JavaScript 引擎基础知识:形状(Shapes)和内联缓存(Inline Caches)
这篇文章描述了所有 JavaScript 引擎通用的一些关键基础知识,而不仅仅是 V8。作为一名 JavaScript 开发者,深入了解 JavaScript 引擎的工作原理有助于分析代码的性能特征。
JavaScript引擎工作流(The JavaScript engine pipeline)
起始于你编写的代码,js引擎解析源代码将其转换成抽象语法树(AST),然后,解释器(interpreter )根据抽象语法树生成字节码(bytecode),这个时候实际上就是引擎在运行JavaScript代码。为了运行的更快,字节码和分析数据(profiling data)会被一起发送给优化编译器,优化编译器根据分析数据做出某些假设,然后生成高度优化的机器代码;如果在某一时刻,某个假设被证明是错误的,优化编译器会取消优化并返回到解析器。
具体流程见下图:
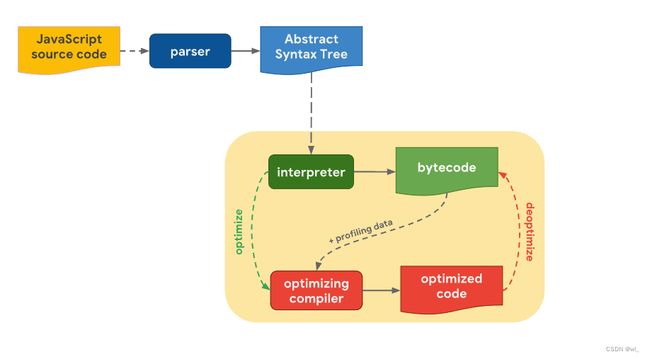
JavaScript引擎中的解释器/编译器管道流
让我们来看看JavaScript实际运行的部分,在这部分,JavaScript代码被解释和优化,同时也看一看各主流JavaScript引擎在这部分的差别。
一般来说,这部分都包含解释器和优化编译器,解释器快速生成未优化的字节码,优化编译器需要更长的时间,但它最终会生成高度优化的机器码。

通用的解释器/编译器管道流跟在Chrome和Node.js中使用的V8引擎采用的管道流差不多,如下:
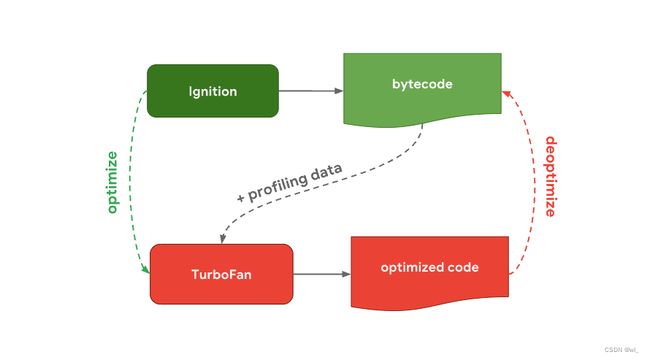 v8引擎中的解释/编译流程
v8引擎中的解释/编译流程
在V8引擎中,解释器被叫作Ignition(点火装置),负责生成和执行字节码,当它运行字节码时,它会收集分析数据用来提升后面的执行速度。当一个函数变得热门(hot),比如它经常被运行,那么生成的字节码和分析数据会被传递给TurboFan(涡轮扇发动机),也就是我们的优化编译器,然后根据分析数据生成高度优化的机器代码。
Mozilla的引擎SpiderMonkey,在Firefox和SpiderNode中使用,它的处理方式有点不一样。它有两个优化编译器Baseline和IconMonkey。从解释器到Baseline编译器的优化会产生稍微优化的代码,结合运行时收集的分析数据IconMonkey编译器可以生成高度优化的代码。如果推测性优化失败,IonMonkey会回退到Baseline时的代码。
 SpiderMonkey引擎中的解释/编译流程
SpiderMonkey引擎中的解释/编译流程
在Edge和Node-ChakraCore使用的微软公司的Chara引擎也拥有非常相似的设定,它也有两个优化编译器。SimpleJIT (Just-In-Time编译器)生成轻度优化的代码; FullJIT结合分析数据生成重度优化的代码。
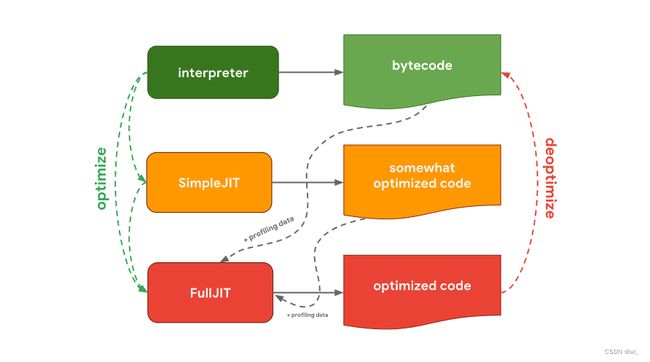 Chara引擎中的解释/编译流程
Chara引擎中的解释/编译流程
JavaScriptCore(简称JSC),苹果公司的引擎,在Safari和React Native中被使用。它使用了3个不同的优化编译器将这一过程做到了极致。从LLInt(低级解释器)到Baseline优化编译器,然后到DFG(Data Flow Graph)优化编译器,然后到FTL(Faster Than Light)优化编译器。
 JSC引擎中的解释/编译流程
JSC引擎中的解释/编译流程
为什么一些引擎比其他引擎有更多的优化编译器呢?这涉及到权衡。解释器可以快速生成字节码,但字节码通常效率不高。另一方面,优化编译器花费时间更长,但最终会生成更高效的机器代码。
因此,这里就存在是快速获取运行代码(解释器)还是花费更多时间来获得最佳性能运行代码(优化编译器)之间的权衡。
一些引擎以增加复杂性为代价,选择添加多个具有不同时间/效率特性的优化编译器,来对这些权衡进行更细粒度的控制。
另一个是与内存使用有关的权衡,详见这篇文章。
纵然这些主要的引擎有些差异,但在更高的层面上,这些JavaScript引擎都有着相同的架构:一个解析器(parser)和某种解释器/编译器工作流程。
JavaScript的对象模型(object model)
各JavaScript 引擎如何实现 JavaScript 对象模型,以及它们使用哪些技巧来加速访问JavaScript 对象上的属性呢?事实证明,各大引擎实现的方式非常相似。ECMAScript 规范本质上将所有对象定义为字典,字符串键映射到属性特性(数据属性和访问器属性)。

