python序列化--json
json
JS对象标记,描述对象使用
它基于 ECMAScript(欧洲计算机协会制定的js规范)的一个子子集,采用完全独立与编程语言的文本格式来存储和表示数据。如果我们需要在不同的编程语言之间进行数据交互,那么我们就得把数据(对象)序列化成标准格式,如 JSON格式、XML格式。
定义:
JSON(JS对象标记)是一种轻量级的数据交换格式,完全独立于编码语言的文本格式来存储和表示数据
原理:json通过标记记录内存中的对象,主要用来交换,以非内存方式标记记录二进制内存中的结构存下来
序列化:将内存中的对象转化为字节流或字符流的过程
注意: json的序列化不是二进制,而是字符,文本化数据,转化为字符
常用方法:
dumps json编码
dump json编码并存入文件
loads json解码
load json解码,从文件读取数据
json 模块
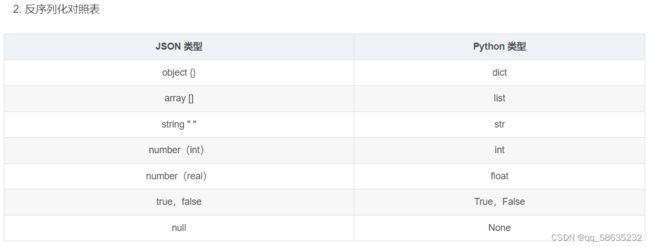
对于一种编程语言,要实现与其他语言之间的数据交互,就必须先把数据序列化成标准格式。在 Python 语言中,json 模块就是实现这样功能的一个模块。通过 json 模块中提供的方法,我们可以把数据在 JSON 类型和 Python 类型之间相互转化(即 在字符串和Python 数据类型之间转化),然后保存在文件中,从而实现打破平台和编程语言差异的数据交互。
Python支持少量内建数据类型到JSON类型的转换:
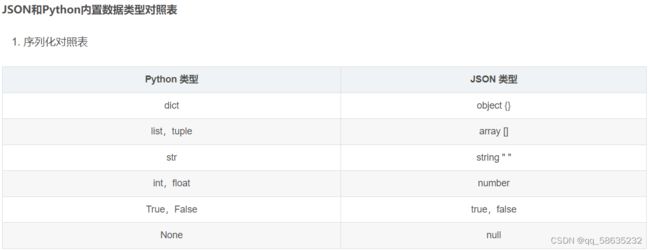
JSON 类型中,字符串使用双引号包裹的,不能用单引号;三个字面值(true,false,null)都是小写
json 数据类型:双引号引起来的字符串、数值、true和false、null、对象、数组,这些都是值
字符串:由双引号包围起来的任意字符的组合,可以有转义字符。
数值:有正负,有整数、浮点数。
对象:无序的键值对的集合
格式: {key1:value1, … ,keyn:valulen}
key必须是一个字符串,需要双引号包围这个字符串。
value可以是任意合法的值。
数组:有序的值的集合
格式:[val1,…,valn]
{
"person": [
{
"name": "tom",
"age": 18
},
{
"name": "jerry",
"age": 16
}
],
"total": 2 }
常用方法及解析
dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None,
indent=None, separators=None, default=None, sort_keys=False, **kw)
功能:将 obj 序列化为 JSON 格式的字符串,并保存到 fp 文件中
参数:
obj: 表示可被 JSON 格式序列化的对象
fp: 是一个支持 write() 方法的文件对象
sort_keys:如果 sort_keys 是 True(默认为 False),那么字典会以键的字典序保存在文件中。
skipkeys: 如果 skipkeys 是 True (默认为 False),那么那些不是基本对象(包括 str, int、float、bool、None)的字典的键会被跳过,否则引发一个 TypeError。
ensure_ascii: 如果 ensure_ascii 是 True (即默认值),则输出将保证把所有输入的非 ASCII 字符转义;如果 ensure_ascii 是 False,这些字符会原样输出。
check_circular: 如果 check_circular 是 False (默认为 True),那么容器类型的循环引用检验会被跳过并且循环引用会引发一个 OverflowError (或者更糟的情况)
allow_nan: 如果 allow_nan 是 False(默认为 True),那么在对严格 JSON 规格范围外的 float 类型值(nan、inf 和 -inf)进行序列化时会引发一个 ValueError。如果 allow_nan 是 true,则使用它们的 JavaScript 等价形式(NaN、Infinity 和 -Infinity)。
indent:如果 indent 是一个非负整数或者字符串,那么 JSON 数组元素和对象成员将以该缩进级别进行漂亮打印(在文件内)。如果缩进级别为 0、负数或空字符串,则只会插入换行符。 None 是最紧凑的表示形式。
default: default可以是一个函数(默认为 NOne),每当某个对象无法被序列化时它会被调用。它应该返回该对象的一个可以被 JSON 编码的版本或者引发一个 TypeError。如果没有被指定,则会直接引发 TypeError。
separators:表示分隔符,如果不为空,那么他应该是一个二元组:(item_separator, key_separator),两个元素分别表示键值对之间的分隔符和键和值之间的分隔符
cls:默认为空,可以是 JSONEncoder 的子类,该参数通过关键字参数来指定
返回值:None
dumps(obj,skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None,
separators=None, default=None, sort_keys=False, **kw)
