MySql索引的数据结构与算法
MySql索引的数据结构与算法
索引是帮助MySql高效获取数据的排好序的数据结构
索引数据结构
-
二叉树
-
红黑树
-
hash表
- 不支持范围查询,对 = 查询查询效率高
- 存储方式
- 进行哈希运算获取hash槽,然后将对应的数据存储在hash槽内
- 如果存在hash碰撞,将会在hash槽内生成一个链表,进行存户在后面,查找的时候会将当前槽内的数据全部取出来,然后查询.
-
B-Tree
- 叶子节点携带完整的数据结构,叶节点指针为空
- 所有索引元素不重复
- 节点中的索引从左到右自增
-
B+Tree
- 非叶子节点不存储数据,被称为冗余节点,可以存储更多的节点
- 叶子结点存储双向指针,指针指向前后节点地址,提高区间方位性能
- 叶子节点包含所有的索引字段
红黑树结构
当一边的结构过于深的时候会进行一次重排,让树结构相对来说平衡

二叉树 结构
如果数据为线性增长的数据则会变成单边树

B-Tree数据结构
叶节点具有相同的深度,叶节点指针为空,所有索引元素不重复,节点中的数据索引从左到右依次递增排列

B+Tree数据结构(Mysql使用的数据结构)
- B-Tree的变种,在非叶子结点不存储数据,值存储索引(冗余索引),可以放更多的索引
- 叶子节点包含所有的索引字段
- 叶子节点用指针连接,提高区间方位的性能
- 叶节点具有相同的深度
- 叶子节点的数据是大于等于父节点的
他解决了红黑树的高度不可控的问题

mysql为什么选择B+Tree不选择B-Tree?
因为B+Tree的索引结构决定的,B+Tree的非叶子节点不存储数据,这样在查找的时候load进入内存的时候能够load更多的索引,内存在load的时候只会一次load16KB的内容,如果飞叶子结点存储的数据就会导致占用更多的空间,B+Tree在飞叶子结点不存储数据,每个非叶子节点的索引为int类型的话,一个节点会占用8bit大小,下级非叶子索引占用的位置为6bit,这样的索引在load的时候一次大概会load的条数1170条,三层这样的结构会load大概2100万条,大大增加的查询效率,减少了磁盘IO,B+树指针
B-Tree树会在每一个节点下面存储数据,这样在检索load进入内存的时候数据也会被load进去,减少了索引的数量,如果是相同数量级别的表,深度会很深,大大增加了磁盘IO的次数
存储引擎
MyIsam存储引擎
frm:表结构 from
MYD:MyIsamData表内容
MYI:MyIsam Index 表索引
- 存储结构,数据库表解构(.frm),表内容(MYD),表索引(MYI)是分开存储的(非聚簇索引)
查找方式:
1:使用B+Tree的数据结构将索引load进入内存,
2:查找到指定索引(MYI),去找到对应的存储位置
3:通过对应的位置,去MYD表中取找对应的数据
InnerDB存储引擎
frm:表结构
idb:表数据和index索引的存储
- 表数据文本本身就是一个使用B+Tree维护的索引结构文件
- 聚集索引-叶子节点包含了完整的数据结构
- 建议维护一个整形自增的主键作为一个主键索引
- 为什么建议维护一个自增主键作为索引?
- 为什么维护一个主键作为索引?
- 如果不自己维护一个索引,那么InnerDB存储引擎会自己在内部进行维护一个主键索引,当做文件的索引
- 为什么需要一个自增的主键?
- 因为B+Tree维护的索引是一个有序的索引,如果在索引中间插入一些别的数据,会让索引重新排序,过程中还可能会产生分列,影响性能
- 为什么维护一个主键作为索引?
- 为什么建议维护一个自增主键作为索引?
- 为什么非主键索引结构叶子结点存储的是主键的值
- 1:存储主键的值,可以避免数据一致性,这样在新增数据的时候不需要在维护一份数据在非主键索引上
- 2:节省内存空间,不用存储完整的数据结构
- 会出现什么问题?
- 如果去查询非主键索引,会进行回表操作,当查询到非主键索引,会获取主键索引的下标,然后通过当前下标再次进入idb文件通过主键索引再次去查询数据
什么是联合索引?
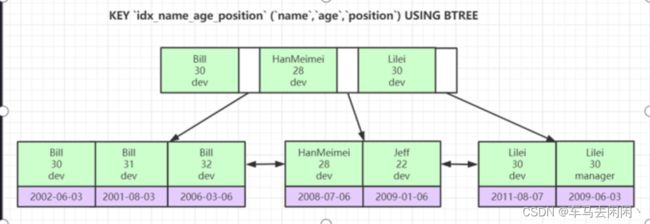
联合索引是多个索引组合在一起的索引,在进行查询的时候需要保证最左前缀原则!
例:
select * form table where name = “q” and age =“30”
select * form table where age =“30”
select * form table where age =“30” and position = “dev”
- 其中只有第一个会走索引,是因为保证了最左前缀原则
- 第二个查询和第三个查询为什么不会走索引?
- 因为B+Tree的索引进行了排序,name在最前面,他需要先对name进行排序,如果那么相同的情况下才会对age和position进行排序,
- 查找的时候如果直接进行查找第二个和第三个字段,就没办法通过排序进行查找数据,需要进行全表扫描,无法走索引
- 第二个查询和第三个查询为什么不会走索引?