那么JavaScript是怎样定义数组的呢?其实我们可以将数组看成特殊的对象,
区别在于,数组需要对索引有特殊的处理。这里的数组索引是 ECMAScript 规范中的一个特殊术语。数组长度被限制不超过2³²−1,所以数组最大的有效索引是2³²−2。
另一个区别是数组拥有length属性,数组元素的增加会自动更新length的value。
优化属性的访问
纵观 JavaScript 程序,访问属性是最常见的操作, 因此,对于 JavaScript 引擎来说,快速访问属性是至关重要的。
形状(Shapes)
在JavaScript程序中,多个不同的对象拥有相同的属性是一种常见的现象,我们称这样的对象拥有相同的形状(shape)。
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
// `object1` and `object2` have the same shape.访问具有相同形状对象的相同属性也很常见:
function logX(object) {
console.log(object.x);
// ^^^^^^^^
}
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
logX(object1);
logX(object2);考虑到这一点,JavaScript引擎可以根据对象的形状优化对象属性访问。
假设有如下对象:

如果访问一个属性,比如object.y,JavaScript引擎会去JSObject中查找'y',加载对应的attributes,最终返回:[[Value]]。
但是,这些attributes存储在内存的什么地方呢?我们应该将它们作为JSObject的一部分么?但是,如果程序中存在很多相同形状的对象,重复存储多份相同的属性名会造成内存的浪费。所以,引擎通过把形状(Shape)分开存储来优化这一问题。

Shape中包含所有属性名和attributes,attributes中不包括[[Value]],增加了JSObject中值的偏移量Offset。拥有相同形状的对象指向同一Shape实例:

