生成对抗网络
目录
1.GAN的网络组成
2.损失函数解释说明
2.1 BCEloss
2.2整体代码
1.GAN的网络组成
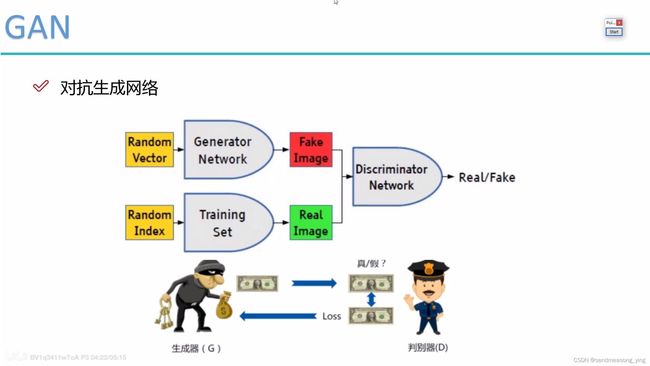
2.损失函数解释说明
2.1 BCEloss
损失函数

import torch
from torch import autograd
input =autograd.Variable(torch.tensor([[1.9072,1.1079,1.4906],
[-0.6584,-0.0512,0.7608],
[-0.0614,0.6583,0.1095]]),requires_grad=True)
#Variable已经被放弃使用了,因为tensor自己已经支持自动求导的功能了,只要把requires_grad
#属性设置成True就可以
print(input)
print('-'*100)
"""结果输出:
tensor([[ 1.9072, 1.1079, 1.4906],
[-0.6584, -0.0512, 0.7608],
[-0.0614, 0.6583, 0.1095]], requires_grad=True)"""
from torch import nn
m=nn.Sigmoid()
#开始有正有负的矩阵变成了0-1之间的正数
print(m(input))
print('-'*100)
"""结果输出:
tensor([[0.8707, 0.7517, 0.8162],
[0.3411, 0.4872, 0.6815],
[0.4847, 0.6589, 0.5273]], grad_fn=)"""
target=torch.FloatTensor([[0,1,1],[1,1,1],[0,0,0]])
#将变量转化为浮点型32位,这里注意此时的变量类型为列表,或数组等,此时参数为单个变量
print(target)
print('-'*100)
"""结果输出:
tensor([[0., 1., 1.],
[1., 1., 1.],
[0., 0., 0.]])"""
X=X.flatten()
target=target.flatten()
print(X)
print(target)
print('-'*100)
"""结果输出:
tensor([0.8707, 0.7517, 0.8162, 0.3411, 0.4872, 0.6815, 0.4847, 0.6589, 0.5273],
grad_fn=)
tensor([0., 1., 1., 1., 1., 1., 0., 0., 0.])"""
z=list(zip(target,X))
print(z)
print('-'*100)
"""结果输出:
[(tensor(0.), tensor(0.8707, grad_fn=)), (tensor(1.), tensor(0.7517,
grad_fn=)), (tensor(1.), tensor(0.8162, grad_fn=)),
(tensor(1.), tensor(0.3411, grad_fn=)), (tensor(1.), tensor(0.4872,
grad_fn=)), (tensor(1.), tensor(0.6815, grad_fn=)),
(tensor(0.), tensor(0.4847, grad_fn=)), (tensor(0.), tensor(0.6589,
grad_fn=)), (tensor(0.), tensor(0.5273, grad_fn=))]"""
result=[]
for (a,b) in z:
result.append(a*math.log(b)+(1-a)*math.log(1-b))
#a*math.log(b)就是预测正确的类别数,(1-a)*math.log(1-b)就是预测错误的类别数
result=torch.tensor(result)
r=result.reshape(3,3)
print(r)
print('-'*100)
"""结果输出:
tensor([[-2.0457, -0.2854, -0.2031],
[-1.0756, -0.7191, -0.3834],
[-0.6629, -1.0755, -0.7494]])"""
s=[]
for line in r:
s.append(-(sum(line)/3))
print(s)
"""结果输出:
[tensor(0.8447), tensor(0.7260), tensor(0.8293)]
"""
bceloss=torch.tensor(s).sum()/3
print(bceloss)
"""结果输出:
tensor(0.8000)
"""
#以上是手动计算BCELoss的结果
下面是应用那nn.BCELoss和nn.BCEWithLogitsLoss的运算结果,和手动计算的结果一致。
他们两个函数的区别就是对输入做的变换不同,nn.BCELoss需要对输入做sigmoid()使输入变成[0,1]区间的数。而nn.BCEWithLogitsLoss()则是内嵌了sigmoid()操作。
import torch
from torch import nn
input =torch.tensor([[1.9072,1.1079,1.4906],
[-0.6584,-0.0512,0.7608],
[-0.0614,0.6583,0.1095]],requires_grad=True)
#Variable已经被放弃使用了,因为tensor自己已经支持自动求导的功能了,只要把requires_grad
#属性设置成True就可以
print(input)
print('-'*100)
m=nn.Sigmoid()
#开始有正有负的矩阵变成了0-1之间的正数
print(m(input))
print('-'*100)
target=torch.FloatTensor([[0,1,1],[1,1,1],[0,0,0]])
#将变量转化为浮点型32位,这里注意此时的变量类型为列表,或数组等,此时参数为单个变量
print(target)
print('-'*100)
loss=nn.BCELoss()
print(loss(m(input),target))
print('-'*100)
#nn.BCEWithLogitsLoss()此损失函数将 Sigmoid 层和 BCELoss 整合在一起