功能:将 obj 序列化为 JSON 格式的字符串
参数:各参数的含义与 dump() 中的相同
返回值:一个字符串
说明:1、该方法会将包裹字符串的单引号换成双引号,因为 JSON 中的字符串被双引号包裹
2、如果 obj 具有非字符串的键,则 loads(dumps(obj)) != obj。因为 JSON 中的键值对中的键永远是 str 类型的,
当一个对象被转化为 JSON 时,字典中所有的键都会被强制转换为字符串。这所造成的结果是字典被转换为 JSON 然后转换回字典时可能和原来的不相等
load(fp, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
功能:将 fp 反序列化为 Python 对象。
参数:
fp:表示支持 .read() 方法的文件对象(包含 JSON 文档)
object_hook:这是一个可选函数,它会被调用于每一个解码出的对象字面量(即一个 dict)。object_hook 的返回值会取代原本的 dict。这一特性能够被用于实现自定义解码器
object_pairs_hook:与 object_hook 参数基本相同,但它是被有序列表解码的结果调用,如果它与 object_hook 同时被定义,则优先使用 object_pairs_hook
parse_int:可以是一个函数,如果指定了 parse_int,则将使用每个要解码的 JSON int 的字符串进行调用。 默认情况下,这等效于int(num_str)
parse_float:可以是一个函数,如果指定了 parse_float,将使用每个要解码的 JSON float 的字符串来调用。 默认情况下,这等效于float(num_str)
parse_constant:可以是一个函数,,如果指定了 parse_constant,将使用以下字符串之一调用它:'-Infinity','Infinity','NaN'。 如果遇到无效的JSON数字,则可以使用此方法引发异常。另,它不再在'null','true','false'上调用
cls:可以是 JSONDecoder 的子类,通过关键字参数指定
返回值:相应的对象
loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
功能:反序列化 s 到 Python 对象
参数:
s:表示一个包含 str, bytes或bytearray 对象的 JSON 文档(字符串)
其他参数的含义与 load() 中相同
返回值:相应的对象
说明:loads 不能识别单引号,如果 s 中包含单引号(如:s="{'k': '123'}"),就会抛出 JSONDecodeError 异常
常见异常:
JSONDecodeError:如果要反序列化的数据不是有效的JSON文档,则将引发 JSONDecodeError
序列化:将内存中的对象转化为字节流或字符流的过程
import json
d = dict(zip('abcde',[None, True, False,[1,'aaa'],{'a':1,'b':2}]))
s=json.dumps(d)
print(s,type(s))
反序列化:字节流或字符流转化为内存中的对象
d1 = """{"a": null, "b": true, "c": false, "d": [1, "aaa"], "e": {"a": 1, "b": 2}}"""
s1=json.loads(d1)
print(s,type(s1))
文件对象序列化
import json
filename = 'E:/testA'
d = dict(zip('abcde',[None, True, False,[1,'aaa'],{'a':1,'b':2}]))
with open(filename, 'w') as f:
json.dump(d, f)
with open(filename, 'r') as f:
a=json.load(f)
print(a,type(a))
一般json编码的数据很少落地,数据都是通过网络传输。传输的时候,要考虑压缩它。
本质上来说它就是个文本,就是个字符串。
json很简单,几乎编程语言都支持Json,所以应用范围十分广泛。
总结:
json 和 pickle 都是实现 Python 对象序列化和反序列化的模块,虽然他们都提供 dumps,dump,loads、load 四个功能,但两个模块之间存在根本上的差异。
json 与pickle 模块的差异:
JSON 是一种文本序列化格式,而 pickle 是一种二进制序列化格式。
JSON 是人类可读且易读的,而 pickle 人类不可读。
JSON 是可互操作的,且在 Python 生态环境之外被广泛使用。因为 JSON 表示出来就是一个字符串,可以被所有语言读取,通过 JSON,可以实现不同平台,不同编程语言之间的数据交互;
而 pickle 是特定于 Python 的。 模块实现了用于 Python 对象结构进行序列化和反序列化的二进制协议。通过 pickle 模块的序列化操作,我们能将程序中运行的对象层次结构转化成字节流,然后保存到二进制文件中去。
默认情况下,JSON 只能表示 Python 内置类型的子集,不能表示自定义类,而 pickle 表示大量的 Python 类型。
JSON 比 pickle 更安全