当我们有多个对象时,优势变得清晰可见。无论有多少个对象,只要它们具有相同的形状,我们只需要将它们的形状与键值属性信息存储一次!
所有的JavaScript 引擎都使用了Shapes作为优化,但称呼各有不同:
- 学术论文称它们为 Hidden Classes(容易与 JavaScript 中的类概念混淆)
- V8 将它们称为 Maps(容易与 JavaScript 中的 Map 概念混淆)
- Chakra 将它们称为 Types(容易与 JavaScript 中的动态类型和关键字 typeof 混淆)
- JavaScriptCore 称它们为 Structures
- SpiderMonkey 称他们为 Shapes
过度链与树(Transition chains and trees)
如果你有一个具有特定形状的对象,但你又向它添加了一个属性,此时会发生什么? JavaScript 引擎是如何找到这个新形状的?
const object = {};
object.x = 5;
object.y = 6;在 JavaScript 引擎中,shapes 的表现形式被称作 transition 链。以下展示一个示例:

该对象在初始化时没有任何属性,因此它指向一个空的 shape。下一个语句为该对象添加值为 5 的属性 “x”,所以 JavaScript 引擎转向一个包含属性 “x” 的 Shape,并向 JSObject 的第一个偏移量为0处添加了一个值 5。 接下来一个语句添加了一个属性 'y',引擎便转向另一个包含 'x' 和 'y' 的 Shape,并将值 6 附加到 JSObject(位于偏移量 1 处)。
我们甚至不需要为每个 Shape 存储完整的属性表。相反,每个 Shape 只需要知道它引入的新属性。 例如在此例中,我们不必在最后一个 Shape 中存储关于 'x' 的信息,因为它可以在更早的链上被找到。要做到这一点,每一个 Shape 都会与其之前的 Shape 相连:
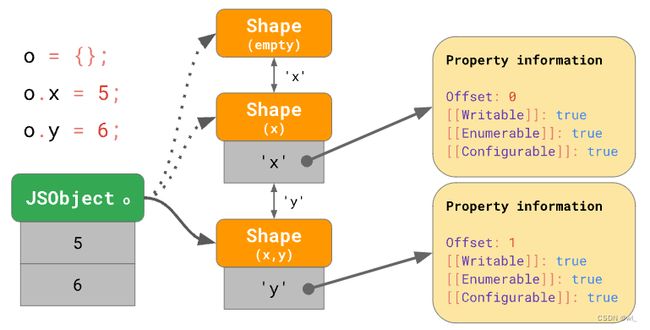
如果你在JavaScript 代码中写到了o.x,则 JavaScript 引擎会沿着 transition 链去查找属性 “x”,直到找到引入属性 “x”的 Shape。
但是,如果不能只创建一个transition 链呢?例如,如果你有两个空对象,并且你为每个对象都添加了一个不同的属性?
const object1 = {};
object1.x = 5;
const object2 = {};
object2.y = 6;在这种情况下我们便必须进行分支操作,此时我们最终会得到一个 transition 树 而不是 transition 链:

在这里,我们创建一个空对象 a,然后为它添加一个属性 'x'。 我们最终得到一个包含单个值的 JSObject,以及两个 Shapes:空 Shape 和仅包含属性 x的 Shape。
第二个例子也是从一个空对象 b 开始的,但之后被添加了一个不同的属性 'y'。我们最终形成两个 shape 链,总共是三个 shape。
这是否意味着我们总是需要从空 shape 开始呢? 并不是。引擎对已包含属性的对象字面量会应用一些优化。比方说,我们要么从空对象字面量开始添加 x 属性,要么有一个已经包含属性 x 的对象字面量:
const object1 = {};
object1.x = 5;
const object2 = { x: 6 };在第一个例子中,我们从空 shape 开始,然后转向包含 x 的 shape,这正如我们我们之前所见。
在 object2 一例中,直接生成具有属性 x 的对象是有意义的,而不是从空对象开始然后进行 transition 连接。