loss=nn.BCEWithLogitsLoss()
print(loss(input,target))
"""结果输出:
tensor([[ 1.9072, 1.1079, 1.4906],
[-0.6584, -0.0512, 0.7608],
[-0.0614, 0.6583, 0.1095]], requires_grad=True)
------------------------------------------------------------------------
tensor([[0.8707, 0.7517, 0.8162],
[0.3411, 0.4872, 0.6815],
[0.4847, 0.6589, 0.5273]], grad_fn=)
---------------------------------------------------------------------------
tensor([[0., 1., 1.],
[1., 1., 1.],
[0., 0., 0.]])
----------------------------------------------------------------------------
tensor(0.8000, grad_fn=)
----------------------------------------------------------------------------
tensor(0.8000, grad_fn=)
"""
PyTorch的Variable已经不需要用了!!!_rom torch.autograd import variable-CSDN博客
Pytorch数据类型转换(torch.tensor,torch.FloatTensor)_torch改变数据类型-CSDN博客
Pytorch常用损失函数nn.BCEloss();nn.BCEWithLogitsLoss();nn.CrossEntropyLoss();nn.L1Loss(); nn.MSELoss();_nn.bcewithlogitsloss(reduction="none")-CSDN博客
2.2整体代码
import argparse
import torch
import torch.nn as nn
import numpy as np
import os
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.utils import save_image
os.makedirs("images", exist_ok=True)
# makedirs()方法是递归目录创建功能。如果exists_ok为False(默认值),则如果目标目录
# 已存在,则引发OSError错误,True则不会
parser = argparse.ArgumentParser()
# 创建一个 ArgumentParser 对象,该对象包含将命令行输入内容解析成 Python 数据的过程所
# 需的全部功能。
parser.add_argument("--n_epochs", type=int, default=100, help="number of epochs of training")
# 添加需要输入的命令行参数,()中依次为参数名;参数类型,声明这个参数的数据类型为int
# 为了参与运算,默认数据类型为str;描述信息。参数名--n_epochs,类型为int,默认等于100
# 含义是用于训练的次数
parser.add_argument("--batch_size", type=int, default=128, help="size of the batches")
# 参数是批量大小,类型为int,默认批量大小为128,含义是批量大小
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
# 参数是学利率,默认是浮点型的0.0002,含义是Adam优化器的学习率
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
# b1是adam优化器的一阶衰减梯度动量,大小为0.5的浮点数,可以说是adam公式里的β1,通常取值为0.9
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
# b2是adam公式里的β2,大小为0.999的浮点数,通常β2取值为0.999
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
# --n_cpu是在批处理生成期间要使用的 CPU 线程数,默认为8的整数
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space ")
# latent_dim是潜空间的维数,有100维
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension ")
# img_siz是每张图片的尺寸,默认大小为28(28*28=784)
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
# --channels 是每张图片的通道数等于1
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
# sample_interval是图像示例之间的间隔等于400
opt = parser.parse_args()
# ArgumentParser 通过 parse_args() 方法解析参数,获取到命令行中输入的参数。存储到opt中
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
# 输入图像的大小是1个通道,28*28大小的图片
cuda = True if torch.cuda.is_available() else False
# 返回一个bool,指示CUDA当前是否可用。,如果可用就返回cuda=True,不可用就返回cuda=False
"""定义生成器"""
class Generator(nn.Module):
def __init__(self):
