杂度的目的。
3.常用的正则化分两种:
(1)在原损失函数上加一个1范数;

说明:pytorch没有提供直接的方法,所以需要人为的实现F1范数。
(2)在原损失函数上加一个2范数。(最常用)
pytorch实现:
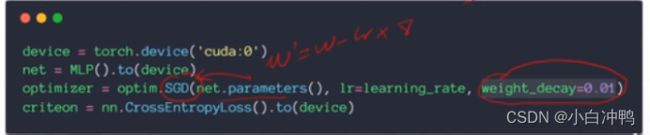
说明:1)SGD得到了网络的所有参数,设置一个weight_decay=0.01,即正则项中的![]() 参数。
参数。
2)如果模型没有overfitting,那么使用正则项会使得模型的表达能力急剧下降;但如果模型overfitting了,那么如果正则项参数设置合理的话,会在不影响模型表现的情况下降低模型的复杂度,减轻模型的overfitting,模型在测试集上的表现也会有所提升。
p48:1.动量(momentum惯性)

pytorch实现:
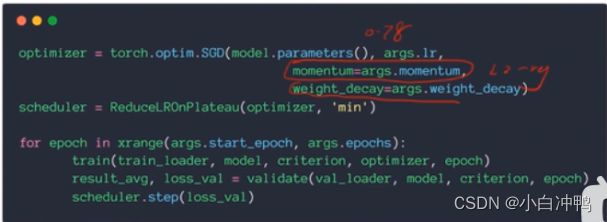
2.学习率衰减(learning rate decay):随着学习时间的推移,学习率逐渐变小,如:由0.1逐渐减小为0.001。
两种常见的学习率衰减的方案:
(1)当一定次数的loss不减小,就认为该学习率下已达到了最优,需要减小学习率了。
pytorch实现:

说明:optimizer的作用是把学习率丢给Plateau管理,’min’的作用是监听,监听一定次数的调用(epoch)loss是否达到饱和(即不再减小),若达到饱和则需要根据你的规则(乘0.5或者0.8...)来衰减学习率;若没有的话则什么都不做,只是记录一下。
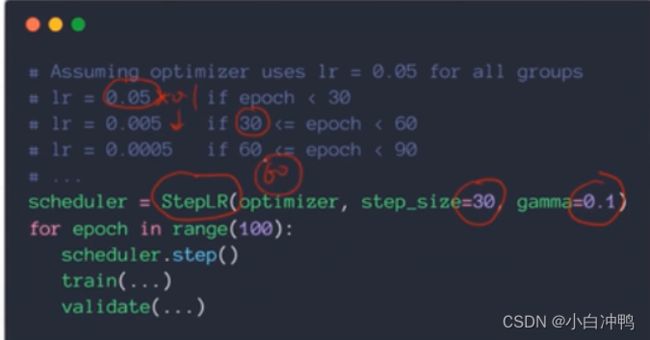
(2)规定每多少个(比如20k个)调用(epoch)衰减为原来的0.1或者...。
pytorch实现:
p49:1.早停
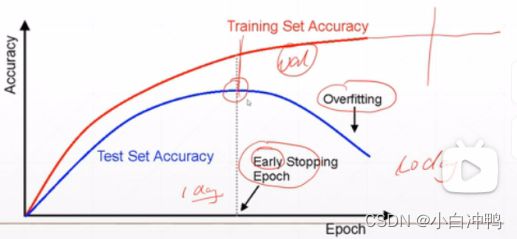
如何实现早停:
(1)用val set来选择参数;
(2)用val set来监测模型的表现;
(3)在val set表现的最高点(根据经验所得)提前停止训练模型。
2.dropout:迫使有效的w参数的数目越小越好
(1)如何实现:对每一个w(或者每一条边)定义一个额外的属性:probaiblity,即在前向传播中,每一条边都有一定的概率会输出为0,即把原本应输出为wx的输出为0,即把这条连接(即边)给断掉。这样会减少每次前向传播时的网络连接数量,训练时的参数数量会减少。
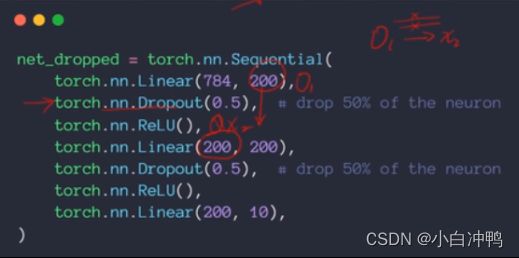
(2)pytorch实现:
可以在任何有需要连接的层之间加一个dropout层。不加dropout层的话,原来有连接的两层之间是一个直连,即前一层的输出就是后一层的输入。但加上dropout层之后,就会将两层之间的连接断掉一部分,即前一层的输出不能全部作为后一层的输入。
注意:(1)

torch中的p=dropout_prob,即连接断掉的概率,当p=1时连接都有可能被断掉,当p=0.01时连接被断掉的概率很小。
而nn里的是keep_prob,即连接保留的概率,当p=1时连接被断掉的概率很小,当p=0.01时连接被断掉的概率很大。
(2)dropout的行为在train和test的时候是不同的:在train的时候dropout会断掉部分连接,而在test的时候不会断掉连接。因此在validation的时候要手动的切换到test模式。

3.随机梯度下降(Stochastic Gradient Descent)
(1)Stochastic并不是random的意思,而是说具有一定的随机性。与Stochastic相反的是Deterministic:一一对应,而Stochastic是指给了一个x,f(x)是服从一个分布的,如0均值正态分布。
(2)这里Stochastic的意思是:从整个的数据集中随机的取出一个小部分样本来,如:从60k的数据集中取出一个128的batch来。
(3)随机梯度下降(Stochastic Gradient Descent):就是把原来在整个数据集上的梯度求和的平均变成了在一个batch上的所有梯度求和平均。
(4)为什么要使用随机梯度下降?因为目前的硬件设备容量不够,不可能一次性把所有的数据加载进来来计算,这样的话设备成本太高。
p50:1.(1)计算网络层数的时候,不把输入层计算在内。
(2)一层一般包括这一层的权值(和上一层的连接的权值)和输出。
2.卷积:模仿人眼的局部相关性,即一次观察一小块,(感受眼)
权值共享:用小窗口扫过整张图片,扫的过程中权值W是不变的。
只考虑局部相关的数据,不必全连接,大大减少了参数量。
卷积操作:小窗口与整张图片上对应大小的部分相乘再累加。
p53:1.kernal/weight/filter:[有几种kernal,输入里的通道数,kernal的长,kernal的宽]。
每一个kernal都会带一个偏值,偏值与kernal的第一个维度(即有几种kernal)是对应起来的。
p54:1.pytorch实现:

stride有降维的效果。
推荐使用实例调用方法,不推荐直接使用.forward()函数。
另一种实现方法:

pytorch中小写的是函数,大写的是类。——pytorch中的一个命名规范。
stride=2:size/2
padding=2:size+2
(未完,待续~)