包含属性 'x' 的对象字面量从包含 'x' 的 shape 开始,可以有效地跳过空的 shape。(至少)V8 和 SpiderMonkey 正是这么做的。这种优化缩短了transition链,并使得从字面量构造对象更加高效。
那么,假如有一个空对象,然后陆续添加很多属性:
const point = {};
point.x = 4;
point.y = 5;
point.z = 6;
...会形成如下的一个Shape链:
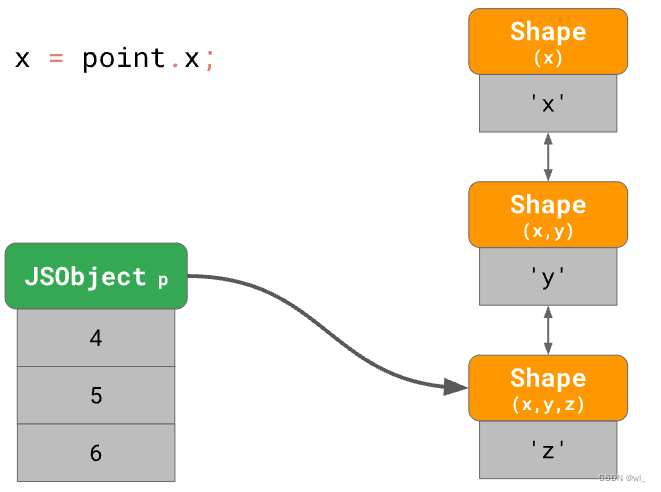
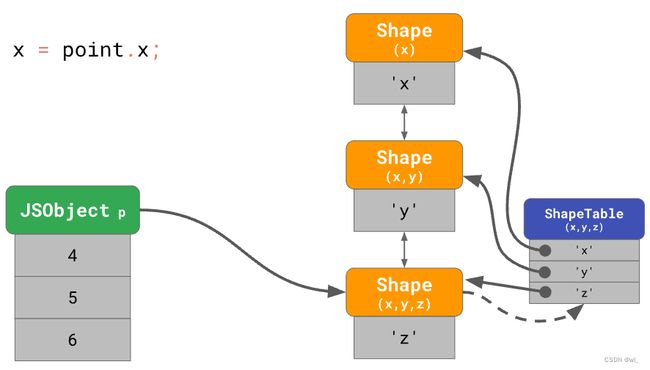
这个时候再访问x属性,就会从链的底部找到顶部,如果我们经常这样操作就会很慢,特别是当对象有大量属性时,时间复杂度为o(n)。JavaScript引擎通过添加字典数据结构ShapeTable来优化这个问题,ShapeTable建立了属性名和对应Shape之间的映射。
Inline Caches(ICs)
Shapes背后的主要动机是Inline Caches 或 ICs 的概念。ICs 是促使 JavaScript 快速运行的关键因素!JavaScript 引擎利用 ICs 来记忆去哪里寻找对象属性的信息,以减少昂贵的查找次数。
这里有一个函数 getX,它接受一个对象并从中取出属性 x 的值:
function getX(o) {
return o.x;
}如果我们在 JSC 中执行这个函数,它会生成如下字节码:
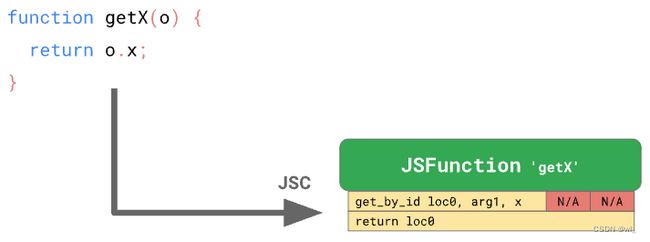
指令一 get_by_id 从第一个参数(arg1)中加载属性 'x' 值并将其存储到地址 loc0 中。 第二条指令返回我们存储到 loc0 中的内容。
JSC 还在get_by_id指令中嵌入了Inline Cache,它由两个未初始化的插槽组成。
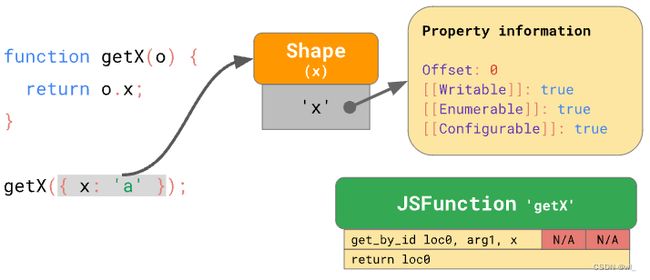
现在让我们假设我们用对象 {x:'a'} 调用 getX 函数。正如我们所知,这个对象有一个包含属性 'x' 的 Shape,该 Shape 存储了属性 x 的偏移量和其他特性。当你第一次执行该函数时,get_by_id 指令将查找属性 'x',然后发现其值存储在偏移量0处。
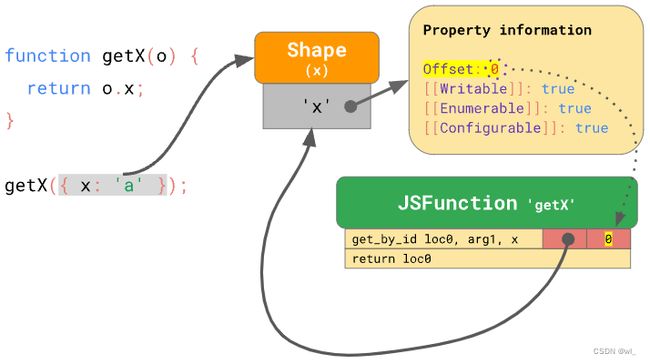
嵌入到 get_by_id 指令中的 IC 存储该属性的 shape 和偏移量:
对于后续运行,IC 只需要对比 shape,如果它与以前相同,只需从记忆的偏移量处加载该属性值。具体来说,如果 JavaScript 引擎看到一个对象的 shape 之前被 IC 记录过,它则不再需要接触属性信息——而是完全可以跳过昂贵的属性信息查找(过程)。这比每次查找属性要快得多。
高效存储数组
对于数组来说,存储属性诸如数组索引等是非常常见的。这些属性的值被称为数组元素。存储每个数组中的每个数组元素的属性特性(property attributes)将是一种很浪费的存储方式。相反,由于数组索引默认属性是可写的、可枚举的并且可以配置的,JavaScript 引擎利用这一点,将数组元素与其他命名属性分开存储。
考虑这个数组:
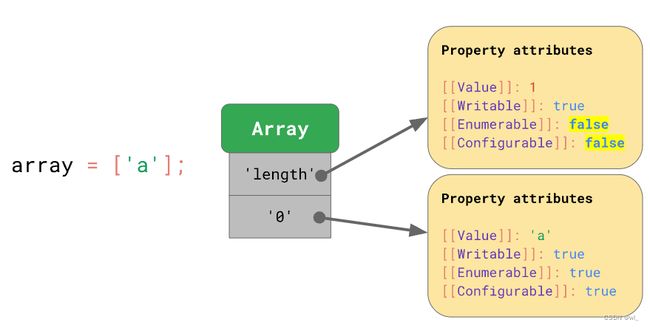
const array = [
'#jsconfeu',
];引擎存储了数组长度(1),并指向包含 offset 和 'length' 特性属性的 Shape。
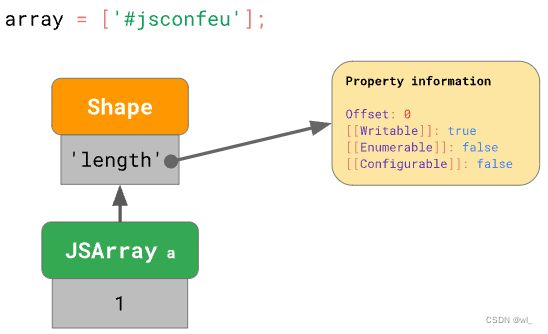
这与我们之前见过的类似, 但数组值存储在哪里呢?