super().__init__()
def block(in_feat, out_feat, normalize=True):
# 输入是28*28=784个像素点
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
# 如果要批归一化处理
layers.append(nn.BatchNorm1d(out_feat, 0.8))
# 输入维度,也就是数据的特征维度等于out_feat,momentum等于0.8
# CLASStorch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1,
# affine=True, track_running_stats=True, device=None, dtype=None)
layers.append(nn.LeakyReLU(0.2, inplace=True))
# LeakyReLU与relu的区别就是LeakyReLU把负区间从0变为了一定斜率的直线,0.2表示负半轴
# 的斜率是0.2
return layers
self.model = nn.Sequential(
*block(opt.latent_dim,128,normalize=False),
# opt.latent_dim等于100,第一个块不需要批归一化
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
# np.prod默认是把所有元素相乘,还可以指定数组的轴相乘
# 这里也就是把输出变成了图片的像素点的大小即1*28*28=784
nn.Tanh())
# 将输出元素调整到区间(-1,1)内
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
# 输出应该是批量*1*28*28
return img
"""定义判别器"""
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.module = nn.Sequential(nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid())
# 最终的预测结果是0-1上的一个概率值,所以最后就只有1个结果
def forward(self, img):
img_flat = img.view(img.size(0), -1)
# 先弄成线性的
validity = self.module(img_flat)
return validity
"""定义损失函数"""
adversarial_loss = torch.nn.BCELoss()
"""实例化生成器和辨别器"""
generator =Generator()
discriminator = Discriminator()
"""使用GPU计算"""
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# 把网络和损失函数都移到GPU上
"""配置数据集"""
os.makedirs("./data/mnist", exist_ok=True)
# 创建多层目录,os.makedirs(name, mode=0o777, exist_ok=False),如果exist_ok为False(默认
# 值),则在目标目录已存在的情况下触发FileExistsError异常;如果exist_ok为True,则在目标目录
# 已存在的情况下不会触发FileExistsError异常。
dataloader = torch.utils.data.DataLoader(
# 将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch_size封装成Tensor
# ,后续只需要再包装成Variable即可作为模型的输入。
datasets.MNIST(
# train_dataset = datasets.MNIST(root='./MNIST',train=True,transform=data_tf,download=True)
# train=True 代表我们读入的数据作为训练集(如果为true则从training.pt创建数据集,否则从
# test.pt创建数据集)。transform则是读入我们自己定义的数据预处理操作,download=True则是
# 当我们的根目录(root)下没有数据集时,便自动下载。
"./data/mnist",
train=True,
download=True,
transform=transforms.Compose(
# torchvision.transforms是pytorch中的图像预处理包。一般用Compose把多个步骤整合到一起
[transforms.Resize(opt.img_size),
# 把给定的图片resize到given size
transforms.ToTensor(),
# transforms.ToTensor()函数的作用是将原始的PILImage格式或者numpy.array格式的数据格式化
# 为可被pytorch快速处理的张量类型。输入模式为(L、LA、P、I、F、RGB、YCbCr、RGBA、CMYK、1)
# 的PIL Image 或 numpy.ndarray (形状为H x W x C)数据范围是[0, 255] 到一个
# Torch.FloatTensor,其形状 (C x H x W) 在 [0.0, 1.0] 范围内。
transforms.Normalize([0.5], [0.5])]),
# 逐channel的对图像进行标准化(均值变为0,标准差变为1),可以加快模型的收敛
# 将两个参数都设置为0.5并与transforms.ToTensor()一起使用可以使将数据强制缩放到[-1,1]区间上。
# ,参数是0.5是通过区间化公式计算得出的。标准化只能保证大部分数据在0附近——3σ原则)
),
batch_size=opt.batch_size,
shuffle=True)
"""指定优化器"""
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
"""训练"""
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