每个数组都有一个单独的 elements backing store,其中包含所有数组索引的属性值。JavaScript 引擎不必为数组元素存储任何属性特性,因为它们通常都是可写的,可枚举的以及可配置的。
那么如果不是通常的情况呢?如果更改了数组元素的属性,该怎么办?
// Please don’t ever do this! 请永远不要这样做
const array = Object.defineProperty(
[],
'0',
{
value: 'Oh noes!!1',
writable: false,
enumerable: false,
configurable: false,
}
);上面的代码片段定义了一个名为 '0' 的属性(这恰好是一个数组索引),但其特性(value)被设置为了一个非默认值。
在这种边缘情况下,JavaScript 引擎会将全部的 elements backing store 表示为一个由数组下标映射到属性特性的字典。

即使只有一个数组元素具有非默认属性,整个数组的 backing store 处理也会进入这种缓慢而低效的模式。 避免在数组索引上使用 Object.defineProperty! (我不知道为什么你会想这样做。这看上去似乎是一个奇怪的且毫无价值的事情。)
总结
我们已经学习了JavaScript 引擎是如何存储对象和数组的,以及 Shapes 和 IC 是如何优化针对它们的常见操作的。基于这些知识,我们确定了一些有助于提升性能的实用 JavaScript 编码技巧:
- 始终以相同的方式初始化对象,以确保不会产生不同的Shapes。
- 不要设置数组元素的属性特性(property attributes),以确保可以高效地存储和操作它们。