valid = Tensor(imgs.size(0), 1).fill_(1.0)
# torch.Tensor生成单精度浮点类型的张量。torch.tensor可以指定张量的类型。
# imgs.size(0)是图像的行数,有多少行就表示有多少个样本,然后指定样本的标签是1
# .fill_(1.0)将tensor中的所有值都填充为指定的1.0
fake = Tensor(imgs.size(0), 1).fill_(0.0)
# 真假标签的形状都是一个批量,把一个批量里面的标签填充成1或0
real_imgs = imgs.type(Tensor)
# 真实的图片转化为神经网络可以处理的变量
"""训练生成器"""
optimizer_G.zero_grad()
# 随机的初始化一个batch的向量
z = Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)))
# 这部分就是在上面训练生成网络的z的输入值,np.random.normal(0, 1, (imgs.shape[0],
# opt.latent_dim)的意思就是生成从0到1之间,形状为128*100的随机高斯数据,
# 随机高斯数据。imgs.shape[0]就是批量的个数,比如说imgs.shape[0]是128,就是每一批是
# 64张图片,后面的参数是100维,就是有这么多个特征
# 生成一批量的图片
gen_imgs = generator(z)
# 生成了一批就是128张图片
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
"""训练判别器"""
optimizer_D.zero_grad()
real_loss = adversarial_loss(discriminator(real_imgs), valid)
# 希望把真实的图片判断成正确的标号
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
# 希望把生成的数据判断成虚假的标号
d_loss = (real_loss + fake_loss) / 2
# 真假损失求和再求平均
d_loss.backward()
optimizer_D.step()
print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, opt.n_epochs,i, len(dataloader), d_loss.item(), g_loss.item()))
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
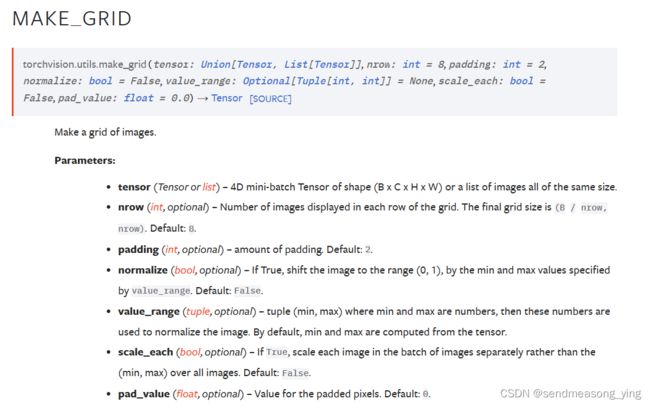
save_image(gen_imgs.data[:25], "images%d.png" % batches_done, nrows=5,normalize=True)
#nrow为大图片中每行所包含的小图片的个数,默认为8个,得到的大图片的形状为(B / nrow, nrow)。输入是#(B x C x H x W)B是批量大小,就是128,128/5等于25.6。一张图就有25张图片。normalize如果为 #True,则将图像移动到 value_range 指定的最小值和最大值 (0, 1) 范围内。

nn.BatchNorm讲解,nn.BatchNorm1d, nn.BatchNorm2d代码演示-CSDN博客
PyTorch学习笔记:nn.LeakyReLU——LeakyReLU激活函数-CSDN博客
Python 的np.prod函数详解-CSDN博客
python pytorch中 .view()函数讲解-CSDN博客
Pytorch的GPU计算(cuda)_net.cuda()-CSDN博客
Python os.makedirs详细介绍-CSDN博客
pytorch技巧 五: 自定义数据集 torch.utils.data.DataLoader 及Dataset的使用_pytorch torch.utils.data.dataloader dataset-CSDN博客
pytorch中的数据导入之DataLoader和Dataset的使用介绍_pytorch中训练数据集如何转变为dataset-CSDN博客
十分钟搞懂Pytorch如何读取MNIST数据集_pytorch读取mnist数据集-CSDN博客
transforms.Compose()函数-CSDN博客
数据归一化处理transforms.Normalize()-CSDN博客
torchvision.transforms.ToTensor详解 | 使用transforms.ToTensor()出现用户警告 | 图像的H W C 代表什么_torchvision.transforms.totensor()-CSDN博客
pytorch torchvision.transforms.Normalize()中的mean和std参数---解惑_x_normalized = (x - mean(x)) ./ std(x);矩阵维度不一致-CSDN博客
Pytorch(五)入门:DataLoader 和 Dataset_pytorch dataset dataloader-CSDN博客
pytorch 中 torch.optim.Adam 方法的使用和参数的解释-CSDN博客
Python-torch.optim优化算法理解之optim.Adam()_pytorch optim.adam-CSDN博客
torch.Tensor — PyTorch master documentation
torch.Tensor.fill_(value)方法_torch.fill-CSDN博客
详解激活函数(Sigmoid/Tanh/ReLU/Leaky ReLu等) - 知乎 (zhihu.com)
PyTorch学习笔记(20) ——激活函数_nn.hardtanh(0,4)-CSDN博客
PyTorch学习笔记(6)——DataLoader源代码剖析-CSDN博客
torchvision中datasets.MNIST介绍-CSDN博客
pytorch个人学习笔记(2)—Normalize()参数详解及用法_pytorch normalize-CSDN博客